Kafka Streams实战-开发入门
本文会介绍:
- Kafka Streams APIs
- Kafka Streams的Hello World例子
- 深入探索基于Kafka Streams的ZMart应用程序
- 把输入流拆分为多个流
1. Streams APIs
Kafka有两类流APIs,low-level Processor API和high-level Streams DSL。本文介绍的是后者DSL,它的核心是KStream对象,表示流式key/value的数据,它的大多数方法都返回KStream对象的引用。
早在2005年,Martin Fowler和Eric Evans开发了fluent interface的概念,也就是接口的返回值和调用时传入的实例是相同的。这种方式对构造多个参数的对象时非常有用,例如:
Person.builder().firstName("Beth").withLastName("Smith").withOccupation("CEO");在Kafka Streams中,有个重要的区别:返回的KStream对象是一个新的实例,而不是调用方法时的实例。
2. Hello World例子
以下让我们创建一个简单的Hello World例子,把输入的字母转换为大写字母。一般的开发流程是:
- 配置Kafka Streams
- 创建Serde实例
- 创建处理的拓扑
- 创建和启动KStream
2.1 配置Kafka Streams
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "hello-world");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");以上两个属性是必须的,因为它们没有默认值。而且应用的ID在集群内必须是唯一的,服务器地址可以是单个服务器和端口,也可以是由逗号分隔的多个服务器和端口,例如"host1:9092,host2:9092,host3:9092"。
2.2 创建Serde实例
在Kafka Streams中,Serdes类提供了创建Serde实例的简便方法,如下所示:
Serde stringSerde = Serdes.String(); 此行代码是使用Serdes类创建序列化/反序列化所需的Serde实例。Serdes类为以下类型提供默认的实现:String、Byte array、Long、Integer和Double。
2.3 创建处理的拓扑
每个流应用程序都实现并执行至少一个拓扑。拓扑(在其它流处理框架中也称为有向无环图DAG,Directed Acyclic Graph)是一系列的操作和转换,每个事件从输入流动到输出。下图是Hello World例子的拓扑图:

下面是相应的处理拓扑代码:
StreamsBuilder builder = new StreamsBuilder();
KStream simpleFirstStream = builder.stream("src-topic",
Consumed.with(stringSerde, stringSerde));
// 使用KStream.mapValues方法把每行输入转换为大写
KStream upperCasedStream = simpleFirstStream.mapValues(line -> line.toUpperCase());
// 把转换结果输出到另一个topic
upperCasedStream.to("out-topic", Produced.with(stringSerde, stringSerde)); 2.4 创建和启动KStream
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), props);
kafkaStreams.start();3. ZMart应用程序
3.1 主要的需求
- 记录所有客户的消费数据,但要保护敏感信息,例如信用卡号码
- 抽取消费地点的ZIP code,以便分析消费模式
- 抽取客户编号和消费金额,以便计算奖励积分
- 保存所有消费数据,以便日后进行数据分析
3.2 创建Serde实例
因为客户消费的数据是JSON格式,在把数据发送到Kafka时,需要把它序列化为byte数组,这里会使用Google的Gson类:
import java.nio.charset.Charset;
import java.util.Map;
import org.apache.kafka.common.serialization.Serializer;
import com.google.gson.Gson;
public class JsonSerializer implements Serializer {
private Gson gson = new Gson();
@Override
public void configure(Map configs, boolean isKey) {
}
@Override
public byte[] serialize(String topic, T data) {
return gson.toJson(data).getBytes(Charset.forName("UTF-8"));
}
@Override
public void close() {
