循环神经网络RNN(Recurrent Neural Network)
循环神经网络的好处:建立神经网络架构很灵活。

看看上面这个图左边第一个,红色这个框是得到的一个固定大小的向量,绿色这个框处理它,然后得到一个固定大小的向量(蓝色这个框)。所以,会有一个固定大小的图像进入网络,然后输出一个固定大小的向量,输出的向量是一个class score..
在循环神经网络中,我们可以采用不同的顺序实现,比如从输入开始或者从输出开始,或者两者同时开始。举一个图像字幕的例子,
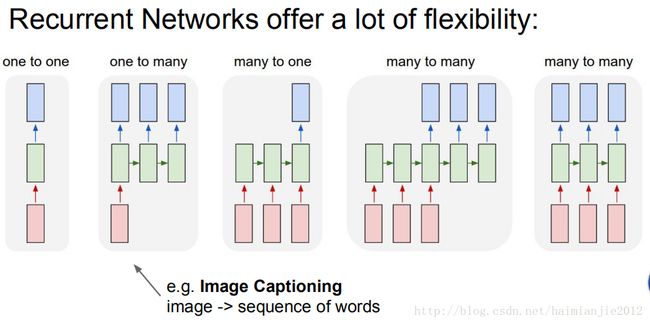
你得到了一个固定大小的图像,通过循环神经网络,我们会生成一些按顺序排列的描述图像内容的词。这些词会形成一句话,这句话就是这幅图的描述。
循环神经网络也可以用在情感分类中,我们来举游说的例子,

我们会处理一定数量的按顺序排列的词,然后试着去把这个句子中的词按照正面情感和负面情感分类。
在用机器进行语言翻译时,我们也可以用到循环神经网络:

我们需要让这个网络把这些单词,比如英文单词翻译成中文单词,所以我们把这些词放在循环神经网络中,通常这被称为从一个序列翻译到另一个序列(seq2seq)。
最后一个例子是视频分类,

把视频中的每一帧图像都按照一定数量的类来分类,并不希望当前时间多对应的当前图片的函数,而是希望当前时间之前所有图片的函数。
即使你没有输入或输出的顺序,你也可以用到循环神经网络。
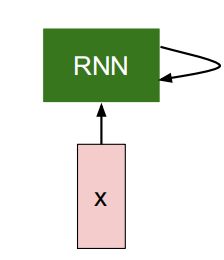
上图是一个循环神经网络的本质,绿色的框,它自己有一个状态,并定期地接受。所以在每一个时间点都有内在的状态,然后通过每个时间点所接收内容的根据函数来修改自己的状态。RNN会根据它在接收输入时状态的参与程度来修改它的行为。
我们还需要关注基于RNN状态所生成的输出,

RNN就只是中间的一个块儿。它有一个状态,可以随时间变化接收向量。在实际应用中,可以根据它上方的状态进行假设。
那么整个完整的过程应该是这样的:RNN有某种状态,我们记为向量H.因为这可以是许多向量的集合,所以这是一个更加综合的状态。我们现在要根据之前的隐藏状态h之前的时间t-1,以及现在的输入向量xt列一个方程。方程中还需要一个函数,我们称之为递归函数(recurrence function),递归函数会有一个参数w,当我们改变w时RNN就会有不同的表现,但是我们希望RNN有一个恒定的表现,所以我们需要训练递归函数的w。

在每个时间步长中我们都要用同一个函数,同一个固定大小的fw,我们按顺序使用循环回归网络,又不用去管这个序列的大小。无论输入或输出的序列有多长,在每一个事件步长中我们用的都是同一个函数。
在可用的最简单的循环中建立fw函数最简便的方法就是vanilla RNN.循环神经网络的状态就是这个隐藏状态(hidden state)h,我们还会得到一个循环方程式。这个方程式告诉你,怎么来更新你的隐藏状态。这需要用到之前的隐藏状态,还有现在的输入xt.

