Elasticsearch学习笔记(五)批量操作
文章目录
- Elasticsearch系列文章目录
- 一次性检索多个文档【多个查询条件】`mget`
- 更省时的批量操作
- bulk每次传多少命令(数据)合适
Elasticsearch系列文章目录
- Elasticsearch学习笔记(一)Elasticsearch2.4.2安装
- Elasticsearch学习笔记(二)Elasticsearch入门
- Elasticsearch学习笔记(三)Elasticsearch5.1.2安装
- Elasticsearch学习笔记(四)版本控制[并发安全]
- Elasticsearch学习笔记(五)批量操作
- Elasticsearch学习笔记(六)Elasticsearch分布式集群值helloWord
- Elasticsearch学习笔记(七)Elasticsearch分布式集群工作原理简介
一次性检索多个文档【多个查询条件】mget
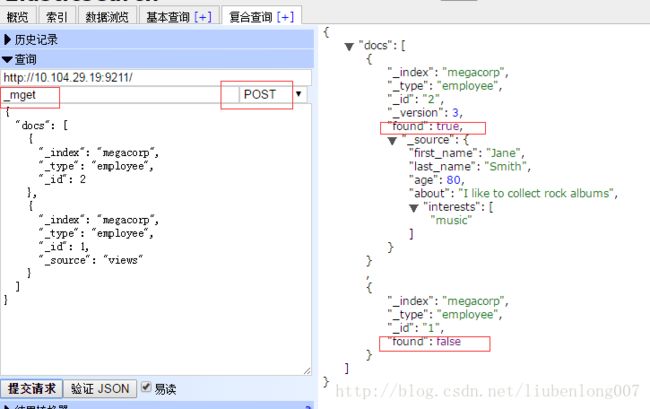
结果中可以看到:第二个文档不存在,但是mget请求返回码是
200,即使一个都不存在也是返回200,所以要判断found是否为TRUE来判断是否真正查询出数据。.
- 上面的
_index,_type都是同一个,可以将查询简写为:
请求URL:megacorp/employee/_mget.
请求参数:
{
"docs": [
{
"_id": 2
},
{
"_id": 1,
"_source": "views"
}
]
}
- 如果查询参数只有id,那么可以进一步简写为:
{
"ids": [1,2]
}
更省时的批量操作
就像mget允许我们一次性检索多个文档一样,bulk API允许我们使用单一请求来实现多个文档的create、index、update或delete。这对索引类似于日志活动这样的数据流非常有用,它们可以以成百上千的数据为一个批次按序进行索引。
bulk请求体如下,它有一点不同寻常:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
这种格式类似于用"\n"符号连接起来的一行一行的JSON文档流(stream)。两个重要的点需要注意:
-
每行必须以
"\n"符号结尾,包括最后一行。这些都是作为每行有效的分离而做的标记。 -
每一行的数据不能包含未被转义的换行符,它们会干扰分析——这意味着JSON不能被美化打印。
action/metadata这一行定义了**文档行为(what action)发生在哪个文档(which document)**之上。
**行为(action)**包含以下四中:create、index、update或delete。
举个比较简单的示例:
[root@vm-29-19-pro01-bgp whatslive-api]# curl -XPOST 'http://10.104.29.19:9211/_bulk?pretty' -d '
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post", "readCount" : 10 }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" , "readCount" : 20 }
{ "update": { "_index": "website", "_type": "blog", "_id": "123", "_retry_on_conflict" : 3} }
{ "doc" : {"title" : "My updated blog post"} }
'
{
"took" : 235,
"errors" : false,
"items" : [ {
"delete" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"status" : 404,
"found" : false
}
}, {
"create" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"status" : 201
}
}, {
"create" : {
"_index" : "website",
"_type" : "blog",
"_id" : "AVnPldywna9xxd0RKinA",
"_version" : 1,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"status" : 201
}
}, {
"update" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3,
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"status" : 200
}
} ]
}
返回结果与请求的顺序是一样的,可以看到。items中的结果与单独请求的结果是一样的。
_bulk批量操作不支持事务,其间任何一个命令执行失败不影响其他的命令的执行。如果有错误,最顶层的errors会被标记为TRUE,仅此而已。
与mget一样,如果是同一个索引、类型相同,可以简写。
bulk每次传多少命令(数据)合适
整个批量请求需要被加载到接受我们请求节点的内存里,所以请求越大,给其它请求可用的内存就越小。有一个最佳的bulk请求大小。超过这个大小,性能不再提升而且可能降低。
最佳大小,当然并不是一个固定的数字。它完全取决于你的硬件、你文档的大小和复杂度以及索引和搜索的负载。幸运的是,这个**最佳点(sweetspot)**还是容易找到的:
试着批量索引标准的文档,随着大小的增长,当性能开始降低,说明你每个批次的大小太大了。开始的数量可以在1000~5000个文档之间,如果你的文档非常大,可以使用较小的批次。
通常着眼于你请求批次的物理大小是非常有用的。一千个1kB的文档和一千个1MB的文档大不相同。一个好的批次最好保持在5-15MB大小间。
参考资料:Elasticsearch 权威指南(中文版)