python解析xml+得到pascal voc xml格式用于目标检测+美化xml
1.python解析xml
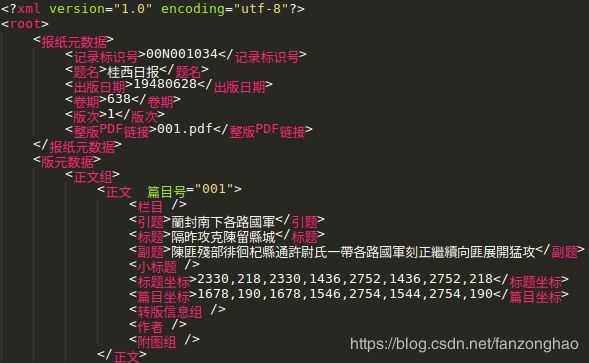

img_path='./data/001.tif'
xml_path='./xml/001.xml'
img=cv2.imread(img_path)
# cv2.imshow('img', img)
# cv2.waitKey(0)
print(img.shape)
try:
xmlp = ET.XMLParser(encoding="utf-8")
tree = ET.parse(xml_path, parser=xmlp)
root = tree.getroot()
print(tree)
print(root)
except Exception as e:
print(e, xml_path)
content_info={}
for i in tree.iterfind('.//正文组/正文'):
print("i.attrib['篇目号']", i.attrib['篇目号'])
for j in i.findall('篇目坐标'):
print(j.text)
print(type(j.text))
content_info[i.attrib['篇目号']] =j.text
print('content_info=',content_info)
若要更改xml内容,可以
new_point='1,2,3,4'
j.text = new_point
tree.write('output_test.xml', encoding='utf-8')2. 得到pascal voc xml格式用于目标检测
img_dir = "./images/train"
csv_dir = "./train_xml.csv"
xml_dir = "./Annotations"
if not os.path.exists(xml_dir):
os.mkdir(xml_dir)
imgs_path_Lists = [os.path.join(img_dir,i) for i in os.listdir(img_dir)]
df=pd.read_csv(csv_dir).copy()
df_value=df.values
print(df_value.shape)
coord_h,coord_w=df_value.shape
print(df_value[:2])
for img_path_List in imgs_path_Lists:
im = Image.open(img_path_List)
width, height = im.size
img_name=img_path_List.split('/')[-1]
# write in xml file
xml_file = open((xml_dir + '/' + img_name.split('.jpg')[0] + '.xml'), 'w')
xml_file.write('\n')
xml_file.write(' steel \n')
xml_file.write(' ' + img_name + ' \n')
xml_file.write(' \n')
xml_file.write(' ' + str(width) + ' \n')
xml_file.write(' ' + str(height) + ' \n')
xml_file.write(' 3 \n')
xml_file.write(' \n')
for i in df_value:
if i[0].split('/')[-1]==img_name:
xmin=i[1]
ymin=i[2]
xmax=i[3]
ymax=i[4]
class_name=i[-1]
# write the region of image on xml file
xml_file.write(' \n')
xml_file.write(' ')


3.美化xml
原始xml如下
22
male
22
female
代码:
def prettyXml(element, indent, newline, level = 0): # elemnt为传进来的Elment类,参数indent用于缩进,newline用于换行
if element: # 判断element是否有子元素
if element.text == None or element.text.isspace(): # 如果element的text没有内容
element.text = newline + indent * (level + 1)
else:
element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * (level + 1)
#else: # 此处两行如果把注释去掉,Element的text也会另起一行
#element.text = newline + indent * (level + 1) + element.text.strip() + newline + indent * level
temp = list(element) # 将elemnt转成list
for subelement in temp:
if temp.index(subelement) < (len(temp) - 1): # 如果不是list的最后一个元素,说明下一个行是同级别元素的起始,缩进应一致
subelement.tail = newline + indent * (level + 1)
else: # 如果是list的最后一个元素, 说明下一行是母元素的结束,缩进应该少一个
subelement.tail = newline + indent * level
prettyXml(subelement, indent, newline, level = level + 1) # 对子元素进行递归操作
def testXML():
from xml.etree import ElementTree as ET
tree = ET.parse('test.xml')
root = tree.getroot()
print(root)
# #查看tag和attrib
# for person in root:
# print(person.tag, person.attrib)
ZF_COORD = ET.Element('字符坐标')
ZWZ = ET.SubElement(ZF_COORD, '正文组')
#这里需要把001变成需要的篇目号
ZW = ET.SubElement(ZWZ , '正文',{'篇目号':"001"})
#栏目
LM=ET.SubElement(ZW, '栏目')
LM.text = '12,12,334,123;12,34,45,56'
#引题
YT=ET.SubElement(ZW,'引题')
YT.text='12,12,334,123;12,34,45,56'
# 标题
BT = ET.SubElement(ZW, '标题')
BT.text = '12,12,334,123;12,34,45,56'
# 副题
FT = ET.SubElement(ZW, '副题')
FT.text = '12,12,334,123;12,34,45,56'
# 小标题
XBT = ET.SubElement(ZW, '小标题')
XBT.text = '12,12,334,123;12,34,45,56'
# 作者
author = ET.SubElement(ZW, '作者')
author.text = '12,12,334,123;12,34,45,56'
# # 向根节点添加新的子节点
root.append(ZF_COORD)
# 写入
tree.write('./sample.xml', encoding="utf-8",xml_declaration=True)
#美化作用
tree = ET.parse('./sample.xml') # 解析test.xml这个文件,该文件内容如上文
root = tree.getroot() # 得到根元素,Element类
prettyXml(root, '\t', '\n') # 执行美化方法
# ET.dump(root)
tree.write('./sample.xml', encoding="utf-8",xml_declaration=True)新生成xml如下
22
male
22
female
<字符坐标>
<正文组>
<正文 篇目号="001">
<栏目>12,12,334,123;12,34,45,56
<引题>12,12,334,123;12,34,45,56
<标题>12,12,334,123;12,34,45,56
<副题>12,12,334,123;12,34,45,56
<小标题>12,12,334,123;12,34,45,56
<作者>12,12,334,123;12,34,45,56