YOLO9000学习总结

1:首先将图像划分成7 * 7的网格。
2:每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个 confidence值。
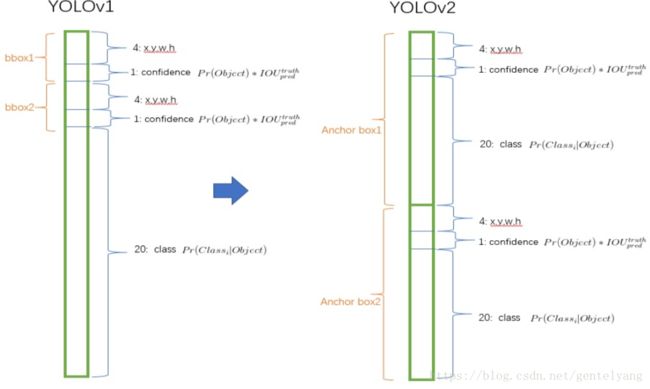
3:每个网格有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别。
confidence代表了所预测的bounding box中含有object的置信度和这个bounding box预测的有多准两重信息。
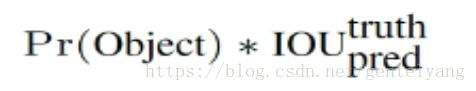
激活函数:leaky rectified linear activation
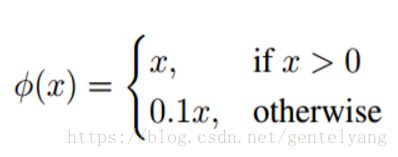
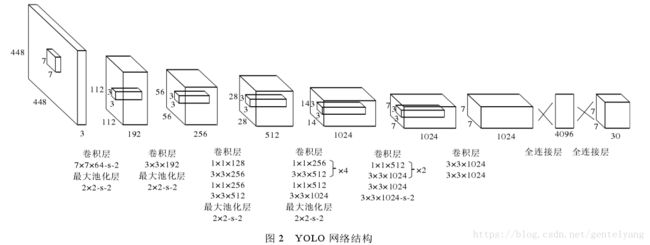
YOLO直接从一张图片中提取特征,来预测每一个Bounding box,最小化和ground turth的误差。由于YOLO是一个端到端的训练,并且中间没有region proposal生成,速度上有很大的提升。
缺点:
YOLOv1使用了end-to-end的回归方法,没有region proposal步骤,直接回归便完成了位置和类别的判定。使得YOLOv1在目标定位上不那么精准,YOLO的检测精度并不是很高。
改进:
使用一系列的方法对YOLO进行了改进,在保持原有速度的同时提升精度得到YOLOv2。
提出了一种目标分类与检测的联合训练方法,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种物体的实时检测。
YOLO9000(主要利用技术)
1:Batch Normalization
2:High Resolution Classifier
3:Convolutional With Anchor Boxes
4:Dimension Clusters
5:Fine-Grained Features
6:Multi-ScaleTraining
7:DarkNet网络模型
1:Batch Normalization
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch 梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
YOLOv2网络通过在每一个卷积层后添加batch normalization,极大的改善了收敛速度同时减少了对其它regularization方法的依赖(舍弃了dropout优化后依然没有过拟合),使得mAP获得了2%的提升。

BN主要分两步走,除了进行normalize,还要进行scale and shift,因为单独的只是normalize,虽然
把每层的数据分布都固定了,但是这种分布不一定是前面一层要学习的分布,这样强行归一化会破坏上一层
的分布,所以BN的第二步就解决了这个问题,在第二步中设置了两个可以学习的变量嘎玛和贝塔,通过利用
这两个可学习变量去还原上一层应该学到的数据分布。BN把 不固定的数据分布转换为了固定的数据分布,而
这种数据分布恰恰是要学习的数据分布,从而加速了网络的训练。
2:High Resolution Classifier
YOLOv2首先修改预训练分类网络的分辨率为448*448,在ImageNet数据集上训练10轮(10 epochs)。这个过程让网络有足够的时间调整filter去适应高分辨率的输入,mAP获得了4%的提升。
3:Convolutional With Anchor Boxes
YOLO(v1)使用全连接层数据进行bounding box预测,丢失较多的空间信息定位不准。
