KNN实现CIFAR-10数据集识别
cs231n链接:http://cs231n.github.io/linear-classify/,
训练集链接:https://download.csdn.net/download/fanzonghao/10592049
KNN缺点:每个测试样本都要循环一遍训练样本。
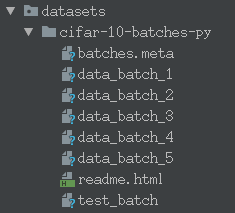
该数据集由5个data_batch和一个test_batch构成,测试代码
import pickle
import numpy as np
fo=open('./datasets/cifar-10-batches-py/data_batch_1','rb')
dict=pickle.load(fo,encoding='bytes')
print(dict)
print(dict[b'data'].shape)
print(dict[b'labels'])
print(len(dict[b'labels']))
print(dict[b'filenames'])
print(len(dict[b'filenames']))
fo.close()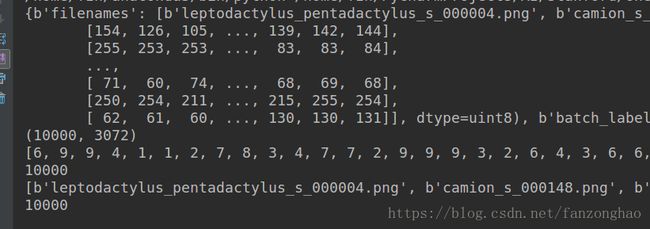
可看出,一个data_batch由10000个,32×32×3大小的图片组成,5个就是50000个,test_batch也是10000张,故有50000张训练样本,10000张测试样本。
将5个训练集合成一个代码如下:
import pickle
import numpy as np
"""
解压数据集
"""
def unpickle(file):
fo=open(file,'rb')
dict=pickle.load(fo,encoding='bytes')
fo.close()
return dict
"""
5个data_batch和1个test_batch合成一个
"""
def load_cifar10(file):
data_train = []
label_train=[]
#融合训练集
for i in range(1,6):
dic=unpickle(file+'data_batch_'+str(i))
for i_data in dic[b'data']:
data_train.append(i_data)
for i_label in dic[b'labels']:
label_train.append(i_label)
# print(np.array(data_train).shape)
# print(np.array(label_train).shape)
# 融合测试集
data_test=[]
label_test=[]
dic = unpickle(file + 'test_batch')
for i_data in dic[b'data']:
data_test.append(i_data)
for i_label in dic[b'labels']:
label_test.append(i_label)
# print(np.array(data_test).shape)
# print(np.array(label_test).shape)
return (np.array(data_train),np.array(label_train),np.array(data_test),np.array(label_test))
path='./datasets/cifar-10-batches-py/'
# #(50000,3072) (50000,) (10000,3072) (10000,)
(data_train,label_train,data_test,label_test)=load_cifar10(path)
print(data_train.shape)
print(label_train.shape)
print(label_train[:10])
print(data_test.shape)
print(label_test.shape)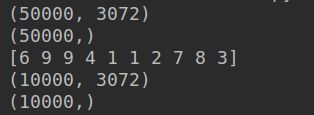
KNN代码:
import numpy as np
import pickle
"""
程序功能:k近邻实现cifar10上的样本分类 精度低 测试时间长
"""
#输入训练集和测试集
#解压数据集
def unpickle(file):
fo=open(file,'rb')
dict=pickle.load(fo,encoding='bytes')
print(dict)
fo.close()
return dict
#融合训练集和测试集作为输出总样本
def load_cifar10(file):
data_train = []
label_train=[]
#融合训练集
for i in range(1,6):
dic=unpickle(file+'data_batch_'+str(i))
for i_data in dic[b'data']:
data_train.append(i_data)
for i_label in dic[b'labels']:
label_train.append(i_label)
# print(np.array(data_train).shape)
# print(np.array(label_train).shape)
# 融合测试集
data_test=[]
label_test=[]
dic = unpickle(file + 'test_batch')
for i_data in dic[b'data']:
data_test.append(i_data)
for i_label in dic[b'labels']:
label_test.append(i_label)
# print(np.array(data_test).shape)
# print(np.array(label_test).shape)
return (np.array(data_train),np.array(label_train),np.array(data_test),np.array(label_test))
path='./datasets/cifar-10-batches-py/'
#(50000,3072) (50000,) (10000,3072) (10000,)
(data_train,label_train,data_test,label_test)=load_cifar10(path)
#print(label_train)
