【MXNet】(二十三):实现GoogLeNet
论文原文《Going deeper with convolutions》。
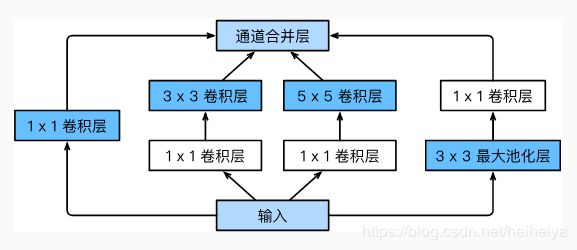
GoogLeNet中的基础卷积块叫作Inception块,下图是一个Inception块的结构。
from mxnet import gluon, init, nd
from mxnet.gluon import nn
class Inception(nn.Block):
def __init__(self, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
self.p1_1 = nn.Conv2D(c1, kernel_size=1, activation='relu')
self.p2_1 = nn.Conv2D(c2[0], kernel_size=1, activation='relu')
self.p2_2 = nn.Conv2D(c2[1], kernel_size=3, padding=1, activation='relu')
self.p3_1 = nn.Conv2D(c3[0], kernel_size=1, activation='relu')
self.p3_2 = nn.Conv2D(c3[1], kernel_size=5, padding=2, activation='relu')
self.p4_1 = nn.MaxPool2D(pool_size=3, strides=1, padding=1)
self.p4_2 = nn.Conv2D(c4, kernel_size=1, activation='relu')
def forward(self, x):
p1 = self.p1_1(x)
p2 = self.p2_2(self.p2_1(x))
p3 = self.p3_2(self.p3_1(x))
p4 = self.p4_2(self.p4_1(x))
return nd.concat(p1, p2, p3, p4, dim=1)下面是GoogLeNet的主体部分。
b1 = nn.Sequential()
b1.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b2 = nn.Sequential()
b2.add(nn.Conv2D(64, kernel_size=1),
nn.Conv2D(192, kernel_size=3, padding=1),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b3 = nn.Sequential()
b3.add(Inception(64, (96, 128),(16, 32), 32),
Inception(128, (128, 192),(32, 96), 64),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b4 = nn.Sequential()
b4.add(Inception(192, (96, 208),(16, 48), 64),
Inception(160, (112, 224),(24, 64), 64),
Inception(128, (128, 256),(24, 64), 64),
Inception(112, (144, 288),(32, 64), 64),
Inception(256, (160, 320),(32, 128), 128),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))b5 = nn.Sequential()
b5.add(Inception(256, (160, 320),(32, 128), 128),
Inception(384, (192, 384),(48, 128), 128),
nn.GlobalAvgPool2D())
net = nn.Sequential()
net.add(b1, b2, b3, b4, b5, nn.Dense(10))构造一个输入看一下各层的尺寸。
X = nd.random.uniform(shape=(1, 1, 224, 224))
net.initialize(force_reinit=True)
for layer in net:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)
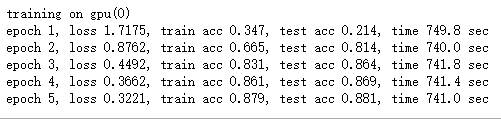
依然使用Fashion-MNIST数据集训练。
lr, num_epochs, batch_size, ctx = 0.1, 5, 64, try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)
train(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)上面程序片段里的几个函数的实现请参考链接:【MXNet】(二十):实现AlexNet。