物体检测算法SSD简述
其实SSD的论文是在YOLOv2之前看的,但由于那时本人初识机器学习,还不了解基本概念,所以只是囫囵吞枣,没能理解得很透彻,于是今天重新拾起SSD,并编辑出一篇学习记录,希望对大家有所帮助。
如果本文中某些表述或理解有误,欢迎各位大神批评指正。
下面进入正题。
论文原文中提到,作者提出的SSD算法比之前的YOLO算法更快、更精确,精确度可以媲美之前的Faster R-CNN。
为了理解方便,本文将原论文中涉及到的概念重新排序,以便看起来逻辑通顺。
【Multi-scale feature maps for detection】
SSD最大的亮点之一就是利用多尺度的feature map进行分类检测。
如果有朋友不是很清楚feature map是什么,暂时可以将其理解成网络中每个卷积层的输出。
详情可以参看本人的另外一篇博客:
机器学习中的一些基本概念(未完待续)
或自行百度。
在SSD中,不同层级的卷积层输出的feature map尺度不同。
像这样:
(这张图很重要,本文将多处使用到这张图)
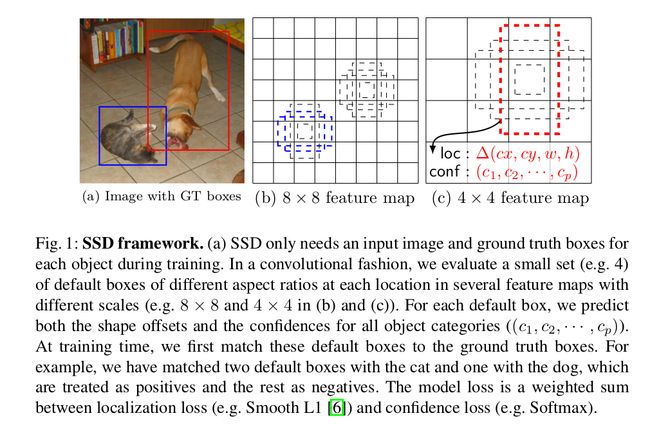
其中,8*8的feature map和4*4的feature map对应不同layer的卷积层输出。
在网络架构上,层级的大小不同(例如,第二层卷积输出8*8的feature map,第三层卷积输出4*4的feature map,第四层卷积输出2*2的feature map),这对多尺度物体的检测提供了便利——2*2的feature map对大尺度的物体进行检测,而8*8的feature map对小尺度的物体进行检测(具体例子可以参见上图中的对猫和狗的检测)。
【注:大小尺度对应feature map的划分与default boxes的生成有关,这里先不对其进行详细说明,下文中会提到。】
【Default boxes and aspect ratios】
(这里的default boxes给我的感觉有点像YOLOv2中的anchor boxes)
对于feature map中每个的location(作者在论文中将其称为feature map location,个人将其理解为feature map中的cell,为了方便表述,下文这样的location称为cell),都会生成一组default boxes,用YOLOv2论文中的话说,这些default boxes是根据人类经验事先选择的。所以,这些default boxes相对于每个cell的位置是固定的。于是,在每个feature map中,我们(事实上是网络)可以了解到ground truth boxes与default boxes之间的位置关系,进而预测坐标偏移。不仅如此,网络还可以预测boxes中的物体类别,对每个类别的划分进行score。
现在让我们来做一个计算:
假设每个cell会生成k个default boxes,网络中一共有c个分类类别,位置信息利用四个属性来表述(如上图所示,分别为default boxes的x偏移量、y偏移量、宽度w、高度h)。
那么每个cell中就会使用(c+4)*k个卷积核(filter)进行运算(每个属性对应一个卷积核);
对应的m*n的feature map中就会使用到一共(c+4)*k*m*n个卷积核。
说到这里,让我们看看SSD的网络架构(原文中将其与YOLO进行对比):
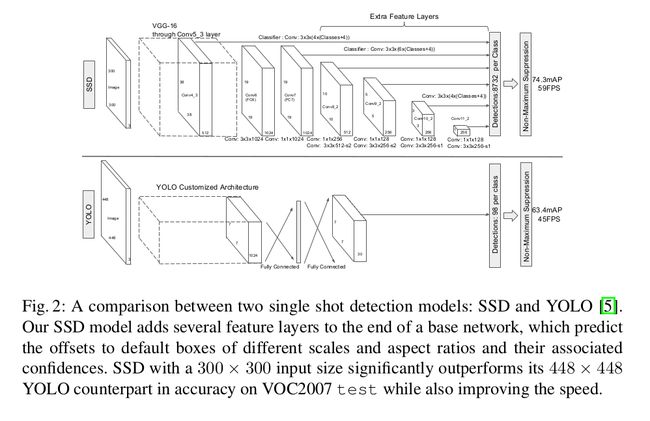
对于p通道为m*n的feature layer,利用3*3卷积核在m*n的每个位置,产生表明类别score(确定分类),或者坐标偏移(确定位置)的输出值。
bounding box的坐标偏移是其相对于一个feature map中default box位置而测量的。
【Choosing scales and aspect ratios for default boxes】
前面有提到,SSD中的default boxes是根据经验事先选择的,那么,SSD是如何对其进行选择的呢?
