【重磅】架构集成导读

作者简介
运小艺 百度云智能运维架构研发负责人
![]()
热衷于直面架构技术挑战,在分布式计算、分布式资源和任务调度方面经验丰富,致力于为百度云智能运维产品Noah提供高可用、高性能、可扩展的系统架构和基础设施。
为什么要写这篇文章
一千个人眼里有一千个哈姆雷特
虽然大家基本都学习过计算机相关专业课程,但在工程应用方面的背景各不相同。步入工作之后,更少有机会系统地学习计算机技术体系与架构,技术理解以及应用的随意性很大,体现出来就是在技术与依赖分层认知上的各不相同:
用功能点叠加的设计方式设计架构系统
难以把握设计中的架构分层以及可替代关系
调研时无从下手,不知道对标的技术系统
过分的强调性能、功能,而忽视可维护性
这些问题造成我们的架构缺乏必要的组件化、可扩展能力,架构被业务的需求推着走,非常被动。
本文旨在提供一个技术索引,以长效自驱地提升技术修为,构建架构技术的体系化认知。同时也能方便设计选型和调研分享,更好传承架构研发知识。
架构集成实践
勿在浮沙筑高台
架构技术具有明显的分层差异,越底层的技术,功能越单一,越靠近计算机硬件系统。越顶层的技术,功能越繁复,也越靠近终端用户。技术集成方式,通常为从某一层切入后,向上封装出各层功能,提供给用户。因此:
任何一个项目初期,尽可能选定较高的技术层级,仅在底层系统不满足某些关键技术指标时,才考虑向下替换;
应避免系统提供的能力涉及多个层次,即使需要如此,也应尽量分成多个解耦的子系统。
现实情况是,我们身边还有大量的系统,以垂直的方式,直接在RPC的基础上构建完整系统功能,系统庞大难以分离不同层级功能。宛如构建在浮沙之上的高台,根基不稳、摇摇欲坠。
逼疯天秤座
纠结于各种工程实现最终折衷出唯一一条选型路径,也正是架构的迷人之处。所以,如果在设计之初,没有经历过架构选型的纠结(不论是可选方案太少、还是可选方案皆可)往往都隐含了明显的架构问题。
常用分布式技术分层
正如所有的系统都源自更底层系统技术的集成,表中的每一层都集成自其更底层的几个或多个技术,所以,表格越往上,系统越复杂和庞大,越向下,越基础和独立。
数据结构做为基础中的基础,并未包含在下列分层中
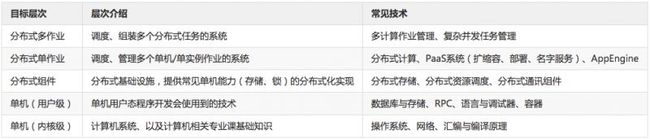
分层说明
单机(内核级)
1操作系统操作系统中包含了最基础的计算机主要子系统的工作原理,是架构研发最需要吃透的基础课。我们绝大多数的架构工作,实际就是在将这些单机能力分布式化。操作系统的核心部分包括:
进程/线程管理与调度:从进程与线程区别到CPU调度
虚拟内存:分段和分页
文件系统
还记得ISO的OSI吗?OSI七层模型是一个比较好的架构分层思想实践,即:每一层只依赖其直接下层技术。当然,传输层之上分成三层也确有多余。
网络有几个经典的概念值得好好理解:
压水晶头做网线(手动滑稽)
冲突检测与二进制指数回退
ARP与数据帧
三次握手与四次挥手
滑动窗口
此外,HTTP协议格式也需要熟练掌握,毕竟用最基础的Socket实现HTTP请求收发是开发基本功。
3汇编与编译原理实际上汇编与编译原理相关的技术并不太具有广泛的可迁移性,但是这并不妨碍其成为各开发语言的基础。
对于涉及到语法解析的应用开发,如解析XML、或者“1+2=?“这样的表达式求值,编译原理可以提供足够完备的算法和实践支持;
而对于C/C++开发人员来说,学习汇编与编译原理就等同于学Java务必要学JVM。
单机(用户级)
1数据库与存储常见的关系数据库可以认为是在文件系统、编译原理(SQL解释器)基础上做的深度定制。其他形式的单机数据库,也与特定的存储系统紧密相关,差别往往无非是存储在内存还是磁盘,还是二者皆有。几个有趣的与存储相关的技术有:
LevelDB
内存数据库
RPC是让单个进程构成可以协作的计算机系统(典型如分布式系统)的基础,通常意义上一个简单的RPC所涉及的技术包括Socket通讯、序列化/反序列化,而在高并发场景下,则需要进一步考虑IO事件通知机制,多线程模型,内存管理模型。
