物体分类(一)AlexNet
一、前言
AlexNet是大神Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton三人提出的AlexNet深度卷积神经网络,摘得了2010年ILSVRC比赛的桂冠。虽然第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet。
二、LeNet
LeNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5,5表示5层。LeNet-5 这个网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全连接层,可以说是其他深度学习模型的基础。具体流程是:conv1->pool1->conv2->pool2->fc1,输入图片大小是28 * 28的图像。
三、AlexNet
AlexNet在2012年ImageNet竞赛中以超过第二名10.9个百分点的绝对优势一举夺冠,从此深度学习和卷积神经网络名声鹊起,深度学习的研究如雨后春笋般出现,AlexNet的出现可谓是第一个CNN的个工业解决方案。AlexNet有五层卷积,三层全连接网络,最终的输出层是1000分类的softmax。AlexNet利用了两块GPU进行计算,大大提高了运算效率,并且在ILSVRC-2012竞赛中获得了top-5测试的15.3%error rate, 获得第二名的方法error rate 是 26.2%。虽然现在AlexNet用的比较少了,但是研究这篇论文对于理解dropout、ReLu等基本操作非常有帮助,并且当时作者也提到了,因为受制于有限的数据集和GPU限制,并没有达到最好的效果。另外对于AlexNet,我们不仅仅要关心网络实现,更要关注作者在数据增强等方面的处理手段。
论文地址:http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
3.1 输入
和其他CNN网络一样,AlexNet也需要固定大小的输入图片,原始输入大小是256 * 256。给定一个矩形图片,AlexNet首先resize图像,使得短边长度为256,然后从结果中裁剪出中心的256×256的图片。
3.2 网络结构
AlexNet包含八个层——五个卷积层和三个全连接层(其实是11层,还包含3层pooling层),具体如图1所示。无需关心图中的224大小输入,具体细节,待会介绍。
图1 AlexNet网络结构3.3 ReLu激活函数
没有像LeNet那样使用sigmod或者tanh激活函数,AlexNet创造性的使用了ReLu激活函数。因为ReLu在输入大于0时,是线性的,导数不变,反向传播求误差梯度时计算简单,使用ReLU做为激活函数的卷积神经网络比起使用tanh单元作为激活函数的训练起来快了好几倍,对于大型训练集和复杂网络这一点是很重要的,并且使用ReLu可以在很大程度上避免出现“梯度消失”现象。如图2所示,是在一个四层网络上分别采用ReLu(实线)和tanh(虚线)的训练效率对比图。
 图2 ReLu和tanh训练对比
图2 ReLu和tanh训练对比
3.4 多GPU训练
由于当时单GPU内存较小,限制了网络的扩展。因此作者采用了多GPU训练模型,在图1中可以发现在第一层卷积后出现了两个分支,与一个GPU上训练的每个卷积层只有一半的内核数量的网络相比,该方案分别将top-1和top-5错误率分别降低了1.7%和1.2%,并且双GPU网络的训练时间比单GPU网络更少。该部分不是本文介绍的终点,感兴趣的同学可以去阅读原文。
3.5 Local Response Normalization
Local Response Normalization(局部响应归一化)。ReLu由于可以避免“梯度消失”现象,理论上来说不需要进行标准化操作,不过作者在论文中表示采用LRN后可以有助于模型泛化。LRN公式如下:
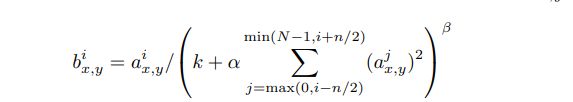
n表示同一个位置下与该位置相邻的内核映射的数量,而N表示这一层所有的内核数(通道数),常数k、n、α和β是超参数,其值由验证集确定;文章使用k=2、n=5、α=![]() 和β=0.75。在某些层中应用relu非线性后,应用了该标准化。输出
和β=0.75。在某些层中应用relu非线性后,应用了该标准化。输出![]() 和输入
和输入![]() 的上标表示的是当前值所在的通道,也即是叠加的方向是沿着通道进行。将要归一化的值
