快讯 | Facebook开源语音识别工具包wav2letter

今日凌晨,Facebook AI研究中心宣布开源语音识别工具包wav2letter!这是一款简单高效的端到端自动语音识别(ASR)系统,wav2letter 实现的是论文 Wav2Letter: an End-to-End ConvNet-based Speech Recognition System 和 Letter-Based Speech Recognition with Gated ConvNets 中提出的架构。
16年11月,Facebook的三位研究者Ronan Collobert, Christian Puhrsch, Gabriel Synnaeve在arXiv.org上发布文章,正式提出了wav2letter。
文章中研究者介绍,这是一个简单的端到端语音识别模型,结合了基于卷积网络的声学模型和图解码。其被训练输出文字,转录语音,而无需强制对齐音素。wav2letter还引入了一个自动的序列标注训练分割准则,而不需要与CTC一致的对齐方式,这种方式更简单。
项目代码已经发布至GitHub,如果你想直接开始进行语音转录,你可以使用同时被开源的预训练好的一些模型,前提是完成必要的安装。当然,目前能识别的只有英文语音哦!
开源代码GitHub链接:
https://github.com/facebookresearch/wav2letter
论文arXiv链接:
https://arxiv.org/abs/1609.03193
Facebook也发布了公开信介绍这一开源项目,包括该项目主要负责人Ronan Collobert、Facebook AI研究中心负责人Yann Lecan等在内的研究者都在推特上介绍了这一发布。
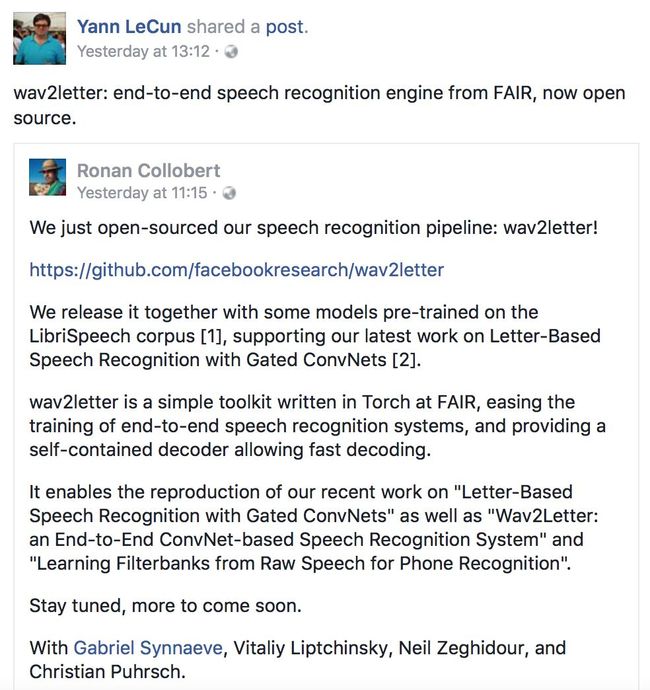
文摘菌摘录了部分公开信内容如下:
我们刚刚开源我们的语音识别工具:wav2letter!
代码地址:
https://github.com/facebookresearch/wav2letter
我们将其与在LibriSpeech语料库中预先训练的一些模型一起发布,支持我们的最新论文Letter-Based Speech Recognition with Gated ConvNets。
wav2letter是在Torch上编写的一个简单的工具包,简化了对端到端语音识别系统的训练,并提供了一个允许快速解码的独立解码器。
它使我们能够复现我们最近的3篇论文(详见参考资料)。
敬请期待我们的更多研究。
Gabriel Synnaeve,Vitaliy Liptchinsky,Neil Zeghidour和Christian Puhrsch。
更多参考资料:
语料库 LibriSpeech。
http://www.openslr.org/12
论文 Letter-Based Speech Recognition with Gated ConvNets。
https://arxiv.org/abs/1712.09444
论文 Wav2Letter: an End-to-End ConvNet-based Speech Recognition System。
https://arxiv.org/abs/1609.03193
论文 Learning Filterbanks from Raw Speech for Phone Recognition。
https://arxiv.org/abs/1711.01161

往期精彩文章
点击图片阅读
GPS脚环计步、AI“鸡”脸识别,如何确保自己吃到了一只幸福健康的鸡


