Elasticsearch安装IK分词器、配置自定义分词词库
-
- 一、分词简介
-
- 1、单字分词:
- 2、二分法分词:
- 3、词库分词:
- 二、配置IK中文分词器
- 三、配置自定义分词拓展词库
一、分词简介
在Elasticsearch中,假设搜索条件是“华为手机平板电脑”,要求是只要满足了其中任意一个词语组合的数据都要查询出来。借助 Elasticseach 的文本分析功能可以轻松将搜索条件进行分词处理,再结合倒排索引实现快速检索。Elasticseach 提供了三种分词方法:单字分词,二分法分词,词库分词。

1、单字分词:
如:“华为手机平板电脑”
效果:“华”、“为”、“手”、“机”、“平”、“板”、“电”、“脑”
2、二分法分词:
按两个字进行切分。
如:“华为手机平板电脑”
效果:“华为”、“为手”、“手机”、“机平”、“平板”、“板电”、“电脑”。
3、词库分词:
按某种算法构造词,然后去匹配已建好的词库集合,如果匹配到就切分出来成为词语。通常词库分词被认为是最理想的中文分词算法。而词库分词最常用的就是 IK 分词。
IK 分词器提供两种分词模式:
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query。
ik_smart:会将文本做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase Query。
二、配置IK中文分词器
安装好ES和Kibana后,进入Kibana操作页面,使用ES默认的分词器来试一下,中文的分词效果

可以看到ES自带的分词器,它是简单的把每个汉字进行了分词,这肯定不是我们想要的效果
所以,我们需要自己来配置一下对中文分词支持比较好的IK分词器
IK分词器插件下载:(IK分词器要和ES版本一致)
7.8.0版:
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
其他版本就直接修改url上的版本号
//进入plugins目录
cd /mydata/elasticsearch/plugins
//新建一个名字叫 ik 的文件夹
mkdir ik
//将下载的ik分词器插件压缩包上传到ik文件夹下,然后解压zip到当前目录
unzip elasticsearch-analysis-ik-7.8.0.zip
//最后给一下ik文件夹的权限
chmod -R 777 /mydata/elasticsearch/plugins/ik
