粒子群优化算法(PSO)之基于离散化的特征选择(FS)(四)
作者:Geppetto
前面我们介绍了特征选择(Feature Selection,FS)与离散化数据的重要性,介绍了PSO在FS中的重要性和一些常用的方法、FS与离散化的背景,介绍了EPSO与PPSO方法。今天我们将介绍与实验相关的细节,包括数据集、用于与我们方法进行比较的基线方法、参数设置、终止标准以及实验的硬件配置。
A. 实验设计
(1) 数据集
为了在高维数据上测试PPSO的性能,我们使用了在http://www.gems-system.org上提供的10个基因表达数据集。表1描述了关于这些数据集的详细信息。
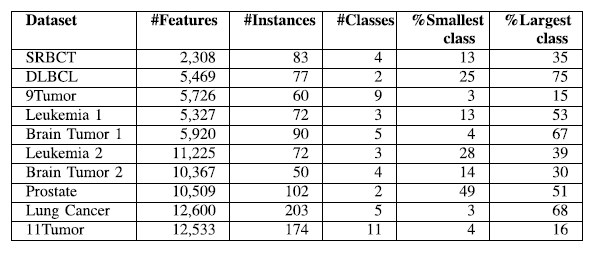
表1.数据集
(2)基线法
为了验证PPSO在离散化和FS中的有效性,我们比较了KNN在PPSO、原始数据集和EPSO转换数据集上的分类性能。我们还将PPSO与两阶段方法(PSO-FS)进行了比较,以确定单阶段方法的性能是否优于两阶段方法。在PSO-FS中,MDL用于在应用PSO进行特征子集选择之前对数据进行离散化。我们还比较了几种传统的两阶段方法,将MDL与LFS进行离散化,采用一致性方法和基于相关的FS (CFS)方法。我们还将PPSO与MChi2进行了比较,MChi2是一种典型的通过离散化处理FS的方法。
(3)参数设置与终止条件
表2描述了三种比较方法PSO-FS、EPSO和PPSO的参数设置。由于搜索空间的大小与问题的维数成正比,问题的维数因数据集而异。10个数据集中的特征数量从2000到12000,导致搜索空间的大小非常不同。因此,我们将总体大小设为特征数除以20,由于计算机内存有限,最大限制为300。最大迭代次数被设置为70。然而,当gbest在10次迭代之后没有得到改进时,也应用了早期停止。PPSO中的比例标准是gbest在10次迭代后没有得到改善,当前gbest适应度至少比以前gbest适应度好1%。对于多类数据集,PPSO的初始大小为150。但是,根据我们的实验,这个值对于二进制类问题也是一个很好的初始大小,因为PSO能够在演化过程中选择适当的特征子集大小。每次满足标度的标准时,初始大小就增加50。

表2.PSO参数设置
(4)实验配置
作为一种包装方法,PPSO可以使用任何学习算法的分类性能来评估粒子。本文使用k = 1的KNN,因为它简单、快速、参数少。
因为这些数据集小样本大小,我们使用10倍交叉验证(CV)产生训练集和测试集。在每一个CV,使用单一的形式使用测试集和剩下的九倍,形成训练集。测试集用于评估产生的离散化和FS基于训练集的每个解决方法。在进化过程中,一个内部循环的十倍的CV训练集用于fitness评估。因此,每一种方法都包含了推荐的两个CV循环,以避免FS偏差。
为了消除统计上的差异,每个方法都对每个数据集运行30次,每次都有不同的随机种子。由于每个数据集使用10倍CV分解为训练和测试集,每个方法总共执行300次。实验是在PC上运行的英特尔核心i7-4770 CPU @ 3.4 GHz和8-GB内存。用统计学的威克森显著性检验和5%显著性水平进行比较,比较了各方法的30次运行结果。
B . 实验结果