字符级语言模型(character-level language model),这是我最喜欢的解释RNN的方法之一,因为它直观又有趣

它的工作原理是:把一系列的字符输入到循环神经网络中,在每个时间步长里,我们都会要求循环神经网络来预测下一个字符是什么。所以,它所看到的所有字符来预测下一个字符是什么。举一个简单例子,我们有个训练序列hello,词汇字符为[h,e,l,o],我们试着在这组训练数据中利用循环神经网络,来学习预测序列中下一个字符。
该方法开始运作,将每个字符按照先后不同时间点转化为一个循环神经网络,

第一步是字符h,然后是e,我们就这样完成了H-E-L-L。我们来使用一个词向量——one hot向量,代表了字符的顺序和词汇,
我们来看一下递推公式,在每一个测试中我们从h开始,然后我们要求计算隐含层,每一个时间步骤使用我们的递推公式。假设隐含层中只有三个数字,那么我们用一个三维向量基本上在时间点上总结了所有的字符,直到最后一个。
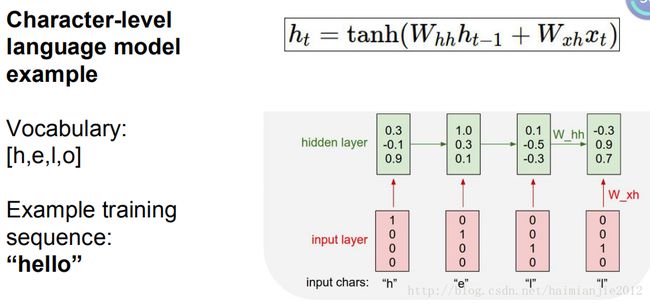
每个时间步骤上都有隐含层,现在我们可以预测每个时间步骤所连接的序列中的下一个字符是什么,
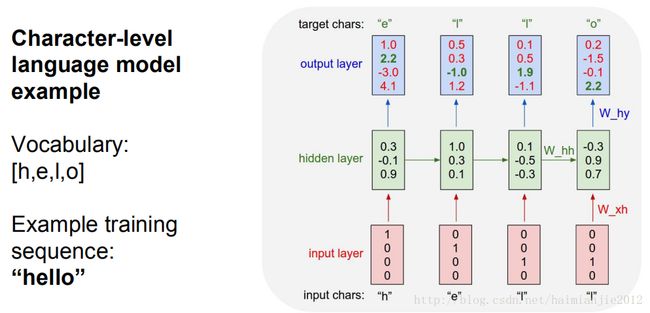
例如,因为这个单词有四个字符,我们预测在每个时间点有四个数字,第一个位置对应字母h.RNN在这时候的权重设置计算到它现在的字母以及下一个位置字符,那么可以推断,H对应后一个字符的权重是1.0,E对应后一个字符的权重是2.2,L是-3.0,O是4.1。我们知道e是h后面那个字符,事实上变为绿色的那个2.2是正确答案,我们希望这个值是高的,所以我们要让其他值比较低。
每个时间步骤,我们基本上有一个大的softmax分类器,这些大的softmax分类器的每个结束后会接着下一个字符,在每个点上我们知道下一个字符是什么。我们只是得到了从上到下的损失,并且通过这张图流通,向后至所有的箭头。我们要得到所有权重矩阵的梯度,我们将会知道如何转移矩阵,那么当前的问题来自于error,所以我们要会塑造这些权重。
每个递归场景都有自己的功能,每个时间步骤都有一个wxh和why,我们在这个图解中用了四次wxh和why。
如果这是一个较长的序列,顺序是没有关系的,因为每一点都是按照时间顺序的。
下面通过一个具体例子来看看循环神经网络是如何训练的,该例子min_char_rnn.py代码在github之上,https://gist.github.com/karpathy/d4dee566867f8291f086
在代码开始处,使用numpy加载文本数据,我们在这里收集了大量的字符序列。然后我们创建映射字典,映射字符索引,从索引能找到字符,

然后是初始化,

seq_length序列的长度是25,如果数据集很大我们不能一次性把所有数据都放入循环神经网络,要让他变为某一个时间片只有25个字符的数据块,并且每次都按时通过25个字符,因为我们负担不起太长的向后传播。
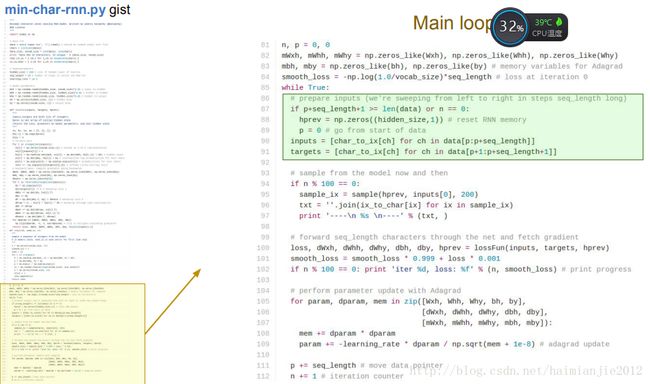
上图所示代码是对数据进行采样。
接下来是损失函数,损失函数的输入中,Hprep有一个缺点,他的状态向量来自于前一个数据块。