推荐希望深入研究RPC通讯的同学好好研读《UNIX网络编程》,这是一个大部头,分多卷。另一本则薄的多,但是对网络RPC IO模型介绍的非常详细,叫做《C++网络编程 卷1:运用ACE 和模式消除复杂性》
ACE是一个著名的C++跨平台网络通讯实现,有很多非常好的设计模式,很值得学习借鉴。但也正因为这一点,其在实现上封装层次过深,过于庞大复杂,并不建议在工程上使用。
工程上有很多著名的RPC库可以提供给我们选择,这些库实现通常包含协议描述、序列化、线程池等一系列的组件功能,甚至可以与特定的名字服务整合,以提供复杂的下游发现选择、重传策略。常见的支持多语言的RPC库有:
Thrift
GRPC
BaiduRPC
它们都内置了诸如Protobuf这样的序列化技术,除此之外,还有一些更简单的,仅提供了RPC事件通知的库如:
libev
libevent
真正掌握一门语言的开始,都是看是否掌握了这种语言的调试。正所谓“Bug不会追,如何写代码”。相比较打日志,调试器对调试能力和效率的提升毋庸置疑。而掌握调试器最好的方法就是经常去用,反过来这也是从程序运行期反思理解语言特性的一种很好的方式。
语言层面也有一些辅助调试的工具如:
gflag(当然这个库的本意是用作功能开关)
我们更希望的方式是借助各种单测开发技术,确保开发完成的功能,就是已经”调试“过的,这样的工具如:
Google Test(googletest)
除了创造上面的工具库,Google还热衷于创造新的语言,这些语言有着共同的特点,即以C++的语法为基础,并且面向工程研发做了特别的优化,以简化开发(简化代码中太多的“废话”)。所以我更倾向于称其为“工程语言”(类比脚本语言也是对特定场景的简化),它们更像是传统语言的语法糖集合。
正因为此,建议先足够理解C++或Java这样的传统语言之后,再去学习这些“工程语言”,包括:
Go:面向服务器工程场景的研发
Dart:面向前端、移动端的研发
虚拟化技术是近年来新兴的技术,从早期的虚拟机,到近期方兴未艾的容器技术,以及各种云,虚拟化走过了从强隔离到弱隔离,从高资源占用到低资源占用的过程,并逐渐为业界所接受并成为分布式的主流底层技术。
虚拟机方面的技术,可以直接试用下VMware或者Virtual PC。
容器技术,从最基本的CPU、内存隔离,到包含镜像的完整软件环境隔离,可以分成:
cgroup
LXC
Docker
分布式组件
1分布式存储分布式存储,字面意思即存储的分布式化。因此,除了存储方案典型要考虑的性能问题,分布式场景下的存储系统,还要直面一致性问题的挑战。同时,由于总是不可能由单台机器存储所有数据,通常还要考虑如何做分区(Partition)。
典型的解决分布式强一致问题的算法:
Paxos
依照复杂程度不同,分布式存储有这么几种实现:
如分布式K-V存储:
DynamoDB
ZooKeeper
etcd
如分布式文件系统:
GFS
HDFS
AFS(还有NFS等公司内部实现)
如基于按列存储的分布式表格系统:
Bigtable
HBase
Cassandra
以及完整支持了分布式事物的分布式数据库:
Spanner
2分布式资源调度上述并未考虑Amazon Aurora等打了分布式补丁的传统数据库
分布式资源调度用于在一个分布式的集群上,给资源需求方,提供最佳的资源需求匹配。资源需求可能是多个维度的(CPU、内存、网络),可能会有Locality的需求,这些都可以通过资源调度算法得到满足,如:
Mesos的主导资源优先算法(DRF)
针对资源调度系统,Google的关于Omega的论文中有一个很好的断代,可以参见
《Omega: flexible,scalable schedulers for large compute clusters》
