label smoothing pytorch版本
标签平滑的想法首先被提出用于训练 Inception-v2 [26]。它将真实概率的构造改成:
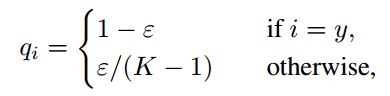
其中ε是一个小常数,K 是标签总数量。

图 4:ImageNet 上标签平滑效果的可视化。顶部:当增加ε时,目标类别与其它类别之间的理论差距减小。下图:最大预测与其它类别平均值之间差距的经验分布。很明显,通过标签平滑,分布中心处于理论值并具有较少的极端值。
# -*- coding: utf-8 -*-
"""
qi=1-smoothing(if i=y)
qi=smoothing / (self.size - 1) (otherwise)#所以默认可以fill这个数,只在i=y的地方执行1-smoothing
另外KLDivLoss和crossentroy的不同是前者有一个常数
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.9, 0.2, 0.1, 0],
[1, 0.2, 0.7, 0.1, 0]])
对应的label为
tensor([[ 0.0250, 0.0250, 0.9000, 0.0250, 0.0250],
[ 0.9000, 0.0250, 0.0250, 0.0250, 0.0250],
[ 0.0250, 0.0250, 0.0250, 0.9000, 0.0250]])
区别于one-hot的
tensor([[ 0., 0., 1., 0., 0.],
[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.]])
"""
import torch
import torch.nn as nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
class LabelSmoothing(nn.Module):
"Implement label smoothing. size表示类别总数 "
def __init__(self, size, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
#self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing#if i=y的公式
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
"""
x表示输入 (N,M)N个样本,M表示总类数,每一个类的概率log P
target表示label(M,)
"""
assert x.size(1) == self.size
true_dist = x.data.clone()#先深复制过来
#print true_dist
true_dist.fill_(self.smoothing / (self.size - 1))#otherwise的公式
#print true_dist
#变成one-hot编码,1表示按列填充,
#target.data.unsqueeze(1)表示索引,confidence表示填充的数字
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
if __name__=="__main__":
# Example of label smoothing.
crit = LabelSmoothing(size=5,smoothing= 0.1)
#predict.shape 3 5
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.9, 0.2, 0.1, 0],
[1, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# Show the target distributions expected by the system.
plt.imshow(crit.true_dist)
调用的时候注意
module的init函数里面,fc后面要加上LogSoftmax函数,因为KLV要求输入log概率
self.Logsoftmax=nn.LogSoftmax()
forward函数里
x = self.fc(x)
x=self.Logsoftmax(x)