所以我们要分批进行25个字符的区块,而且我们可以跟踪在25个字符结尾的是什么情景,以至于当在向后传播相遇时,我们可以看到H最初的状态
,
损失函数包括前向传播和后向传播两部分,红色为前向,绿色为后向,

后向传播,需要从第25个序列通过隐含层,直到第一个隐含层。

这里反向通过了一个softmax函数,
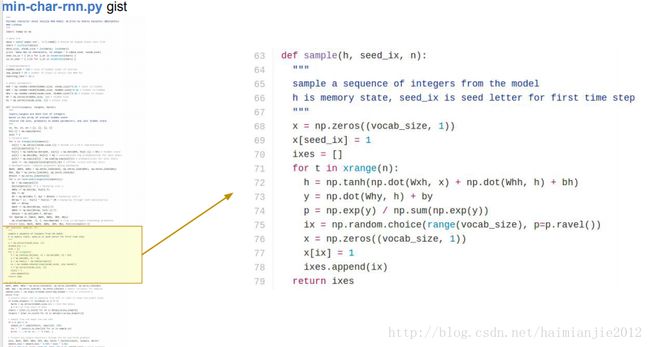
我们使用这个方法,基于我们之前训练出来的模型,生成新的文本。
求梯度时,有25个softmax分类器,同时计算梯度,然后把所有梯度求和。
RNN中使用正则化并不常见,

把这篇文章输入RNN,我们不关注文章的内容,只知道是一些字符组成的句子,训练RNN,然后让训练好的RNN写一篇差不多的文章。

举个例子,用莎士比亚的所有作品当训练集,其实是许多字符构成的序列,将其输入到RNN中,然后用RNN预测字符,这样你就可以为莎士比亚的粉丝写文章了。开始,RNN中有许多随机参数,网络只会胡乱预测,预测一些随机字符,但是随着时间的进行,RNN渐渐学会打空格,学会拼单词,学会用引号,学会用很短的词汇,……最后,基于这种字符集的网络模型,你可以无限生成莎士比亚的文章。我们可以将任何难懂的内容丢给字符级的RNN去学习。例如,我认为ilinux的源码相当难读懂……
min_char_rnn.py只是用于理解RNN的原理,大型样例则是使用torch实现的。
LSTM是一种复杂的RNN,这里只介绍LSTM的工作方式。

我们用char_RNN去学习一些文本,RNN去学习这些文本和代码,我们发现某些特定的单元以及RNN隐含层的状态,图中的颜色标识这些单元是否“兴奋”,你可以看到许多隐含层的状态很难去理解。很多隐含层的状态时而“兴奋”,时而“沉默”,显得很奇怪。

但是有些单元表达的信息是可以理解的,对于像引号检测这样的单元而言,RNN用一部分隐含层对引号进行跟踪,以分辨目前在引号中还是引号外。这里用100个序列进行训练,但是我们引号之内的字符包含250个,我们只在100层上进行反向传播,这100层才是这个单元的学习区间,因为它不知道长于100字符的情况,但是这里显示你能对长度小于100字符的序列进行学习,然后将情况合理地推广到更长的序列。所以对于长于100字符的序列,模型依然能凑效,即使模型只能容忍长度不到100个字符的单元。

这是另一个数据集,这是列夫。托尔斯泰的《战争与和平》。在这个数据集中,大概每80个字母中就有一个新行字母(new line character),还有一个新行的追踪单元(tracking cell)。假如它从1开始,随着时间慢慢衰减,这样的一个单元在最后预测新行字母时是非常有用的,因为我们需要数80步,它会知道什么时候新行字母可能出现。