}
} 相反地,需要把byte数组反序列化为JSON和业务对象,以便在处理器里使用:
import java.util.Map;
import org.apache.kafka.common.serialization.Deserializer;
import com.google.gson.Gson;
public class JsonDeserializer implements Deserializer {
private Gson gson = new Gson();
private Class deserializedClass;
public JsonDeserializer(Class deserializedClass) {
this.deserializedClass = deserializedClass;
}
public JsonDeserializer() {
}
@Override
@SuppressWarnings("unchecked")
public void configure(Map configs, boolean isKey) {
if (deserializedClass == null) {
deserializedClass = (Class) configs.get("serializedClass");
}
}
@Override
public T deserialize(String topic, byte[] data) {
if (data == null) {
return null;
}
return gson.fromJson(new String(data), deserializedClass);
}
@Override
public void close() {
}
} 创建完序列化和反序列化类之后,需要实现Kafka的接口Serde:
import java.util.Map;
import org.apache.kafka.common.serialization.Deserializer;
import org.apache.kafka.common.serialization.Serde;
import org.apache.kafka.common.serialization.Serializer;
public class WrapperSerde implements Serde {
final private Serializer serializer;
final private Deserializer deserializer;
WrapperSerde(Serializer serializer, Deserializer deserializer) {
this.serializer = serializer;
this.deserializer = deserializer;
}
@Override
public void configure(Map configs, boolean isKey) {
serializer.configure(configs, isKey);
deserializer.configure(configs, isKey);
}
@Override
public Serializer serializer() {
return serializer;
}
@Override
public Deserializer deserializer() {
return deserializer;
}
@Override
public void close() {
serializer.close();
deserializer.close();
}
} 然后为了方便使用,创建工具类:
import org.apache.kafka.common.serialization.Serde;
import zmart.model.Purchase;
import zmart.model.PurchasePattern;
import zmart.model.RewardAccumulator;
public class StreamsSerdes {
public static Serde PurchaseSerde() {
return new PurchaseSerde();
}
public static Serde PurchasePatternSerde() {
return new PurchasePatternsSerde();
}
public static Serde RewardAccumulatorSerde() {
return new RewardAccumulatorSerde();
}
public static final class PurchaseSerde extends WrapperSerde {
public PurchaseSerde() {
super(new JsonSerializer(), new JsonDeserializer(Purchase.class));
}
}
public static final class PurchasePatternsSerde extends WrapperSerde {
public PurchasePatternsSerde() {