表3显示了PSO-FS、EPSO和PPSO的结果。每个方法在30次运行中返回的平均特征子集大小显示在“size”列中。用“full”表示KNN精度的最佳、平均和标准偏差。在第4和第5列中显示了所有连续的特性,或者使用每个比较方法转换的数据。所报告的结果是基于前面介绍的平衡精度公式的测试精度。
“+”或“−”意味着结果比PPSO明显更好或更糟。” = “表示他们有相似的表现。
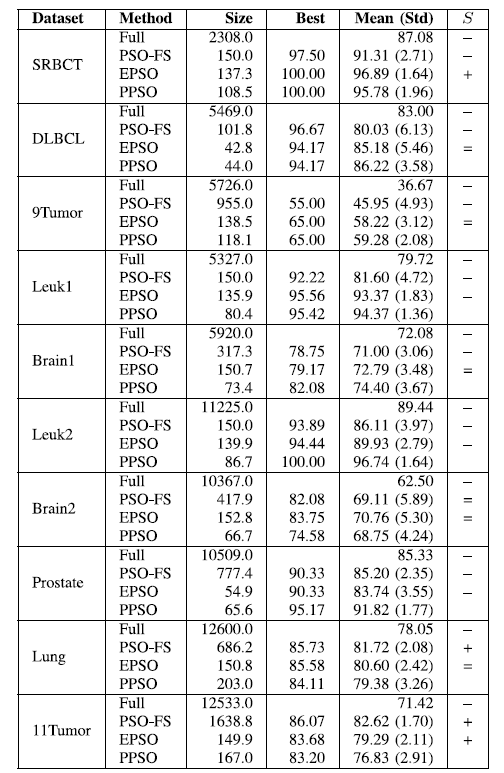
表3.实验结果
C . PPSO结果分析
从表3中可以看出,PPSO选择的特征的平均数明显小于特征的总数。PPSO在4个数据集中选择的特性总数不到1%,在5个数据集中选择不到2%,在SRBCT中选择4.6%。一般来说,PPSO在六个数据集上实现最小的子集。
使用离散和选择的特性,PPSO比在所有10个数据集中使用所有连续的特性获得更好的分类性能。在10个数据集中有7个的准确度提高了5%以上,在9Tumor中提高了23%。
结果表明,通过同时离散和选择单个阶段的相关特征,PPSO可以为高维数据集生成更强大、更紧凑的表示。
D . 总结
在本系列文章中我们提出一种利用BBPSO在单阶段离散化和FS的集成方法。通过提出一种新的方法PPSO,采用一种新的PSO表示法来选择分割点来离散多个特征,同时选择特征。与使用完整的原始特性集EPSO和两阶段方法(PSO-FS)进行比较。
实验结果表明,PPSO可以同时离散多个特征,并选择数量更少的相关特征,具有更好的识别能力。PPSO与PSO-FS的比较表明,离散化与FS在单个阶段结合更有效。与EPSO相比,PPSO获得的结果是相同的或更好的,但功能的数量更少。进一步的分析也表明,与比较的PSO方法相比,PPSO更通用、更可靠。
将PPSO与四种代表两阶段和一阶段方法的传统方法MDL+LFS、MDL+CON、MDL+CFS、MChi2进行了比较。两个实验的结果表明,在大多数情况下,PPSO的性能比MDL+LFS、MDL+CON和MChi2和类似的性能要好得多。结果还表明,在处理高维问题时,PPSO比MDL+CFS和MChi2具有更好的可扩展性。对KNN和NB的比较结果表明,与训练过程中使用的分类器相比,PPSO得到的解可以推广到其他分类器。
作为一种二进制离散化方法,PPSO在需要被离散成多个区间的数据上可能不能很好地工作。此外,还计算了基于MDLP的潜在点。因此,在今后的工作中,我们将研究如何利用其他的算法进行切入点计算、多区间离散化以及优化搜索过程的不同方法。
实证结果表明,PPSO的运行时间可扩展到具有10000+特征的高维数据。但是,由于PPSO表示是静态的,并且与特性集大小成正比,因此对具有10万多个特性的数据集应用PPSO可能会受到内存容量的限制。此外,由于可能的解决方案的指数增长,搜索空间将变得更大,因此可能需要用不同的方法来解决这个问题。将来,我们将研究如何在PPSO中使用动态表示来克服这个限制。
参考文献:
文章:“A New Representation in PSO for Discretization-Based Feature Selection”
作者:Binh Tran, Student Member, IEEE, Bing Xue, Member, IEEE, and Mengjie Zhang, Senior Member, IEEE