【模型训练】如何选择最适合你的学习率变更策略
首发于微信公众号《有三AI》
【模型训练】如何选择最适合你的学习率变更策略
如果让我投票给深度学习中,最不想调试,但又必须要小心调试的参数,毫无疑问会投给学习率,今天就来说说这个。
01 项目背景
我们选择了GHIM-10k数据集,这是一个图像检索数据集,包含20个类别,分别是日落,船舶,花卉,建筑物,汽车,山脉,昆虫等自然图像,各个类别拥有较好的多样性,而类别之间也有比较好的区分度。数据集共10000张图像,每个类别包含500张JPEG格式的大小为400×300或300×400的图像。
如下图就是其中的烟花类别。

定义了一个6层的卷积神经网络,网络结构如下:
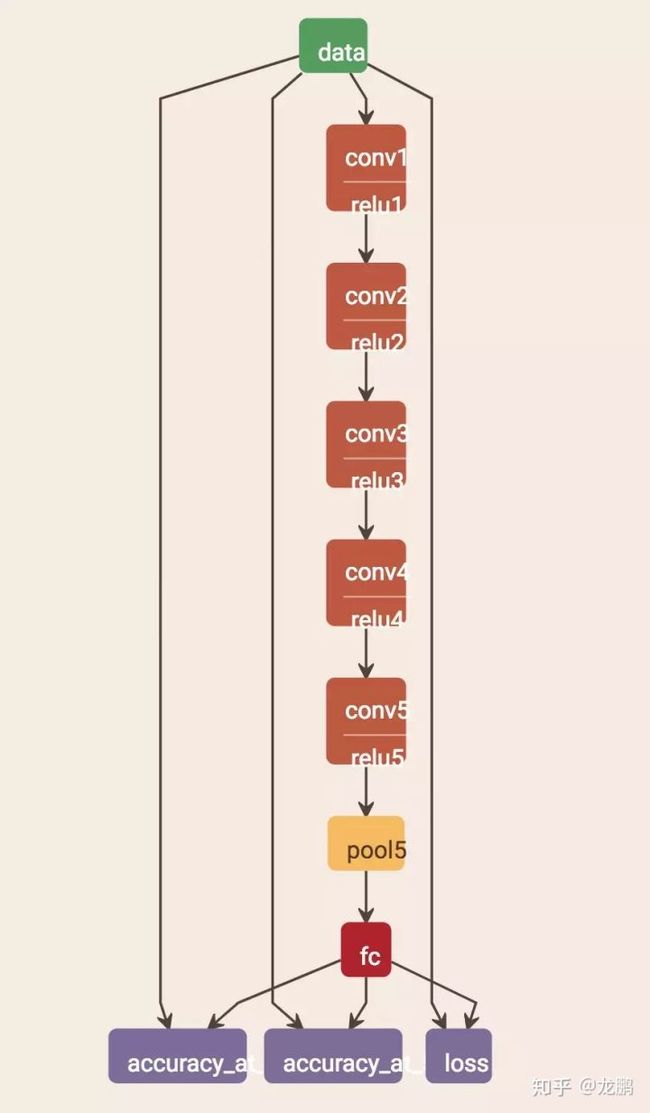
细节咱就不多说,如果你想复现本文结果,可以发送关键词“有三AI训练营12-16”到后台获取网络配置等文件。
02 学习率变更策略
学习率是一个非常重要的参数,可以直接影响模型的收敛与否。不同的学习率变更策略也会影响最终的迭代结果。
下面以sgd优化方法,来介绍各种策略。caffe框架中的策略包括fixed,step,exp,inv,multistep,poly,sigmoid。

2.1 fixed
fixed,即固定学习率,这是最简单的一种配置,只需要一个参数。
lr_policy: "fixed"
base_lr: 0.01

如上图,在整个的优化过程中学习率不变,这是非常少使用的策略,因为随着向全局最优点逼近,学习率应该越来越小才能避免跳过最优点。
2.2 step
采用均匀降低的方式,比如每次降低为原来的0.1倍
lr_policy: "step"
base_lr: 0.01
stepsize: 10000
gamma:0.1
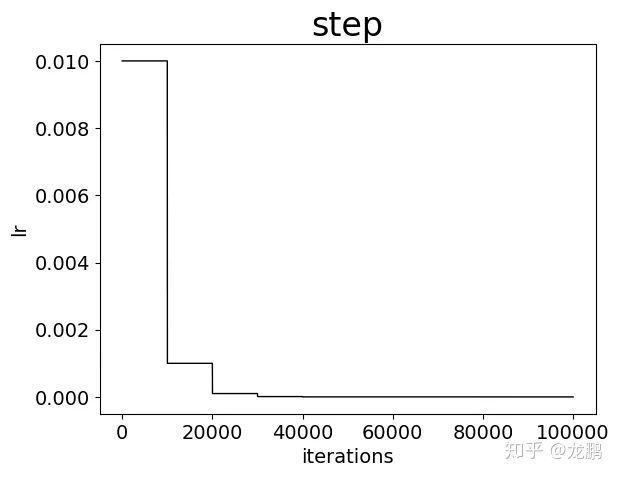
这是非常常用的一个学习率迭代策略,每次将学习率降低为原来的一定倍数,属于非连续型的变换,使用简单,而且效果通常较好。
不过从上图也可以看出,其实学习率的变化一点都不平滑。
2.3 multistep
采用非均匀降低策略,指定降低的step间隔,每次降低为原来的一定倍数。
lr_policy: "multistep"
gamma: 0.5
stepvalue: 10000
stepvalue: 30000
stepvalue: 60000
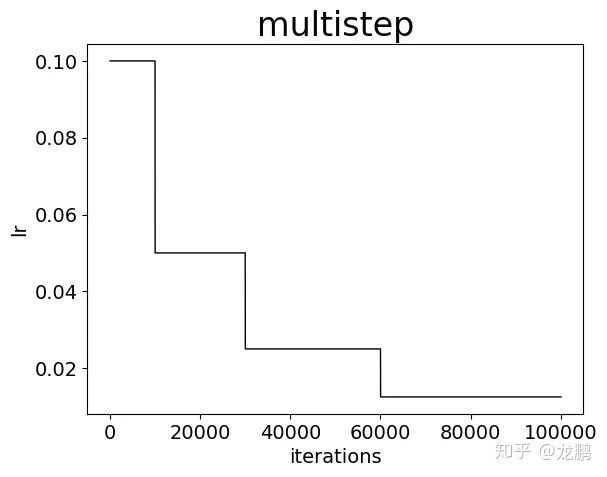
这是比step更加复杂的策略,也是采用非连续型的变换,但是变换的迭代次数不均匀,也是非常常用的策略,需要经验。
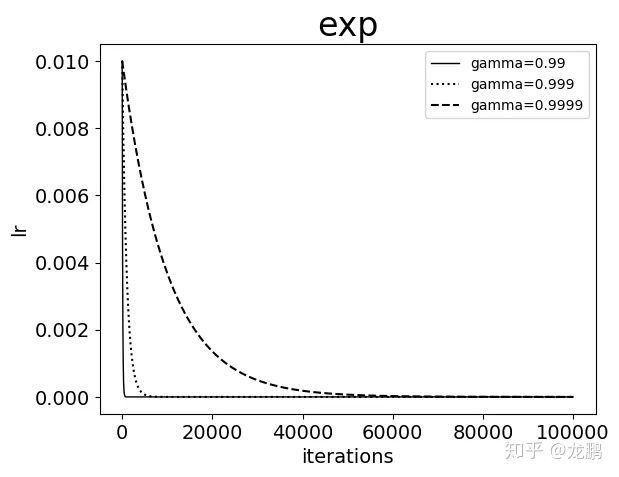
2.4 exp
这是一种指数变化,new_lr = base_lr * (gamma^iter),可知这是连续变化,学习率的衰减非常的快,gamma越大则衰减越慢,但是因为caffe中的实现使用了iter作为指数,而iter通常都是非常大的值,所以学习率衰减仍然非常快。
2.5 inv
new_lr = base_lr * (1 + gamma * iter) ^ (- power),可以看出,也是一种指数变换,参数gamma控制曲线下降的速率,而参数power控制曲线在饱和状态下学习率达到的最低值。

2.6 poly
new_lr = base_lr * (1 – iter/maxiter) ^ (power),可以看出,学习率曲线的形状主要由参数power的值来控制。当power = 1的时候,学习率曲线为一条直线。当power < 1的时候,学习率曲线是凸的,且下降速率由慢到快。当power > 1的时候,学习率曲线是凹的,且下降速率由快到慢。