的上标表示的是当前值所在的通道,也即是叠加的方向是沿着通道进行。将要归一化的值![]() 所在附近通道相同位置的值的平方累加起来,基本思路是,假如该层是 13×13×256, LRN 要做的就是选取一个位置,从这个位置穿过整个通道,能得到附近上下的小于等于n个值,并进行归一化。进行LPR的动机是,对于这张 13×13 的图像中的每个位置来说,我们可能并不需要太多的高激活神经元。但是后来,很多研究者发现 LRN 起不到太大作用,现在并不用 LRN 来训练网络。
所在附近通道相同位置的值的平方累加起来,基本思路是,假如该层是 13×13×256, LRN 要做的就是选取一个位置,从这个位置穿过整个通道,能得到附近上下的小于等于n个值,并进行归一化。进行LPR的动机是,对于这张 13×13 的图像中的每个位置来说,我们可能并不需要太多的高激活神经元。但是后来,很多研究者发现 LRN 起不到太大作用,现在并不用 LRN 来训练网络。
3.6 Overlapping Pooling
Overlapping Pooling(重叠池化)。CNN中的池化层汇集了相同内核映射中相邻神经元组的输出。在传统方法中,不管是最大池化还是平均池化相邻池化单元之间互不重叠。假设池化大小是z,池化步长是s,通常情况下z = s。论文中设置了s=2,、z=3,top1和top5的错误率分别降低了0.4%和0.3%,并且采用重叠池化能在一定程度上抑制过拟合。
3.7 网络介绍
如图1,第二,第四和第五个卷积层的内核仅与上一层存放在同一GPU上的内核映射相连。第三个卷积层的内核连接到第二层中的所有内核映射。全连接层中的神经元连接到前一层中的所有神经元。将ReLU应用于每个卷积层和全连接层的输出。第一个卷积核大小是11 * 11 * 3,步长为4,卷积核个数是96,论文中标注输入大小是224 * 224,但是224经过卷积后得到的结果并不是55,大多人认为输入应该是227 * 227,经过11 * 11 * 3的卷积后得到结果是55 * 55 * 96。第二个卷积层将第一个卷积层的输出(LRN以及池化)作为输入,并使用256个(每个卡是128)内核处理图像,每个内核大小为5 * 5 * 48(前一层计算结果是96,但是分在了两块卡)。第三、第四和第五个卷积层是直接相连的,第三个卷积层有384个(每个卡192)核,每个核的大小为3 * 3 * 256;第四个卷积层有384个(每个卡192)内核,每个内核大小为3 * 3 * 192;第五个卷积层有256个(每个卡128)内核,每个内核大小为3 * 3 * 192;两个全连接层各有4096个神经元;然后接入一个1000分类的softmax。现在AlexNet的实现程序在网络层面都不再区分多卡。
3.8 Reducing Overfitting
数据增强
减小过拟合的最简单且最常用的方法就是人为地放大数据集。转换后的图像是使用CPU上的Python代码生成的,在生成这些转换图像的同时,GPU还在训练上一批图像数据,生成的数据并没有落在磁盘上,类似于生产--消费模型。所以这些数据增强方案实际上是很高效的。
AlexNet通过从256 * 256图像中随机提取227 * 227的图像块(及其水平翻转)并在这些提取的图像块上训练网络。在测试时,网络通过提取5个227 * 227的图像块(四个角块和中心块)以及它们的水平翻转(因此总共包括10个块)来进行预测,并求网络的softmax层的上的十个预测结果的均值。第二种数据增强是对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
Dropout
Dropout将隐含层的神经元以一定概率将输出置为0,这种方法被置0的神经元不参与网络的前馈和反向传播。因此,每次给网络提供了输入后,神经网络都会采用一个不同的结构,但是这些结构都共享权重。这种技术减少了神经元的复杂适应性,因为神经元无法依赖于其他特定的神经元而存在。因此,它被迫学习更强大更鲁棒的功能,使得这些神经元可以与其他神经元的许多不同的随机子集结合使用。在测试时,所有的神经元的输出乘以0.5。这与采用大量dropout的网络产生的预测结果分布的几何均值近似。论文在最后两个全连接层上使用了dropout,没有dropout,网络会出现严重的过拟合。不过Dropout大致会使收敛的迭代次数翻倍。
三、AlexNet
ZFNet是2013ImageNet分类任务的冠军,其网络结构没有做改动,只是调整了卷积参数,性能较Alex提升了不少。ZF-Net将AlexNet第一层卷积核由11变成7,步长由4变为2,第3,4,5卷积层转变为384,384,256。
参考资料:
https://www.cnblogs.com/skyfsm/p/8451834.html
https://www.cnblogs.com/wangguchangqing/p/10333370.html
https://blog.csdn.net/hongbin_xu/article/details/80271291