cv2机器学习-K均值聚类(KMeans)
本篇博客主要介绍cv2模块机器学习部分中的K均值聚类(KMeans)。
cv2.kmeans(data, K, bestLabels, criteria, attempts, flags, centers=None)
输入参数:
data:np.float32类型的数据,每个特征应该放在一列。
K:聚类的最终数目。
bestLabels:预设的分类标签,没有的话就设置为None。
criteria:终止迭代的条件,当条件满足时算法的迭代就终止。它应该是一个含有三个成员的元组。
attempts:重复试验kmeans算法次数,将会返回最好的一次结果。
flags:初始类中心选择,有两个选择:cv2.KMEANS_PP_CENTERS 和 cv2.KMEANS_RANDOM_CENTERS
输出参数:
compactness:紧密度,返回每个点到相应聚类中心距离的平方和。
labels:标志数组。
centers:有聚类中心组成的数组。
一个特征的数据示例代码:
# encoding:utf-8
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 生成测试数据
x = np.random.randint(25, 100, 25)
y = np.random.randint(175, 255, 25)
# print(x)
# print(y)
# 矩阵的合并
z = np.hstack((x, y))
# print(z)
# 将横向量变换为列向量
z = z.reshape((50, 1))
# print(z)
z = np.float32(z)
# print(z)
plt.hist(z, 256, [0, 256]), plt.show()
# 使用kmeans进行聚类分析,设置终止条件为执行10次迭代或者精确度epsilon=1.0
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
flags = cv2.KMEANS_RANDOM_CENTERS
# 运用kmeans
# 返回值有紧密度、标志和聚类中心。标志的多少与测试数据的多少是相同的
compactness, labels, centers = cv2.kmeans(z, 2, None, criteria, 10, flags)
A = z[labels == 0]
B = z[labels == 1]
'''
根据数据的标志将数组分为两组,
A组用红色表示
B组用蓝色表示
中心用黄色表示
'''
plt.hist(A, 256, [0, 256], color='r')
plt.hist(B, 256, [0, 256], color='b')
plt.hist(centers, 32, [0, 256], color='y')
plt.show()
运行结果:
测试数据:

聚类结果:

多个特征的数据示例代码:
# encoding:utf-8
import numpy as np
import cv2
import matplotlib.pyplot as plt
X = np.random.randint(25, 50, (25, 2))
Y = np.random.randint(60, 85, (25, 2))
Z = np.vstack((X, Y))
Z = np.float32(Z)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret, labels, center = cv2.kmeans(Z, 2, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
A = Z[labels.ravel() == 0]
B = Z[labels.ravel() == 1]
plt.scatter(A[:, 0], A[:, 1])
plt.scatter(B[:, 0], B[:, 1], c='r')
plt.scatter(center[:, 0], center[:, 1], s=80, c='y', marker='s')
plt.xlabel('Height'), plt.ylabel('Weight')
plt.show()聚类结果:

颜色量化:
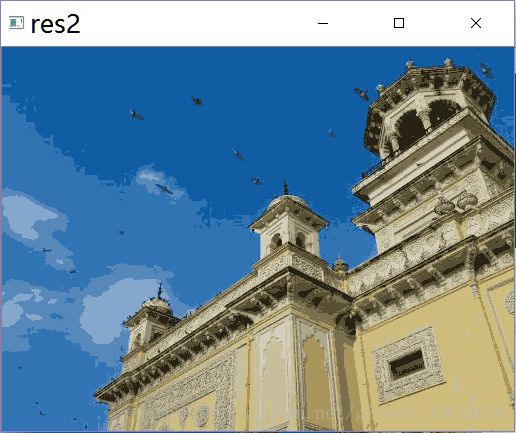
颜色量化是减少图片中颜色数目的一个过程。在需要减少内存损耗或显示设备智能显示很少的颜色时需要用到颜色量化。使用K均值聚类来完成颜色量化,在聚类完成后,使用聚类中心的颜色来代替与其同组的像素值。
示例代码1:
# encoding:utf-8
import numpy as np
import cv2
img = cv2.imread('../data/home.jpg')
Z = img.reshape((-1, 3))
Z = np.float32(Z)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 14
ret, label, center = cv2.kmeans(Z, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv2.imshow('res2', res2)
cv2.waitKey(0)
cv2.destroyAllWindows()
测试图片1:

测试结果1:
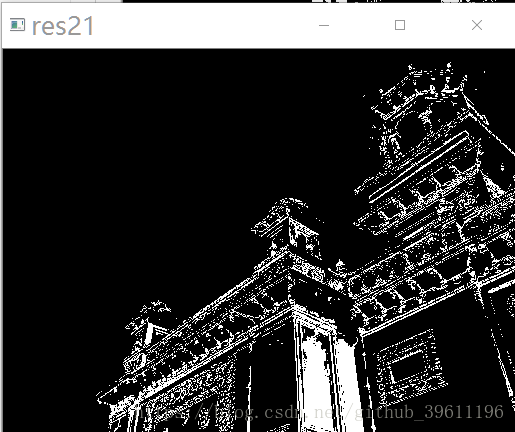
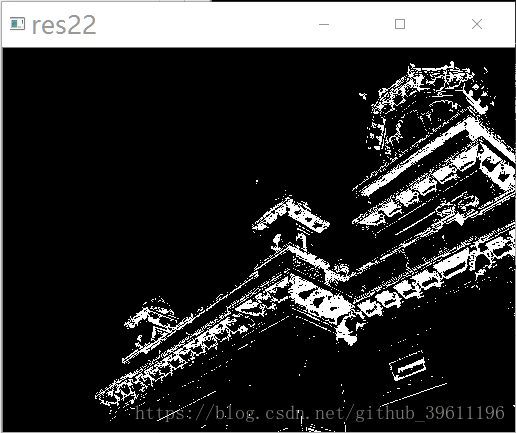
示例代码2:
import numpy as np
import cv2
img = cv2.imread('../data/home.jpg')
Z = img.reshape((-1, 3))
Z = np.float32(Z)
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret, label, center = cv2.kmeans(Z, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# 分离颜色
for y in range(len(center)):
a1 = []
for i, x in enumerate(label.ravel()):
if x == y:
a1.append(list(Z[i]))
else:
a1.append([0, 0, 0])
a2 = np.array(a1)
a3 = a2.reshape((img.shape))
cv2.imshow('res2' + str(y), a3)
cv2.waitKey(0)
cv2.destroyAllWindows()测试数据2:
测试结果2: