hive内置函数和自定义函数的使用
1.hive函数的分类
内置函数和自定义函数
1.1、内置函数
1、查询有哪些内置函数:
show functions;
2、查询某个内置函数怎么使用
desc function extended concat;
1.2、自定义函数
分三大类:
1、UDF : user define function : 单行普通函数 (一进一出 : 进一行, 出一行)
substring(string,0,3)
2、UDAF :user define aggregate function : 用户自定义聚集函数(多进一出:多换输入,单行输出)
max, count, min, avg, sum..... group(id)
3、UDTF : user define table_tranform function : 表格生成函数 : (一进多出)
explode(array)
explode(map)
2.内置函数get_json_object的使用案例
需要借助一张临时表
主要用来处理json数据的
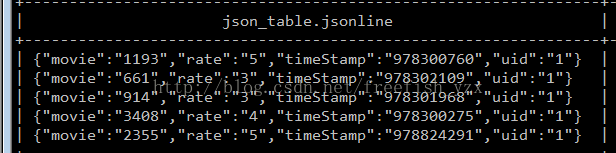
json数据格式如下
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
说明:key _value 形式的 movie =1193 rate=5 timeStamp=978300760 UID=1
数据的准备:rating.json 有63M的文件
// 创建一张表存储json文件
create table json_table (jsonline string);
// 加载数据
load data local inpath "/home/hadoop/rating.json" into table json_table;
create table json_table (jsonline string);
// 加载数据
load data local inpath "/home/hadoop/rating.json" into table json_table;
select * from json_table limit 5;
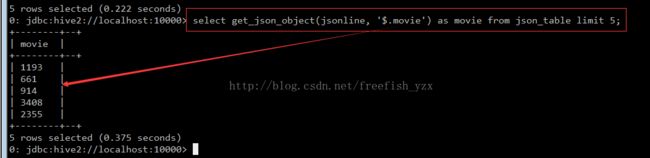
// 通过内置函数get_json_object解析json数据
select get_json_object(jsonline, '$.movie') as movie from json_table limit 5;
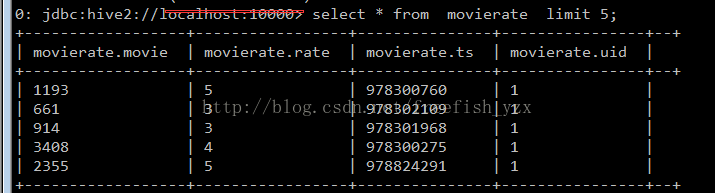
创建一张hive表有这四个字段:
create table movierate(movie int, rate int, ts bigint, uid int) row format delimited fields terminated by "\t";
insert into table movierate
select get_json_object(jsonline, '$.movie') as movie,
get_json_object(jsonline, '$.rate') as rate,
get_json_object(jsonline, '$.timeStamp') as ts,
get_json_object(jsonline, '$.uid') as uid
from json_table;
select * from movierate limit 5;
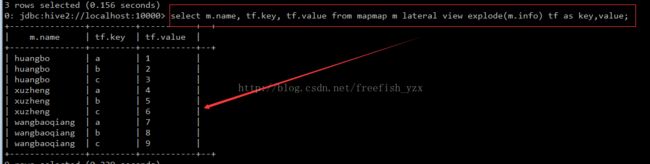
3.自定义函数UDTF中的explode的使用案例
explode使用场景:
huangbo
a,1:b,2:c,3
xuzheng a,4:b,5:c,6
wangbaoqiang a,7:b,8:c,9
huangbo a 1
huangbo b 2
huangbo c 3
xuzhegn a 4
xuzheng b 5
xuzheng a,4:b,5:c,6
wangbaoqiang a,7:b,8:c,9
huangbo a 1
huangbo b 2
huangbo c 3
xuzhegn a 4
xuzheng b 5
.
.
.
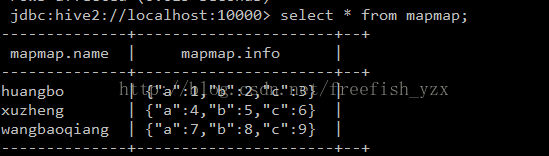
create table mapmap(name string, info map) row format delimited fields terminated by "\t" collection items terminated by ":" map keys terminated by ",";
load data local inpath "/home/hadoop/mapmap.txt" into table mapmap;
select * from mapmap;
select m.name, tf.key, tf.value from mapmap m lateral view explode(m.info) tf as key,value;