CS 188 Project3(RL) Q1: Value Iteration
回忆一下值迭代的状态更新公式:
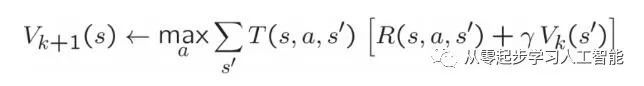
在ValueIterationAgent中编写一个值迭代代理,它在ValueIterationAgents.py中为您部分指定。您的价值迭代代理是一个离线计划,而不是强化学习代理,因此相关的训练选项是它在初始计划阶段应该运行的价值迭代的迭代次数(选项-i)。ValueIterationAgent在构造时接受MDP,并在构造函数返回之前为指定的迭代次数运行值迭代。
值迭代计算最优值的k阶估计,Vk除了运行值迭代之外,还可以使用Vk为ValueIterationAgent实现以下方法:
computeActionFromValues(State)根据self.values给出的值函数计算最佳操作。
computeQValueFromValues(state,action)返回self.values的value函数给出的(state,action)计算的Q-value值。
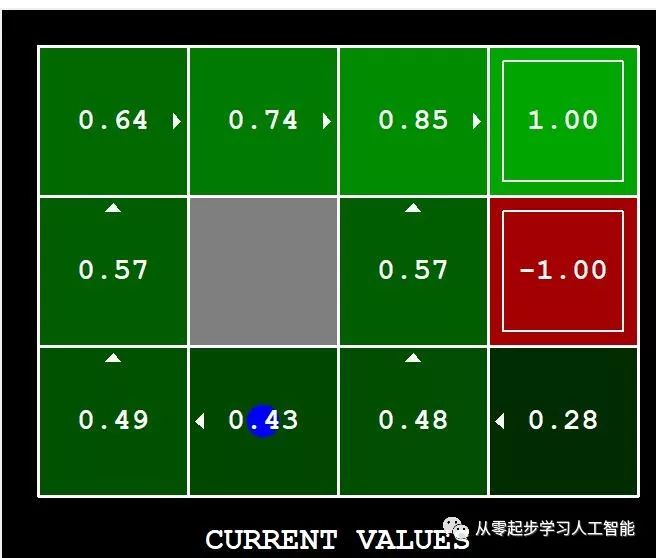
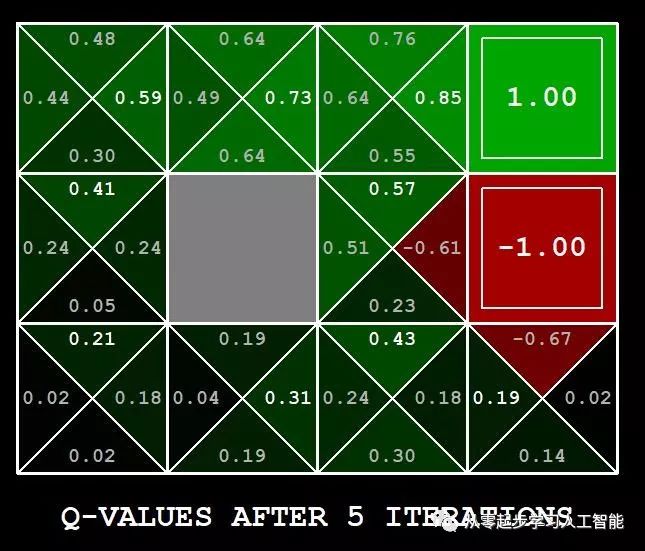
这些数量都显示在图形用户界面中:值是方格中的数字, Q-value是四分之一方格中的数字,策略是从每个方格中的向外箭头。
重要提示:使用值迭代的“批处理”版本,其中每个向量Vk是根据固定向量Vk-1计算的,而不是“在线”版本,其中一个单独的权重向量被更新。这意味着,当一个状态的值在迭代k中根据其后继状态的值进行更新时,值更新计算中使用的后继状态值应该是来自迭代k-1的值(即使某些后继状态已经在迭代k中更新)。Sutton和Barto在第4.1章第6段中讨论了这一区别。
注:根据深度k(反映下一个k奖励)的值合成的策略将实际反映下一个k+1奖励(即您返回πk+1)。同样,Q-values Q值也会比值多反映一个奖励(即返回Qk+1)。 您应该返回综合策略πk+1
提示:你可以使用util.py的util.Counter,Counter计数器是一个字典,默认值计数为零。然而,在argmax计算时需小心,你想要的argmax可能Key值不在计数器里面。
注意:当一个状态在MDP中没有可用的操作时,一定要处理这种情况(想想这对于将来的奖励意味着什么)。
下面的命令加载ValueIterationAgent,它将计算策略并执行10次。按一个键在values 值、Q值和模拟之间循环。您应该发现开始状态(v(start),您可以从GUI中读取)和经验结果的平均奖励(在执行完成10轮之后打印)的值非常接近。
Agent类代理必须定义getAction方法,也可以定义以下方法:registerInitialState检查启动状态。ValueEstimationAgent子类继承Agent类,ValueEstimationAgent子类是一个抽象类,为(状态、动作)的抽象代理环境分配一个Q-Values值。状态及策略分别表示如下:
V(s) = max_{a in actions} Q(s,a)
policy(s) = arg_max_{a in actions} Q(s,a)
valueIterationAgent和qLearningAgent都继承ValueEstimationAgent。当ValueIterationAgent具有基于马尔可夫决策过程的环境模型(mdp.py),它用于在实际行动之前估计Q-Values值,QLearningAgent代理在环境中行动时估计Q-Values值。ValueIterationAgent子类继承至ValueEstimationAgent,采用马尔可夫决策过程(参见mdp.py)初始化,使用提供的折扣系数对于给定的迭代次数运行值迭代。