除此之外,Borg做为Google内部仍在线上运行(实际上Borg应该算一个PaaS系统,而非单纯的资源调度)、且一直秘而不宣的核心系统(相比较GFS、MapReduce、Bigtable分布式三大件很早就有论文发表,Borg的论文憋了10年以上),其在工程实现上的确有很多精妙之处,可以参见
《Large-scale cluster management at Google with Borg》
3分布式通讯组件Google内部曾希望用Omega替代Borg底层的资源调度层,以支持各种定制化的资源调度需求,然而除了论文似乎并未其他进展;
相比较实现了大一统的Borg,Google的硬件基础设施(10万台左右规模的标准化机房、高速机房间互联)更令人羡慕。
P2P下载是最著名的去中心化的技术(近年来有被区块链取代的可能),天然具有技术难度(测试、调优),作为其中最广为应用的P2P技术,集合了网络通讯(点对点、广播)存储管理(内存缓存管理与磁盘读写优化)等技术的大成。除了最基本的提升分享率、提升缓存命中外,与P2P相关的还有几个技术值得了解:
NAT穿透
DHT
DHT和区块链也可以被看做是一种分布式存储技术,区别在于,类似拜占庭将军问题这样的“高容错一致性”问题,是传输通常都要面对的(如协议必备的CRC校验字段),而存储场景下通常不需要。
反向代理是在我们系统中常见的一类模块,通常都被称为Proxy。然而将反向代理的模型泛化出去,在我们的系统中,采用了Server/Agent通讯架构中的Server,均可视为,外界访问所有Agent的Proxy。因此研究反向代理架构有利于进一步改进我们的集群通讯模型。
反向代理技术中最著名的当属
Nginx
消息中间件是另一类常见的分布式通讯组件实现。通常来说,消息中间件可以很好的实现上下游通讯解耦,因为上游不再需要知道下游的实际地址是什么。然而这种转发的模式带来的最大问题就是性能和消息传递的可靠性方面的挑战。所以需要小心的选择使用消息中间件这把双刃剑。典型的分布式消息中间件有:
Kafka
分布式单任务
PaaS、AE、分布式计算随着近些年大数据、分布式系统的发展,越来越成为业界广泛关注。从架构上来说这三类系统高度一致,差别仅在于,系统的用户是可以在其上运行任意程序(PaaS),还是特定语言、功能的程序(AE),还是限定了输入、输出、计算过程的计算任务(分布式计算)。
1分布式计算分布式计算是个宽泛的名词,任何分布式环境中的计算逻辑都可以认为是分布式计算。但是我们语义下的分布式计算,通常指这两类:
Stream
流式计算以其良好的处理时效性,常被用于各种在线场景下的数据处理。也由于其实现的简便性,所以有更多非纯在线计算系统,会把模块串联起来,形成一个数据处理流。这样实现的好处显而易见:简单、容易理解。问题也是显而易见,流式计算通常的复杂性均在这种实现中被忽略,如:数据堆积、处理吞吐低、失败重放。整个流像一个锁链严格的耦合在一起,架构灵活性严重缺失。
一种方案是将这种自研的“贪吃蛇系统”,迁移到流式计算系统上去。这样做的好处是适应性良好,架构改动不大。典型的流式计算系统有:
Storm
DStream
流式方案在功能上很好,但在吞吐能力上可能未必:流式计算通常在Failover方面会更加复杂,需要数据重放等机制。
与流式计算相比批量计算更适合大吞吐场景,也正因此,通常批量计算系统都会与分布式文件存储系统组合,共同提供服务。
MapReduce
在当前,MapReduce已经成为批量计算的代名词,MapReduce通过Map,将数据按分区规则分治处理,再通过Shuffle重新分区并排序后,进行聚合处理。
MapReduce处理模型必看《MapReduce: Simplified Data Processing on Large Clusters》
正如论文的名字,这是一种针对大集群的简单数据处理方案,但是实际上可能未必这么理想:Shuffle后的数据分区倾斜会让你消耗大量时间来刷新Reduce任务的进度页面。
