深入浅出的TensorFlow可视化工具TensorBoard用法教程(一)
作为TensorFlow的一项极其亮眼的功能,TensorBoard给我们提供了极其方便而强大的可视化环境。它可以帮助我们理解整个神经网络的学习过程、数据的分布、性能瓶颈等等。
1.TensorBoard的主要功能
- 生成折线图
- 展示图像
- 播放音频
- 生成直方图
- 观察神经网络(数据流图)
- 数据降维分布图
1.1生成折线图
当我们要对模型的正确率、loss值、学习速度等标量进行可视化时,经常会用到折线图。
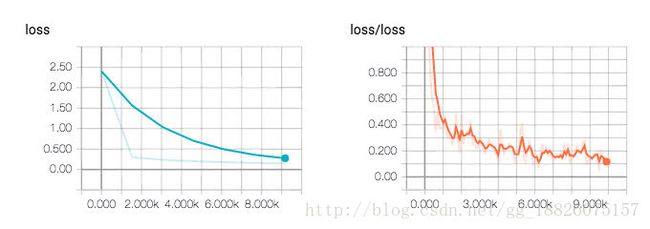
上面是在训练MNIST文字识别模型时,对各阶段的日志记录进行可视化后所得到的折线图(左侧是测试集,右侧是训练集),可以看到loss值在逐步减少,模型的学习正在往好的方向发展。
1.2展示图像
下面是以及其友好的方式展示MNIST的训练集数据的示例截图。

在我们要进行Data Augmentation之前,十分有必要进行数据验证和数据清洗,此时TensorBoard就能给我们带来不少的便利。
1.3播放音频
与展示图像类似,这项功能在数据验证和清洗时十分有用,甚至可以进行音量的调节和音频的下载。
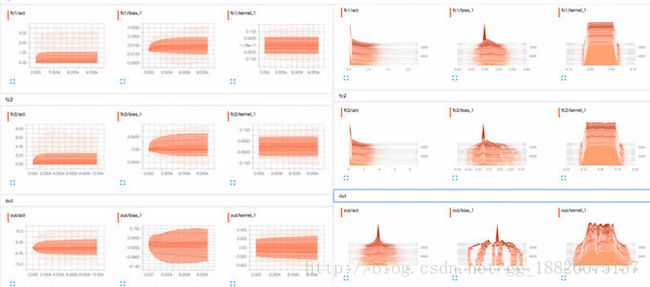
1.4生成直方图
当我们想知道神经网络各层的权重和偏移量的初始值,以及它们在各阶段是如何发生变化的,从而确认到底有没有发生梯度消失的“悲剧”,可以利用这项功能。
1.5观察神经网络(数据流图)
如果我们想直观地观察神经网络的结构,从而帮助我们定位模型的性能瓶颈所在,可以像下面这样做。

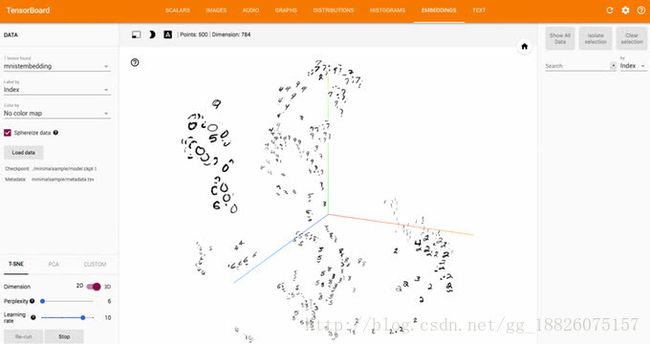
1.6数据降维分布图
下面是利用t-SNE算法对MNIST的图像数据进行降维处理后得到的大致分布图。
2.读懂TensorBoard
2.1记号的含义
首先介绍TensorBoard中各个记号到底代表什么意思
| 记号 | 含义 |
|---|---|
| 某个name scope内部的所有节点,双击可以看到内部详情 | |
| 不连续的节点序列 | |
| 单个节点(变量) | |
| 单个节点(常量) | |
| 统计信息summary节点 | |
| 各操作间的数据流 | |
| 各操作间的控制流 | |
| 输入张量转换节点的引用 |
2.2name scope和node
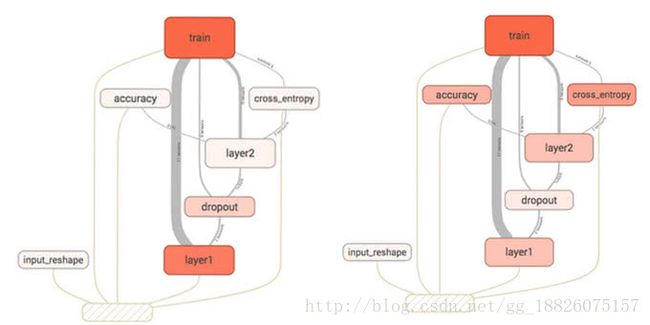
随着神经网络越发复杂,节点数量会发生爆炸式增长,这时候使用多层name scope把它们进行管理相当有必要,尤其是在调参和debug阶段。
下面这幅图可以清晰地展示name scope在TensorBoard发挥的巨大作用:

编程写法也相当简单:
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
tf.summary.scalar('loss', loss)
那么,最终计算并输出的loss的完整名称就为loss/loss。
2.3Device View
Device View表示的是各个阶段GPU和CPU的占用情况,如下图所示,绿色的是GPU,蓝色的是CPU。

2.4计算资源·内存资源
如下图所示,左边的是内存使用率情况,右边的是计算资源使用率情况,他们的值越高,图的颜色就越深。
于是,我们就可以得知cross_entropy节点对于内存的消耗并不高,但是却十分考验硬件的计算能力。
编程写法十分简单明了,对tf.FileWriter添加tf.RunMetadata即可:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict={x: ..., y: ...},
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
2.5Tensor的维度
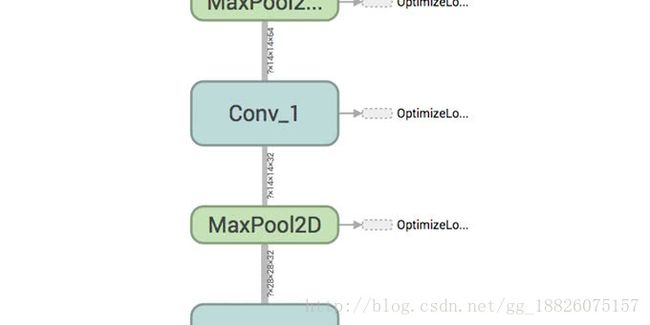
仔细观察计算图中连接各节点的边,就可以发现上面写着有对应Tensor的维度。
如下图,我们可以确认卷积神经网络的Convolution层和Pooling层的参数数量到底是否正确。
3.Summary操作
3.1标量
tf.summary.scalar('loss', loss)
这里,第一参数时标量名,第二参数是标量值
3.2直方图
tf.summary.histogram('bias', bias)
3.3图像
tf.summary.image('preprocess', tf.reshape(images, [-1, 28, 28, 1]), 10)
这里解释一下第二参数的含义,reshape里面的四个参数分别代表[图像数, 每幅图的高度, 每幅图的宽度, 每幅图的通道数],-1表示根据实际数据(在这里是images)进行动态计算,上面的10表示最多展示十幅图。
3.4音频
tf.summary.audio('audio', audio, sampling_frequency)
audio是一个三维或者二维tensor,含义是[音频数, 每个音频的帧数, 每个音频的通道数]或者[音频数, 每个音频的帧数]。
sampling_frequency从名字就可以看出来了,就是音频的采样率。