super(new JsonSerializer(),
new JsonDeserializer(PurchasePattern.class));
}
}
public static final class RewardAccumulatorSerde extends WrapperSerde {
public RewardAccumulatorSerde() {
super(new JsonSerializer(),
new JsonDeserializer(RewardAccumulator.class));
}
}
} 上面的Purchase、PurchasePattern和RewardAccumulator用于表示客户消费数据、消费模式和积分计算,这里省略。然后我们就可以简单地通过StreamsSerdes创建需要的序列化器:
Serde stringSerde = Serdes.String();
Serde purchaseSerde = StreamsSerdes.PurchaseSerde();
Serde purchasePatternSerde = StreamsSerdes.PurchasePatternSerde();
Serde rewardAccumulatorSerde = StreamsSerdes.RewardAccumulatorSerde(); 3.3 创建处理的拓扑
3.3.1 创建数据源节点和第一个处理器
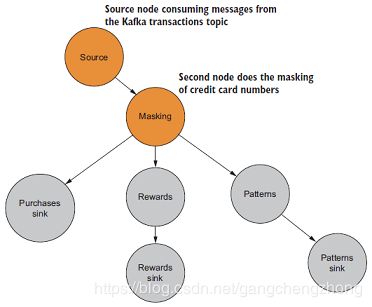
数据源节点负责从Kafka的一个保存所有事务的topic读取消息,第一个处理器负责隐藏信用卡信息,保护客户隐私。
StreamsBuilder streamsBuilder = new StreamsBuilder();
KStream purchaseKStream = streamsBuilder
// 从事务topic读取消息,使用自定义序列化/反序列化
.stream("transactions", Consumed.with(stringSerde, purchaseSerde))
// 使用KStream.mapValues方法隐藏每个信用卡信息
.mapValues(p -> Purchase.builder(p).maskCreditCard().build()); 3.3.2 创建第二个处理器
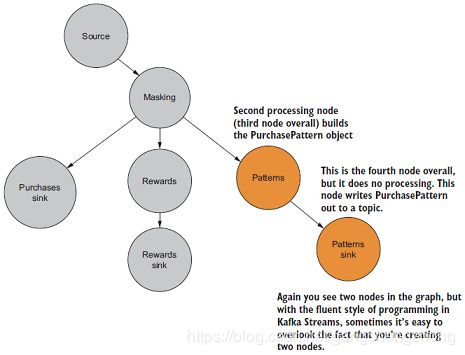
第二个处理器负责抽取消费地点的ZIP code。
KStream patternKStream = purchaseKStream
// 通过自定义PurchasePattern类抽取zip code
.mapValues(purchase -> PurchasePattern.builder(purchase).build());
// 把结果发送到另外一个负责分析模式的topic
patternKStream.to("patterns", Produced.with(stringSerde, purchasePatternSerde)); 3.3.3 创建第三个处理器

第三个处理器负责抽取客户编号和消费金额,计算奖励积分。
KStream rewardsKStream = purchaseKStream
// 通过自定义RewardAccumulator类计算奖励积分
.mapValues(purchase -> RewardAccumulator.builder(purchase).build());
// 把结果发送到另外一个负责处理积分的topic
rewardsKStream.to("rewards", Produced.with(stringSerde, rewardAccumulatorSerde)); 3.3.4 创建最后一个处理器
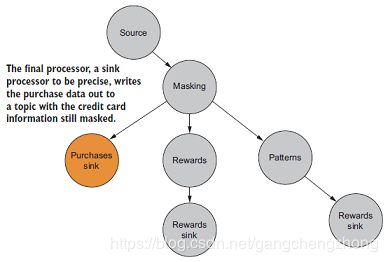
最后一个处理器负责保存所有消费数据。
// 直接把隐藏信用卡信息后的数据发送到另外一个负责保存数据的topic
purchaseKStream.to("purchases", Produced.with(stringSerde, purchaseSerde));3.4 创建和启动KStream
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(), props);
kafkaStreams.start();这样,一个完整的流处理应用可以说完成了。
4. 交互式开发
在开发期间可以使用控制台作为消费者输出查看结果,KStream接口有一个方法KStream.print(final Printed
此外,还可以通过连接withLabel()方法来标记打印的结果,这对处理来自不同处理器的结果时非常有用。在把结果输出到控制台或文件时,重写对象的toString()方法对查看结果是非常必要的。最后,如果不想使用toString方法,或者想要自定义Kafka Streams打印结果的方式,可以使用Printed.withKeyValueMapper方法,其参数KeyValueMapper允许你格式化结果的格式。下面是示例代码:
patternKStream.print(Printed.toSysOut().withLabel("patterns"));