Hadoop
Apache的开源MapReduce实现——Hadoop几乎是现阶段唯一能用到的MapReduce系统。
Hadoop的名字来自作者儿子的一只蓝色小象
完整的Hadoop计算系统由Job调度,资源调度,HDFS三个主要的部分组成。在早期实现中,Job调度与资源调度合并在一起,造成无法支持大规模的Job调度。后来,资源调度有一个专门的系统Yarn来实现。Yarn为Job分配资源的同时,也会为Job的调度管理器分配资源。这就让Job管理器不至于需要管理所有的Job-Task运行(相比较Task的数量和活跃性,资源管理器以管理机器为主,工作并没有那么繁忙)。
Hadoop通过预测执行来缓解最后运行的部分Task的长尾问题,在部分场景下效果显著。
2PaaS系统应当说PaaS系统是一类系统的集合,通常至少包括资源调度+部署+名字管理,更广泛的实现还会包括监控、分级发布等更上层的能力。所以对于PaaS的能力,最直观的认知就是:PaaS能够将任意单机程序,分布式化。
这也是PaaS的最大挑战,即统一不同单机程序的行为(如启动、停止、配置加载等)。因此实现一个PaaS从来不是很难的事情。最难的一直都是何处收(制定行为标准)、何处放(满足现状需求)。
PaaS的典型实现可以了解:
Kubernetes:做为Borg的继任之作,Kubernetes已经距离行业标准越来越近
AE可以看作是在PaaS的基础上,给用户提供一个开发框架,让用户只能依赖框架用特定的语言来实现自己的服务。框架的好处是可以避免PaaS中统一启停行为这些恼人问题,但是也给开发带来了较大的局限。毕竟很难将一个现成写好的应用再迁移到AE中。
AE更适合小而轻的服务,这与框架的设计倾向和局限是分不开的,不过这倒是可以与微服务概念做到很好的结合。
如果没有AE这样的架构支持而直接应用微服务概念,结果堪称灾难
AE方面的实现可以了解:
GAE
有趣的是,很多人用GAE开代理[嘘]
分布式多任务
随着分布式计算的深入人心,所处理的计算任务越来越复杂,以至于并不能用单个计算任务实现的时候,分布式多任务管理的系统也应运而生。我所见过的最简单的多任务管理,甚至就是一个Shell脚本,负责将多个Hadoop作业按顺序启动,同时控制上下轮次的输入、输出位置,做一些简单的目录迁移、备份处理。
1多计算作业管理多计算作业管理代表了最复杂的数据流逻辑,这种系统通常会组合多个分布式计算任务,这样可以统一的描述整个计算过程的输入、输出,以及子计算任务间的依赖关系,形成一个大的计算拓扑。将多个计算任务整合管理,也有利于简化任务的维护,并提供部分计算场景下的性能优化(如中间数据的Cache机制)。
同样在多计算作业系统中,不会再像单分布式计算任务那样,明确的区分Stream计算模型和Batch计算模型,各种实现都尽可能让不同的计算形式归一。
目前比较流行的多计算作业系统:
Flink:用流式计算模型支持批量计算
Spark:用批量计算模型支持流式计算
除此之外,还有些仅实现了语言层计算抽象,而没有提供计算系统支持的项目:
Apache Beam
Baidu Bigflow
我们常见的xxx通路、xxx处理流、xxx处理环实际上都是实现了一个多计算作业系统。
2复杂并发任务管理复杂并发任务管理,代表了最复杂的控制流逻辑。通常我们会将其抽象为用DAG进行表示的工作流实现。所以常见的实现或者以点为核心描述,或者以边为重点进行组织。
有意思的是,有些并发任务管理的系统,实现的目的就是为了管理多个计算任务,比如:
Azkaban
也有更面向通用的工作流场景的:
Airflow
架构技术的路何其漫长,本文意在给架构新人提供一个关于技术演进路线的导引:在与Feature、Bug的拼杀之中,仍能保持一次澄明,记得一路上从何而来,又去往何方。
最后,请选择一条自己喜欢的路,然后一直走下去。欢迎持续关注百度云Noah智能运维。


↓↓↓ 点击"阅读原文" 【了解更多精彩内容】