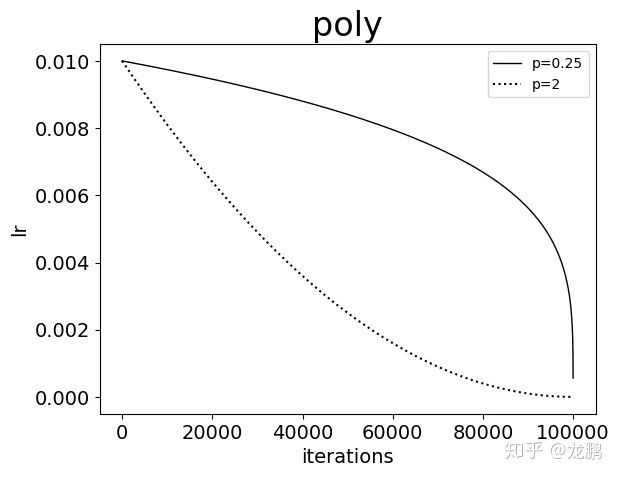
2.7 sigmoid
new_lr = base_lr *( 1/(1 + exp(-gamma * (iter - stepsize))))
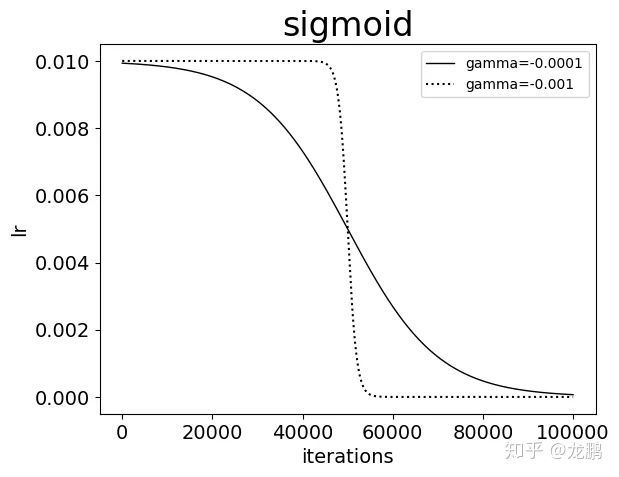
参数gamma控制曲线的变化速率。gamma必须小于0才能下降,而这在caffe中并不被支持。
究竟这些策略的实际表现结果如何呢?请看下面的实验结果。
03 实验结果
下面就展示以上的学习率策略下的实验结果,由于type=sigmoid不能进行学习率的下降,所以不进行对比。学习率的具体变更方式如下。
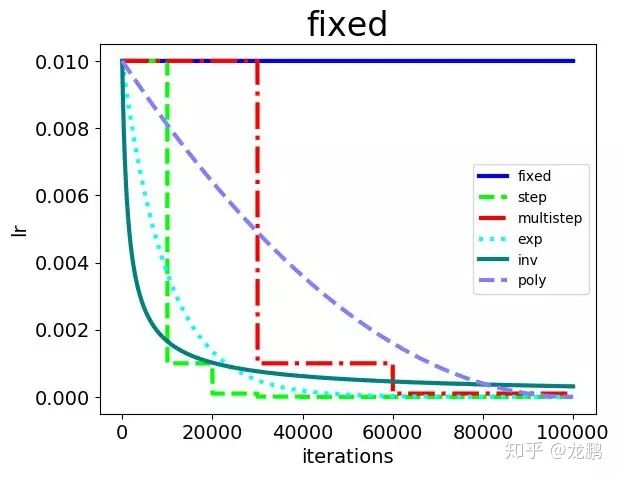
训练数据集大小9000,batchsize=64,可知10000次迭代时,epoch=64*10000/9000>70,在该学习率下应该已经充分训练了,实验结果如下。
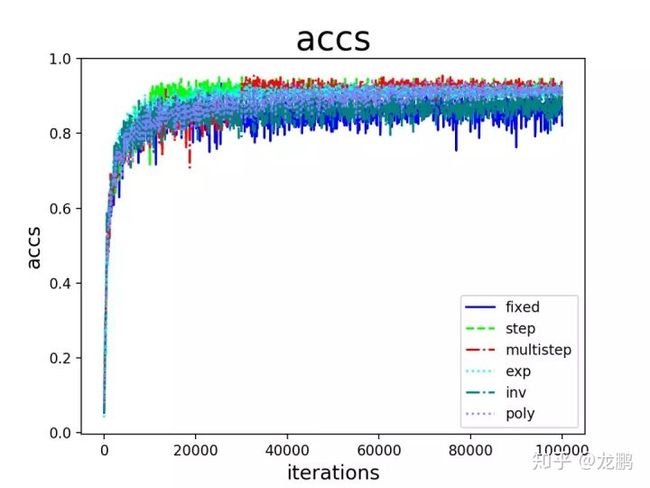
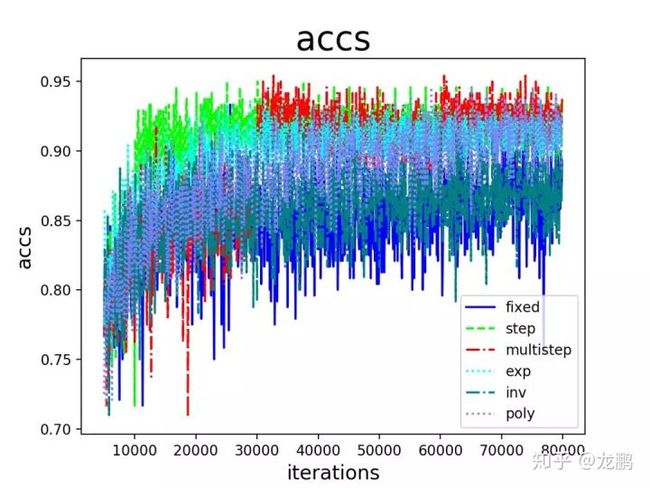
收敛的结果如上,可知道都得到了收敛,但是效果不同。我们在这里要下几个结论,虽然只有一个案例,但是根据笔者多年使用经验,确实如此。
- step,multistep方法的收敛效果最好,这也是我们平常用它们最多的原因。虽然学习率的变化是最离散的,但是并不影响模型收敛到比较好的结果。
- 其次是exp,poly。它们能取得与step,multistep相当的结果,也是因为学习率以比较好的速率下降,操作的确很骚,不过并不见得能干过step和multistep。