rewardsKStream.print(Printed.toSysOut().withLabel("rewards"));
purchaseKStream.print(Printed.toSysOut().withLabel("purchases")); 输出格式如下:

最左边是标签,然后是key(这里是null),接着是结果。
使用print方法的一个缺点是它创建了一个终节点,这意味着不能将其嵌入到处理器链中。然而,KStream还有一个peek方法,其参数ForeachAction允许你实现apply()方法对每个结果执行操作,返回类型为void。因此KStream.peek中的任何结果都不会向下游转发,非常适合打印结果等操作,它还可以嵌入到处理器链中。
5. 新增需求
- 需要过滤掉一定金额以下的消费,因为管理层对小额购买兴趣不大。
- ZMart已经扩大并收购了一个电子产品连锁店和一个受欢迎的咖啡连锁店,所有来自这些新商店的消费数据都需要发送到他们的topic。
- 把过滤小额购买后的消费数据保存到一个key-value的NoSQL数据库。
5.1 过滤小额购买
为了删除小额购买,需要在Masking和Purchases sink之间插入一个过滤处理器,如下图所示:

以下是相应的代码:
KStream filteredKStream = purchaseKStream
// 使用KStream.filter方法过滤小额消费
.filter((key, purchase) -> purchase.getPrice() > 5.00);
// 把数据发送到另外一个负责保存数据的topic
filteredKStream.to("purchases", Produced.with(stringSerde, purchaseSerde)); 5.2 拆分流
为了把电子产品和咖啡的销售数据分离,需要拆分原来的输入流,如下图所示:
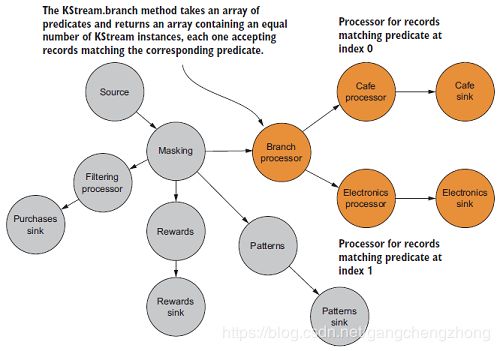
这个时候可以使用KStream.branch方法创建分支流:
KStream[] kstreamByDept = purchaseKStream.branch(
(key, purchase) -> purchase.getDepartment().equalsIgnoreCase("coffee"),
(key, purchase) -> purchase.getDepartment().equalsIgnoreCase("electronics"));
// 把数据发送到相应的topics
kstreamByDept[0].to("coffee", Produced.with(stringSerde, purchaseSerde));
kstreamByDept[1].to("electronics", Produced.with(stringSerde, purchaseSerde)); 5.3 生成新的key值
虽然Kafka保存的数据是key-value形式,但是为了节省数据传输,通常使用null的key值。所以为了把数据保存到一个key-value的NoSQL数据库,需要新增一个处理器用于生成新的key值,如下图所示:
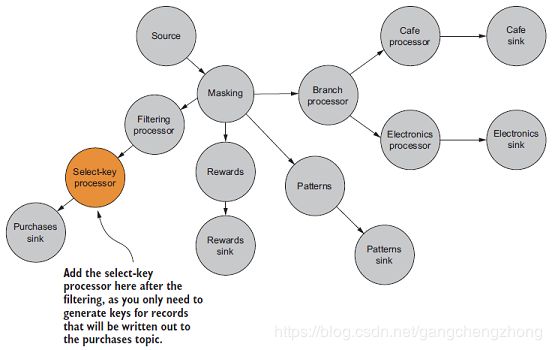
你可以使用KStream.map方法实现,但有一个更简洁的KStream.selectKey方法可以为数据生成新的key值:
// 在过滤方法后链接selectKey方法生成新的KStream实例
KStream filteredKStream = purchaseKStream
.filter((key, purchase) -> purchase.getPrice() > 5.00)
// 使用购买日期为新的key值
.selectKey((key, purchase) -> purchase.getPurchaseDate().getTime());
// 把数据发送到另外一个负责保存数据的topic,注意key值是Long类型
filteredKStream.to("purchases", Produced.with(Serdes.Long(), purchaseSerde)); 6. 把数据写入到关系型数据库
为了防止员工有欺诈行为,需要把怀疑有欺诈行为的指定商店消费数据写入到一个外部独立关系型数据库,以便安全部门执行分析。不难想到,可以直接在Masking节点后新增一个处理器用于过滤指定商店的消费数据,如下图所示:
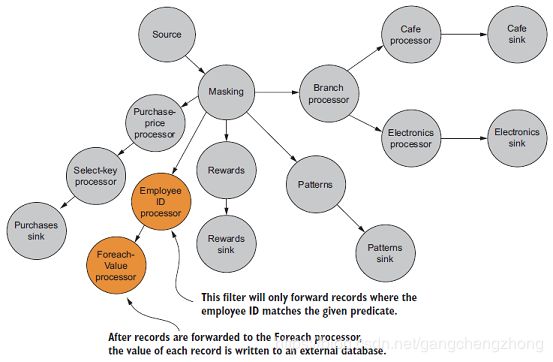
以下是相应的代码:
// 过滤指定商店的消费数据
purchaseKStream.filter((key, purchase) -> purchase.getEmployeeId().equals("000000"))
// 使用KStream.foreach方法对每一个数据执行操作,这里使用SecurityDBService保存数据
.foreach((key, purchase) -> SecurityDBService.saveRecord(purchase.getPurchaseDate(),
purchase.getEmployeeId(), purchase.getItemPurchased()));END O(∩_∩)O