Python实现DBSCAN算法
声明:代码的运行环境为Python3。Python3与Python2在一些细节上会有所不同,希望广大读者注意。本博客以代码为主,代码中会有详细的注释。相关文章将会发布在我的个人博客专栏《Python从入门到深度学习》,欢迎大家关注~
K-Means算法、K-Means++算法以及Mean Shift算法都是基于距离的聚类算法,一般此类聚类的聚类结果都是球状的簇,但当聚类结果是非球状的时候,基于距离聚类的聚类算法得到的聚类结果并不是那么的好,然而,基于密度的聚类算法可以完美的解决此类问题。DBSCAN聚类算法是一种典型的基于密度的算法。
一、基本概念
在DBSCAN算法中,有两个基本的邻域参数,分别是![]() 邻域和MinPts。其中
邻域和MinPts。其中![]() 邻域表示的是在数据集D中与样本点
邻域表示的是在数据集D中与样本点![]() 的距离不大于
的距离不大于![]() 的样本。MinPts表示的是在样本点
的样本。MinPts表示的是在样本点![]() 的
的![]() 邻域内的最少样本点数目,基于此,在DBSCAN算法中数据点分为三类:核心点、边界点、噪音点。
邻域内的最少样本点数目,基于此,在DBSCAN算法中数据点分为三类:核心点、边界点、噪音点。
二、DBSCAN算法原理
在DBSCAN算法中,由核心对象出发,找到与该核心对象密度可达的所有样本形成一个聚类簇。其流程大致如下:
(1)根据给定的邻域参数![]() 和MinPts确定所有的核心对象;
和MinPts确定所有的核心对象;
(2)对每一个核心对象,选择一个未处理过的核心对象,找到由其密度可达的样本生成聚类簇;
(3)重复上述过程。
下面我们使用Python语言实现DBSCAN算法:
def dbscan(data, eps, MinPts):
'''
DBSCAN算法
:param data: 聚类的数据集
:param eps: 半径
:param MinPts: 半径内最少的数据点的个数
:return: 返回每个样本的类型、每个样本所属的类别
'''
m = np.shape(data)[0]
# 区分核心点1,边界点0和噪音点-1
types = np.mat(np.zeros((1, m)))
sub_class = np.mat(np.zeros((1, m)))
# 用于判断该点是否处理过,0表示未处理过
dealed = np.mat(np.zeros((m, 1)))
# 计算每个数据点之间的距离
distance = dist(data)
# 用于标记类别
number = 1
# 对每一个点进行处理
for i in range(m):
# 找到未处理的点
if dealed[i, 0] == 0:
# 找到第i个点到其他所有点的距离
I = distance[i,]
# 找到半径eps内的所有点
index = find_epsilon(I, eps)
# 区分点的类型
# 边界点
if len(index) > 1 and len(index) < MinPts + 1:
types[0, i] = 0
sub_class[0, i] = 0
# 噪音点
if len(index) == 1:
types[0, i] = -1
sub_class[0, i] = -1
dealed[i, 0] = 1
# 核心点
if len(index) >= MinPts + 1:
types[0, i] = 1
for x in index:
sub_class[0, x] = number
# 判断核心点是否密度可达
while len(index) > 0:
dealed[index[0], 0] = 1
I = distance[index[0],]
tmp = index[0]
del index[0]
index_1 = find_epsilon(I, eps)
if len(index_1) > 1: # 处理非噪音点
for x1 in index_1:
sub_class[0, x1] = number
if len(index_1) >= MinPts + 1:
types[0, tmp] = 1
else:
types[0, tmp] = 0
for j in range(len(index_1)):
if dealed[index_1[j], 0] == 0:
dealed[index_1[j], 0] = 1
index.append(index_1[j])
sub_class[0, index_1[j]] = number
number += 1
# 最后处理所有未分类的点为噪音点
index_2 = ((sub_class == 0).nonzero())[1]
for x in index_2:
sub_class[0, x] = -1
types[0, x] = -1