Gridworld子类继承至mdp.MarkovDecisionProcess父类,MarkovDecisionProcess类的getStates方法返回MDP中所有状态的列表,一般不可能用于大型MDP;getStartState方法返回MDP的开始状态;getPossibleActions方法从“state”返回可能动作的列表;getTransitionStatesAndProbs方法返回(NextState,Prob)(下一个状态,概率)元组对的列表,代表采取“行动”从“状态”以及它们的转移概率可到达的状态。注意在Q-Learning 学习和强化学习中,我们不知道这些
概率,也不是我们直接建模的。getReward方法获得状态、动作和下一个状态转换的奖励。在强化学习中不可用。isTerminal方法中如果当前状态为终端状态,则返回true。按照惯例,终端状态0奖励。有时终端状态可能没有动作。终端状态自循环0奖励通过‘pass’,其公式是等价的。
Q值与V值的转换关系:例如,要计算下图最上面的三角形状态顶点S的V星值,需计算从状态s到每一个后续动作a的最大值maxQ*(s,a),而其中一个Q*(s,a)的计算是个概率计算,s的下一个动作a到达状态s'的概率是T(s,a,s'), 给予的奖励是R(s,a,s'),递归计算状态S’的V星值,r是折扣率(近期兑现的奖励高,远期兑现的奖励低),那么根据T(s,a,s')[(R(s,a,s'))+rV*(s')]计算出到到状态s'的值, 考虑到状态s到达其他s''的概率,同样进行计算并累加求和,计算出星值Q*(s,a); valueIterationAgents.py的runValueIteration方法实现了这个过程。

valueIterationAgents.py代码:
# valueIterationAgents.py
# -----------------------
# Licensing Information: You are free to use or extend these projects for
# educational purposes provided that (1) you do not distribute or publish
# solutions, (2) you retain this notice, and (3) you provide clear
# attribution to UC Berkeley, including a link to http://ai.berkeley.edu.
#
# Attribution Information: The Pacman AI projects were developed at UC Berkeley.
# The core projects and autograders were primarily created by John DeNero
# ([email protected]) and Dan Klein ([email protected]).
# Student side autograding was added by Brad Miller, Nick Hay, and
# Pieter Abbeel ([email protected]).
class ValueIterationAgent(ValueEstimationAgent):
"""
* Please read learningAgents.py before reading this.*
A ValueIterationAgent takes a Markov decision process
(see mdp.py) on initialization and runs value iteration
for a given number of iterations using the supplied
discount factor.