我们还探索了能够追踪if条件句的单元,能够跟踪引用语和字符串的单元。
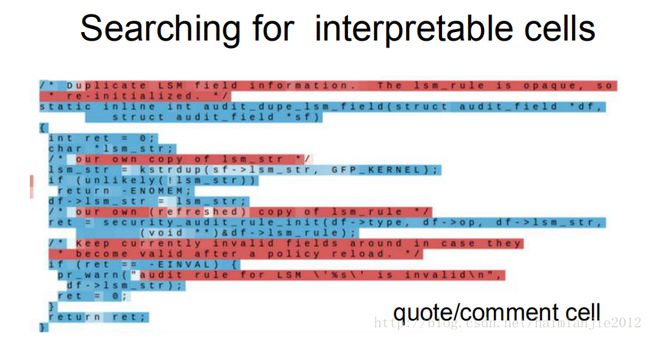
能够跟踪代码深度的单元。

你可以在RNN中找到各种各样的单元,他们都是通过反向传播得到的。这个LSTM大概有2100个单元。

图片描述,用一个句子描述图片。这些RNN网络在句子形成的过程中起到了很大的作用,我将要描述的特别模型大概是一年以前的工作,

卷积神经网络负责处理图像,RNN负责建立序列模型。CNN使用的是VGGNet,RNN网络有一个特殊的起始向量,比如300维向量,我们将它放在迭代运算的初始端,告诉RNN这是序列的开始,然后我们要采用递归公式,
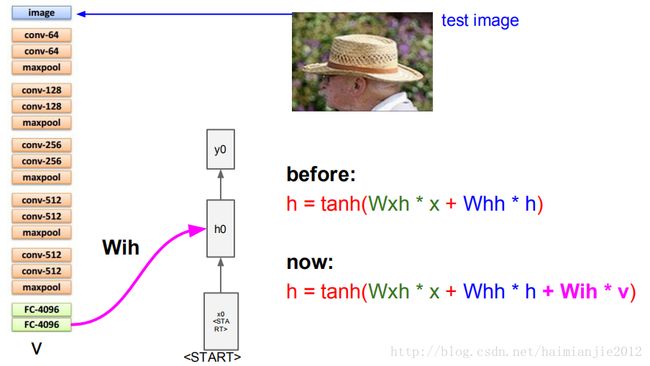
一般情况下,我们的操作是tanh(wxh*x+whh*h)这个公式,现在我们需要在RNN中增加额外的条件。当前隐含层状态第一次我们将它初始化为零,暂时可以忽略它,我们额外增加了一项wih*v.向量y0是序列的第一个单词的分布情况,这是RNN已经完成了两项工作,接着需要预测下一个单词,并且需要记住图片的信息,我们需要从softmax中取样,

假如我们从取样的分布中得到最有可能的单词是“稻草”,我们会将“稻草”置入RNN的底部,在这种情况下,我们会采用词汇层面和词嵌入(word embeddings),单词“稻草”和一个300维向量组成了一个映射,这也是我们(需要通过网络)学习的。我们需要学习300维向量所代表的所有单词表中的单词。
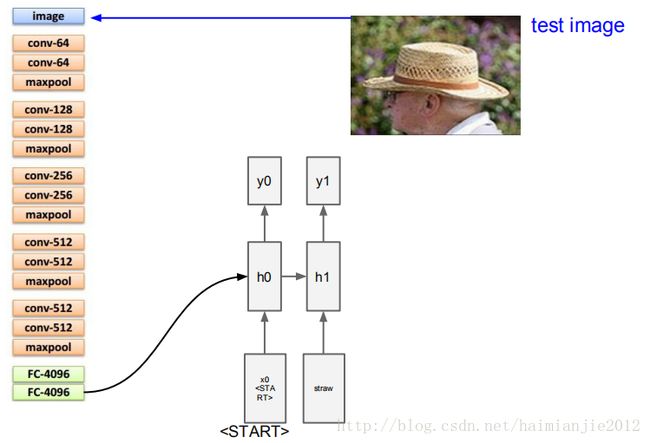
我们将300维的向量置入RNN,再通过y1得到序列中第二个单词的描述。我们得到了所有的这些性质,我们再进行采样,如果帽子是可能性最高的词,然后采用帽子的300维向量放在RNN底部,依此循环直到遇到结束取样的标志,这就相当于一个句子的句号,说明RNN已经停止了生成单词。然后RNN将这个图片描述为“草帽”。