//安装好后,检查下是否安装成功了
使用docker exec -it elasticsearch /bin/bash 命令 进入容器内部
进入容器的 cd /usr/share/elasticsearch/bin 目录
执行 elasticsearch-plugin list 命令(列出es安装的所有插件)
//如果列出了 ik 就说明es的ik中文分词器安装成功了
//装好ik分词器后,记得重启ES容器
docker restart elasticsearch
配置好IK分词器后,再来用IK分词器看下效果
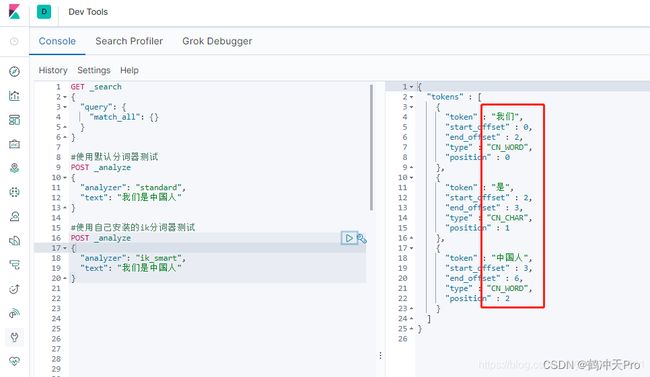
可以看到IK分词器对我们的中文进行了比较理想的分词
三、配置自定义分词拓展词库
IK分词器对中文有比较好的分词效果,但是它并不能对当前比较热门的网络流行词或者一些新的词进行分词处理
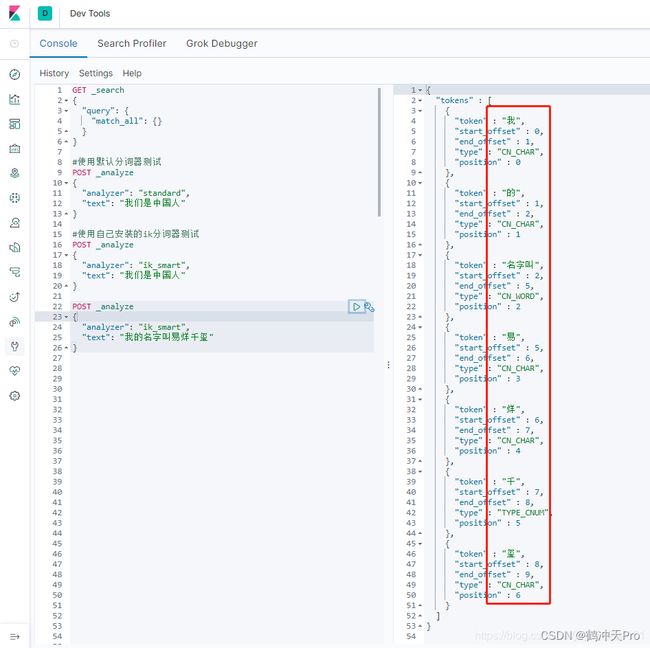
上图可以看到,IK分词器并不支持某一些词汇的分词处理
所以,我们需要配置一下自定义的分词拓展词库,来支持热门的网络流行词或新词。
1、配置自定义词库需要nginx的支持,首先需要安装好nginx
2、安装后nginx后,下边开始配置自定义的分词拓展词库
[root@192 ~]# cd /mydata/nginx/html/
[root@192 html]#
[root@192 html]# mkdir es
[root@192 html]# cd es
[root@192 html]# vi fenci.txt
在/mydata/nginx/html/ 目录下新建一个es文件夹,然后新建一个fenci.txt的文件,在里边写需要支持分词的词汇,然后保存
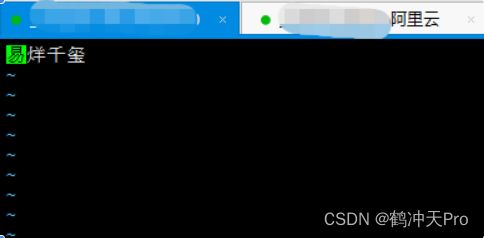
3、配置IK的拓展词库
cd /mydata/elasticsearch/plugins/ik/config
vim IKAnalyzer.cfg.xml
#把里边注释掉的这一句打开并配置成你分词文本所在的nginx访问地址
http://192.168.xx.xx/es/fenci.txt
4、重启ES容器
docker restart elasticsearch
重启后,再来看下效果
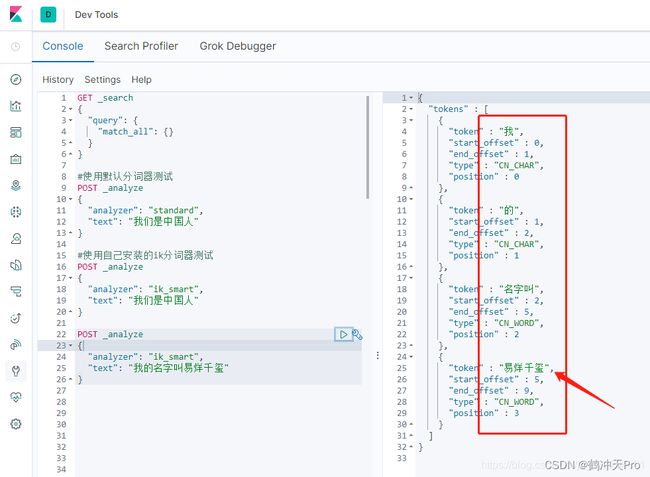
可以看到已经可以按照自定义的分词拓展词库来进行分词了