- inv和fixed的收敛结果最差。这是比较好解释的,因为fixed方法始终使用了较大的学习率,而inv方法的学习率下降过程太快,这一点,当我们直接使用0.001固定大小的学习率时可以得到验证,最终收敛结果与inv相当。
在此问大家一个问题,你觉得上面的模型,收敛到最好的状态了吗?不妨后台留言讨论。

04 总结
今天只是小试牛刀,也挖了很多的坑给大家(我们以后会填上的)。如果不是为了刷指标,很多时候,学习率变更策略不太需要精挑细选,比如上面的step和multistep,实际表现差不多,笔者常使用multistep,虽然这确实是个经验活儿,不过再白痴也总不能傻到用fixed策略去训练。
否则,其他的提高精度的措施做的再到位,也很可能因此而废。至于exp,inv,poly什么的,鄙人经验,貌似中看不中用。
那adam怎么样呢?
转载请留言,侵权必究
本系列的完整目录:
【模型解读】从LeNet到VGG,看卷积+池化串联的网络结构
【模型解读】network in network中的1*1卷积,你懂了吗
【模型解读】GoogLeNet中的inception结构,你看懂了吗
【模型解读】说说移动端基准模型MobileNets
【模型解读】pooling去哪儿了?
【模型解读】resnet中的残差连接,你确定真的看懂了?
【模型解读】“不正经”的卷积神经网络
【模型解读】“全连接”的卷积网络,有什么好?
【模型解读】从“局部连接”回到“全连接”的神经网络
【模型解读】深度学习网络只能有一个输入吗
【模型解读】从2D卷积到3D卷积,都有什么不一样
【模型解读】浅析RNN到LSTM
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!