"""
def __init__(self, mdp, discount = 0.9, iterations = 100):
"""
Your value iteration agent should take an mdp on
construction, run the indicated number of iterations
and then act according to the resulting policy.
Some useful mdp methods you will use:
mdp.getStates()
mdp.getPossibleActions(state)
mdp.getTransitionStatesAndProbs(state, action)
mdp.getReward(state, action, nextState)
mdp.isTerminal(state)
"""
#mdp是一个GridWorld实例,GridWorld继承至MarkovDecisionProcess类
self.mdp = mdp
self.discount = discount
self.iterations = iterations
#values是一个基于状态Q-values的计数器,默认值为0
self.values = util.Counter() # A Counter is a dict with default 0
self.runValueIteration()
def runValueIteration(self):
# Write value iteration code here
"*** YOUR CODE HERE ***"
pass
#循环迭代的次数
for i in range(self.iterations):
#新建一个用于状态的计数器
valueForState = util.Counter()
#遍历获取马尔科夫链的所有状态(x,y),“#”墙不包括。
for state in self.mdp.getStates():
#在当前状态(x,y),新建一个用于动作的计数器
valuesForActions = util.Counter()
#获取这个状态(x,y)可能的动作'north','west','south','east','exit'
for action in self.mdp.getPossibleActions(state):
#在动作计数器中记录计算状态(x,y)执行下一个动作的Q-values
valuesForActions[action]=self.computeQValueFromValues(state,action)
#在状态(x,y)所有动作中取得最大的动作值,作为状态计数器的值。
valueForState[state] = valuesForActions[valuesForActions.argMax()]
#遍历马尔科夫链的状态集,给values赋值
for state in self.mdp.getStates():
self.values[state] = valueForState[state]
def getValue(self, state):
"""
Return the value of the state (computed in __init__).
"""
return self.values[state]
def computeQValueFromValues(self, state, action):
"""
Compute the Q-value of action in state from the
value function stored in self.values.
"""
"*** YOUR CODE HERE ***"
#util.raiseNotDefined()
pass
qValue = 0
#遍历当前状态(x,y)的下一个动作的各个方向可能概率
for transition in self.mdp.getTransitionStatesAndProbs(state,action):
#transition[1]是移动到(x,y)的概率,transition[0]是坐标(x,y),计算Q值
qValue = qValue + transition[1] * (self.mdp.getReward(state, action, transition[0]) + self.discount * self.values[transition[0]])
return qValue
def computeActionFromValues(self, state):
"""
The policy is the best action in the given state
according to the values currently stored in self.values.
You may break ties any way you see fit. Note that if
there are no legal actions, which is the case at the
terminal state, you should return None.
"""
"*** YOUR CODE HERE ***"
#util.raiseNotDefined()
#pass
#如果当前状态(x,y)下一个动作为空,则返回None
if len(self.mdp.getPossibleActions(state)) == 0:
return None
#新建一个动作的计数器
valuesForActions = util.Counter()
#遍历当前状态(x,y)的可能的动作集
for action in self.mdp.getPossibleActions(state):
valuesForActions[action]=self.computeQValueFromValues(state,action)
#返回最大值maxQ*(s,a)
return valuesForActions.argMax()
def getPolicy(self, state):
return self.computeActionFromValues(state)
def getAction(self, state):
"Returns the policy at the state (no exploration)."
return self.computeActionFromValues(state)
def getQValue(self, state, action):
return self.computeQValueFromValues(state, action)
欢迎关注微信公众号:“从零起步学习人工智能”。

喜欢我们发布的信息,就在右下角点一下“在看”吧!欢迎转发分享!