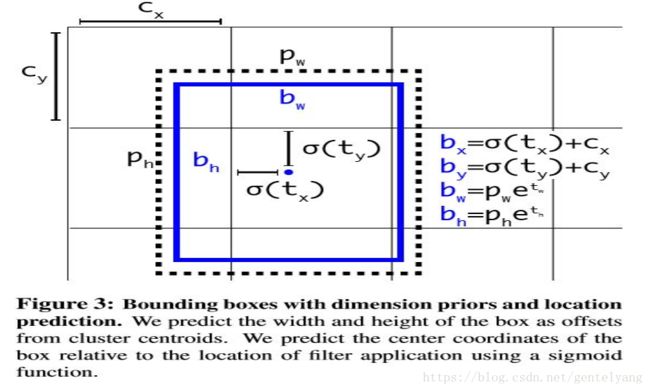
YOLOv2借鉴了Faster R-CNN中的anchor思想: 简单理解为卷积特征图上进行滑窗采样,每个中心预测9种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个cell一一对应。而且用预测相对偏移(offset)取代直接预测坐标简化了问题,方便网络学习。
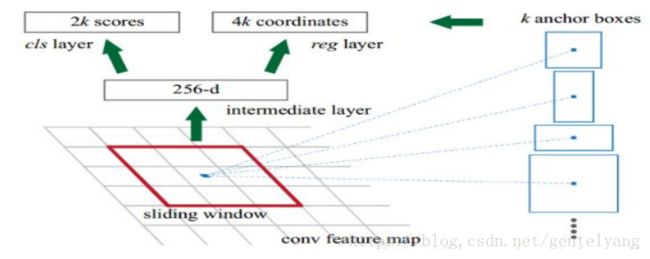
YOLOv2中,不再让类别的预测与每个cell(空间位置)绑定一起,而是让全部放到anchor box中。
4:Dimension Clusters
Faster-RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),为了让其一开始就选择更好的、更有代表性的先验boxes维度,提出了K-means聚类方法,通过对数据集中的ground true box做聚类,找到ground true box的统计规律。以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。
移除全连接层,使用 anchor boxes 取预测 bounding boxes。
较大的 boxes会比较小的boxes产生更多的error,聚类结果可能会偏离。
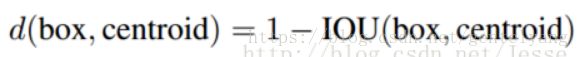
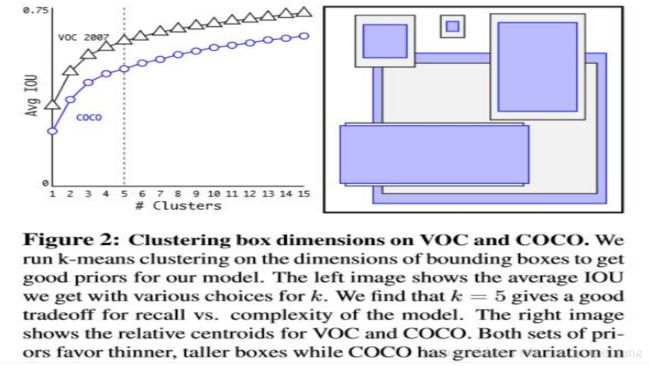
随着k的增大,IOU也在增大,但是复杂度也在增加。所以平衡复杂度和IOU之后,最终得到k值为5。
5种boxes的Avg IOU(61.0)就和Faster R-CNN的9种Avg IOU(60.9)相当。 说明K-means方法的生成的boxes更具有代表性,使得检测任务更好学习。
5:Fine-Grained Features
YOLOv2使用了一种不同的方法,简单添加一个 passthrough layer,把浅层特征图连接到深层特征图。
6:Multi-ScaleTraining
不同于固定网络输入图片尺寸的方法,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320 * 320,最大的尺寸为608 * 608。 调整网络到相应维度然后继续进行训练。
7:DarkNet网络模型
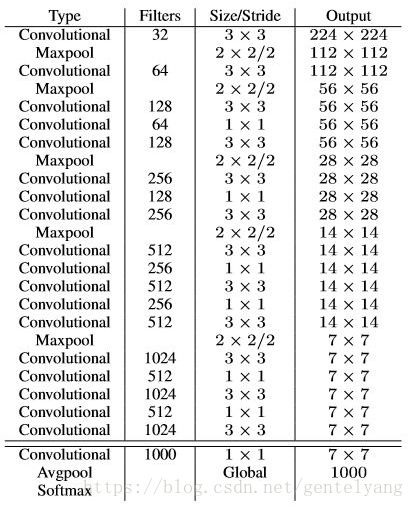
VGG:
224 * 224的图片进行一次前向传播,其卷积层就需要多达306.9亿次浮点数运算。
Darknet-19处理一张照片需要55.8亿次运算,darknet利用avgpool代替了全连接
层,减少了大量参数。
分类与检测
Training for classification
在1000类的ImageNet数据集上训练160次;
SGD;
lr=0.1;
polynomial rate decay =4;
weight decay = 0.0005;
momentum=0.9;
高分辨率下训练的分类网络在top-1准确率76.5%,top-5准确率93.3%。
Training for detection
预测5种bounding boxes,每个bounding box包含5个坐标值和20个类别,所以总共是5 * (5+20)= 125个输出维度。
总结:
YOLO2在YOLO的基础上提出了许多改进,提高了速度和准确率,基于darknet-19模型,除去完全连接层,增加了Convolutional With Anchor Boxes, Dimension Clusters, Direct location prediction等等。YOLO9000是现目标检测领域的state-of-the-art。