由于SSD利用不同尺度(lower and upper)的feature maps进行检测,不同卷积层所对应的feature maps尺度不同,所以default boxes的生成也与feature maps所在的层级有关。
在SSD中,假设想要利用m个feature map进行预测,那么default boxes的尺度计算公式如下:

![]()
其中,最低层(lowest layer)default boxes的尺度为0.2,最高层(highest layer)default boxes的尺度为0.9,k表示feature map所处的层数。
此外,由于一个cell要生成多个default boxes,default boxes的宽高比(aspect ratios)也有所不同,论文中使用了:1,2,3,1/3,1/2五个值作为宽高比(ar)。
以此经过一点小小的计算,我们可以算出每个default boxes宽和高(w代表宽、h代表高)的大小:
![]()
![]()
经过运算,我们可以发现,论文中的尺度表述方式 s 是default boxes面积的开平方。
为了增加default boxes的个数(或者只是因为作者喜欢偶数对称性),作者对于宽高比为1的情况另外生成了一个新的default box,它的大小(s)是这样的(会比其他default boxes的面积大一点):
![]()
至此,作者对每个feature map中的每个cell生成了6个default boxes。
实验表明,default boxes的个数越多,模型的性能会越好,但是开销也会越大。
具体原因在本人的一篇介绍YOLOv2的博客中有所分析:
YOLOv2简述
然后,将每个default box的中心放置于这个坐标处:
![]()
其中,分母表示feature map的大小(4*4 feature map所对应的分母就是4),分子中的i,j取值范围为[0,|fk|)。
经过与feature map简单的比较,我们可以看到,将所有可能的i,j值带入坐标之后,对应的坐标刚好铺满整个feature map的所有cell(这也是为什么i,j的取值范围为左闭右开)。
本节过后,我们就可以回答第一节所提出的那个有关待检测物体尺度的问题了:
由于低层feature map划分较细(例如,8*8),较高层feature map划分较粗(例如,2*2),所以feature map中的default boxes大小也不同。很明显可以看出的是,2*2feature map中的default boxes面积要比8*8feature map中的default boxes面积大,所以高层feature map中对应检测的物体尺度较大,低层feature map中对应检测的物体尺度较小。
【Matching strategy】
在训练期间,网络需要决定哪个default box匹配对应的ground truth box(网络的输入)并据此训练网络。
在本节以及后面的描述中,经常会出现jaccard overlap这个高端大气上档次的词语,原文中使用的是这个词,本文未对其进行修改,但其实jaccard overlap就是我们平时所说的交并比:IoU。
对IoU不了解的朋友们可以参看本人另外一篇博客:
机器学习中的一些基本概念(未完待续)
匹配策略分为两步:
1.用MultiBox中的最佳jaccard overlap(即,IoU最大)匹配每一个ground truth box与default box,用以保证每个ground truth box至少有一个default box相对应。
2.如果default box与ground truth box的jaccard overlap超过某阈值(例如,0.5),那么就把该default box与该ground truth box进行匹配。
这个策略允许为一个ground truth box匹配多个有所重叠的default boxes,而不是要求ground truth box只选择与其有最大重叠的某一个default box。
我们将第一步和第二步中所有匹配到ground truth box的default box称为正样本(positive sample);
将所有没有匹配到ground truth box的default box称为负样本(negative sample)。
【Hard negative mining】
匹配过后,我们会发现,只有少数default boxes是正样本,而绝大多数是负样本。
所以,作者将负样本进行筛选:以confidence loss由高到低对负样本进行排序,将排序靠后的负样本剔除掉,直到正样本和负样本的比例约为1:3。
那么,confidence loss是什么?
【Training objective】
神经网络训练的目标往往是将一个loss值最小化,我们可以将这个loss值看作模型预测结果与我们期望得到的真实结果的偏差。
有了这样一个概念,对confidence loss的理解就很简单了。
在SSD中,模型需要预测的东西一共分两大类:位置、分类。SSD将对应于分类的loss称为confidence loss(conf),对应于位置的分类称为localization loss(loc),模型的总loss可以简单看做conf和loc的加权平均值(但事实上可能会比加权平均值复杂一些)。
公式部分由于排版等问题不在本文中进行讲解,有兴趣的朋友们可以参看论文原文进行研究。
【Data augmentation】
这部分其实可以看做作者为了防止过拟合、增多训练数据、提高鲁棒性而使用到的一个小技巧——数据增广。
对于每一张图片,训练的时候随机进行如下操作:
1.使用原始图像
2.采样一个patch,与物体的最小jaccard overlap为0.1,0.3,0.5,0.7或0.9
3.随机采样一个patch
且在上述采样操作过后,得到的patch被resize到一个固定的尺寸。接着,对图片进行概率为0.5的水平翻转。
经过如上这么一折腾,就增加了数据多样性。
【Experimental Results】
费了这么多的周折,SSD在一些数据集上的测试结果如下:


两个字,优秀!
更多的实验过程、实验数据等资料在论文原文中都有详细列出,本文就不再赘述。
【写在后面】
如果对本文哪里有不理解的地方,多看看第一张图,相信对理解SSD会有很大帮助。
论文原文地址:
SSD: Single Shot MultiBox Detector