return types, sub_class其中,dist()方法用于计算每个数据点之间的距离,find_epsilon()方法用于找出距离小于等于epsilon样本的下标,这两个方法的实现过程如下:
(1)dist()方法
def dist(data):
'''
计算每个数据点之间的距离
:param data: 训练数据
:return: 返回计算结果
'''
m, n = np.shape(data)
distance = np.mat(np.zeros((m, m)))
for i in range(m):
for j in range(i, m):
tmp = 0
for k in range(n):
tmp += (data[i, k] - data[j, k]) * (data[i, k] - data[j, k])
distance[i, j] = np.sqrt(tmp)
distance[j, i] = distance[i, j]
return distance(2)find_epsilon()方法
def find_epsilon(dist_i, eps):
'''
找出距离小于等于epsilon样本下标
:param dist_i: 样本i和其他样本之间的距离
:param eps: 半径
:return: 返回距离小于等于eps样本下标
'''
index = []
n = np.shape(dist_i)[1]
for j in range(n):
if dist_i[0, j] <= eps:
index.append(j)
return index DBSCAN聚类算法的聚类结果是与![]() 和MinPts有关系的,这里还需要定义一个
和MinPts有关系的,这里还需要定义一个![]() 函数,当然也可以手动指定
函数,当然也可以手动指定![]() 的值:
的值:
def epsilon(data, MinPts):
'''
计算最佳半径
:param data: 训练数据
:param MinPts: 半径内数据点的个数
:return:返回得到的最佳半径
'''
m, n = np.shape(data)
xMax = np.max(data, 0)
xMin = np.min(data, 0)
# np.prod()默认情况下计算所有元素的乘积
eps = ((np.prod(xMax - xMin) * MinPts * math.gamma(0.5 * n + 1)) / (m * math.sqrt(math.pi ** n))) ** (1.0 / n)
return eps三、DBSCAN算法举例
1、数据集:数据集有两个特征,如下所示:

2、加载数据集
我们此处使用如下方法加载数据集,也可使用其他的方式进行加载,此处可以参考我的另外一篇文章《Python两种方式加载文件内容》。加载文件内容代码如下:
def load_data(file_path):
'''
加载数据
:param file_path: 文件路径
:return: 以矩阵形式返回数据
'''
f = open(file_path)
data = []
for line in f.readlines():
data_tmp = []
lines = line.strip().split("\t")
for x in lines:
data_tmp.append(float(x.strip()))
data.append(data_tmp)
f.close()
return np.mat(data)3、保存聚类结果
得到聚类结果之后,我们使用如下方法对聚类结果进行保存:
def save_result(file_name, data):
'''
保存聚类结果
:param file_name: 保存的文件名
:param data: 需要保存的数据
:return:
'''
f = open(file_name, "w")
n = np.shape(data)[1]
tmp = []
for i in range(n):
tmp.append(str(data[0, i]))
f.write("\n".join(tmp))
f.close()4、调用DBSCAN算法
if __name__ == "__main__":
MinPts = 5 # 定义半径内的最少的数据点的个数
data = load_data("F://data.txt")
eps = epsilon(data, MinPts)
types, sub_class = dbscan(data, eps, MinPts)
save_result("types", types)
save_result("sub_class", sub_class)5、得到的结果如下所示
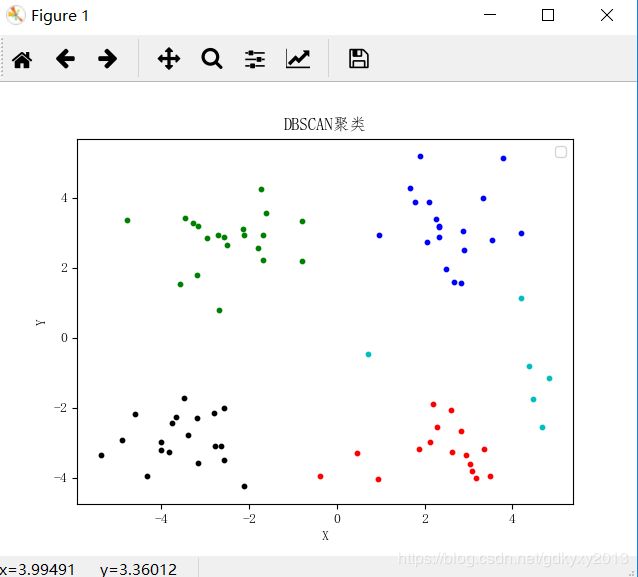
你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题。