print(data_train.shape,label_train.shape,data_test.shape,label_test.shape)
#print(data_test.shape[0])
"""
实现最近邻的预测
"""
class NearestNeighbor:
def __init__(self):
pass
def train(self,X,y):
self.Xtr=X
self.ytr=y
def predict(self,X):
num_test=X.shape[0]
self.X=X
Y_pred=np.zeros(num_test,dtype=self.ytr.dtype)
for i in range(num_test):
distances=np.sum(np.abs(self.Xtr-self.X[i,:]),axis=1)
#distances=np.sqrt(np.sum(np.square(self.Xtr-self.X[i,:]),axis=1))
min_index=np.argmin(distances)
Y_pred[i]=self.ytr[min_index]
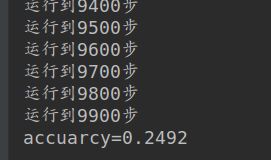
if i%100==0:
print('运行到{}步'.format(i))
return Y_pred
nn=NearestNeighbor()
nn.train(data_train,label_train)
Y_pred=nn.predict(data_test)
accuarcy=np.mean(label_test==Y_pred)
print('accuarcy={}'.format(accuarcy))
打印结果:精度不高,后面引入神经网络
SVM损失函数:
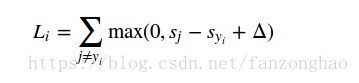
loss.py
import numpy as np
"""
程序功能:利用SVM代价函数实现损失值的积累
"""
def L(X,y,W):
#X [3073,50000]
#y 一维(50000,)
#W [10,3073]
delta=1.0
scores=np.dot(W,X)
#print(y)
#对应训练样本的输出y
#print(scores[y, np.arange(scores.shape[1])])
#(10,50000)
#SVM函数
margins=np.maximum(0,scores-scores[y, np.arange(scores.shape[1])]+delta)
#print('margins.shape={}'.format(margins.shape))
margins[y,np.arange(scores.shape[1])]=0
loss=np.mean(margins)
return lossoptimizer_grand.py
import numpy as np
import pickle
import loss
"""
函数功能:利用随机搜索和局部随机搜索来获取W和b采用SVM损失函数 获取最佳的W和b
"""
#输入训练集和测试集
#解压数据集
def unpickle(file):
fo=open(file,'rb')
dict=pickle.load(fo,encoding='bytes')
fo.close()
return dict
#融合训练集和测试集作为输出总样本
def load_cifar10(file):
data_train = []
label_train=[]
#融合训练集
for i in range(1,6):
dic=unpickle(file+'data_batch_'+str(i))
for i_data in dic[b'data']:
data_train.append(i_data)
for i_label in dic[b'labels']:
label_train.append(i_label)
# print(np.array(data_train).shape)
# print(np.array(label_train).shape)
# 融合测试集
data_test=[]
label_test=[]
dic = unpickle(file + 'test_batch')
for i_data in dic[b'data']:
data_test.append(i_data)
for i_label in dic[b'labels']:
label_test.append(i_label)
# print(np.array(data_test).shape)
# print(np.array(label_test).shape)
return (np.array(data_train),np.array(label_train),np.array(data_test),np.array(label_test))
path='./datasets/cifar-10-batches-py/'
#(50000,3072) (50000,) (10000,3072) (10000,)
(data_train,label_train,data_test,label_test)=load_cifar10(path)
#print(label_train)
print(data_train.shape,label_train.shape,data_test.shape,label_test.shape)
#(3072,50000)
train_data=np.transpose(data_train)
#增加一行 处理偏置值
bias=np.ones((1,train_data.shape[1]))
#(3073,50000)
train_data=np.vstack((train_data,bias))
print(train_data.shape)
#随机选择最佳的权值 输出最佳的W
def random_search():
bestloss=float('inf')
for number in range(1000):
# 随机搜索 权值随机更新 选出比较好的
W = np.random.randn(10, 3073) * 0.0001
# 计算损失值
lost = loss.L(train_data, label_train, W)
if lost随机最佳权重的打印结果:
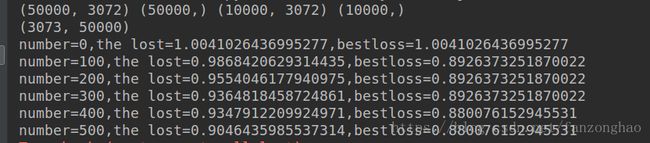
在迭代过程中,权重还变化的结果
