caffe学习笔记1:转化自己的数据为(leveldb/lmdb)文件
环境:ubuntu16.04 CPU
经过千难万险将环境配置好之后,MNIST数据集也测试过了,MNIST数据集是通过caffe可以直接获取数据集,如果我们要处理自己的数据的话,我们就需要做一些转化了,我们的图像数据往往是图片文件,jpg,jpeg,png等,然而在caffe中我们需要使用的数据类型是lmdb或leveldb,因此我们在对自己的图像数据进行训练/测试之前,需要转换成caffe框架可以直接使用的db文件。
说明:本篇博客是在我看过一些资料之后总结的,一方面分享给大家,希望能给初学者者带来帮助,另外一方面,博主也是小白入门,记录本篇博客也算是作为自己的一个知识总结。
ps:本篇博客将会用两个数据集进行,一个是caffe自带的简单图片,一个是自己制作的简单数据集
caffe自带简单图片样例
1.1:创建自己的图片数据
我们知道caffe自带了两张图片,如下图:
![]()
1.2 创建图片列表清单
这一步我们需要创建自己图片数据集的清单txt文件,这里提供两种方法。
方法1:创建一个sh文件
cd ~/caffe-master/
sudo gedit examples/images/create_filelist.shsudo就是获取管理员权限,gedit是用记事本的方式打开文件,其实在caffe-master/examples/images下并没有create_filelist.sh文件,上述指令就是在上述目录下创建一个空的create_filelist.sh脚本文件,并打开,如下图:

然后将以下代码复制到create_filelist.sh文件中,保存退出。
DATA=examples/images
echo "Create train.txt..."
rm -rf $DATA/train.txt
find $DATA -name *cat.jpg | cut -d '/' -f3 | sed "s/$/ 1/">>$DATA/train.txt
find $DATA -name *bike.jpg | cut -d '/' -f3 | sed "s/$/ 2/">>$DATA/tmp.txt
cat $DATA/tmp.txt>>$DATA/train.txt
rm -rf $DATA/tmp.txt
echo "Done.."代码解释:
>DATA=examples/images 解释:DATA就代表了该路径- rm: remove删除文件
rm -rf $DATA/train.txt 解释:删除该路径下的所有train.txt,注意前面的路径表示- find: 寻找文件
- cut: 截取路径
- sed: 加标注
find $DATA -name *cat.jpg | cut -d '/' -f3 | sed "s/$/ 1/">>$DATA/train.txt
解释:
》》find,在DATA路径下寻找cat.jpg,前面的*号应该是表示任何前缀的意思,意思就是名字的前面不考虑,之后最后面是cat.jpg就算是找到,详情百度find指令的用法。
》》 '|' 这个代表或的意思。
》》cut -d '/' -f3 意思是截取文件名,详情百度cut用法。
》》sed "s/$/ 1/"表示在文件名后加上标注,也就是所谓的label,从0开始,自己人为定义的,注意1前面有个空格,也就是标签和文件名中间有个空格。
》》$DATA/train.txt意思是将以上内容存入train.txt文件中,注意>>的使用,train.txt原本并不存在,系统会自动新建该文件夹,(Ubuntu就是这么6),下一行命令同理。- cat: catenate 将文件内容合并到一个文件里。
cat $DATA/tmp.txt>>$DATA/train.txt 将tmp.txt中的命令合并到train.txt中
然后执行以下命令运行create_filelist.sh,生成对应的train.txt
cd ~/caffe-master/
sudo sh examples/images/create_filelist.sh如下图:

执行结束,在路径~/caffe-master/examples/images/下可以看到生成的train.txt.

打开train.txt文件
sudo gedit train.txt如下图:

这里生成的是train.txt,测试集test.txt和验证集val.txt类似。
注意:这只是个样例,所以数据和配置文件都放在了一起。
方法2:直接使用代码
准备工作:在~/caffe-master/examples/images/路径下新建两个文件夹,cat和bike,然后将cat.jpg移动到cat文件将夹,将fish-bike.jpg移动到bike文件夹,如下图:
执行以下命令
cd ~/caffe-master/examples/images/
ls bike | sed "s:^:bike/:" | sed "s:$: 1:" >> train.txt
会在images目录下生成train.txt文件,然后打开
sudo gedit train.txt如下图:

然后执行以下指令:
ls cat | sed "s:^:cat/:" | sed "s:$: 2:" >> train.txt打开train.txt,如下图:

代码解释:
- ls bike 代表列出该目录下的图片,相当于获取文件名
- sed “s:^:bike/:” 表示给文件名加前缀bike/,该前缀也代表了路径
- sed “s:$: 1:” 表示给文件名加后缀 1,注意有个空格
- train.txt 表示将以上内容放到train.txt下一行代码同理,只是将bike换成cat,同时最后都放到了train.txt下
ps:两种方法其实本质上是一样的,只是表达形式不一样。
1.3 利用清单文件生成对应的db文件
在路径~/caffe-master/tools路径下,存在文件convert_imageset.cpp

编译之后,生成可执行文件convert_imageset,存在于路径~/caffe-master/build/tools/
ps:convert_imageset可以将数据生成的txt文件转换成caffe框架能够直接使用的db文件,将该命令的介绍附在此:
命令行使用格式:
convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME- FLAGS: 图片参数组
- gray: 是否以灰度图的方式打开图片。程序调用opencv库中的imread()函数来打开图片,默认为false。
- shuffle: 是否随机打乱图片顺序。默认为false。
- backend:需要转换成的db文件格式,可选为leveldb或lmdb,默认为lmd。
- resize_width/resize_height: 改变图片的大小。在运行中,要求所有图片的尺寸一致,因此需要改变图片大小。 程序调用opencv库的resize()函数来对图片放大缩小,默认为0,不改变。
- check_size:检查所有的数据是否有相同的尺寸。默认为false,不检查。
- encoded:是否将原图片编码放入最终的数据中,默认为false。
- encode_type: 与前一个参数对应,将图片编码为哪一个格式:‘png’,’jpg’等。
- ROOTFOLDER/: 图片存放的绝对路径,从linux系统根目录开始(不是caffe根目录,需要图片存放的绝对路径)
- LISTFILE: 图片文件列表清单,一般为一个txt文件,一行一张图片
- DB_NAME: 最终生成的db文件存放目录
方法1:创建脚本sh文件实现转换:
PS:该方法对应的路径如下图所示(该方法对应生成txt文件的方法1)

注意:这个地方两张图片都在images目录下,而不是在各自的两个文件夹下,因为下面create_lmdb.sh文件的代码中,convert_imageset的使用必须得是图片存放的绝对路径,这样两张图片在同一个绝对路径下,如果两张图片在不同的文件夹下,那么图片的绝对路径就不同了,得修改sh文件了!
执行以下指令生成sh文件:
cd ~/caffe-master/
sudo gedit examples/images/create_lmdb.sh编辑生成的sh文件,将以下代码复制到create_lmdb.sh文件
DATA=examples/images
rm -rf $DATA/img_train_lmdb
build/tools/convert_imageset --shuffle --resize_height=256 --resize_width=256 /home/heimu/caffe-master/examples/images/ $DATA/train.txt $DATA/img_train_lmdb代码解释:
build/tools/convert_imageset
这个表示convert_imageset的路径,它的绝对路径为/home/heimu/caffe-master/build/tools/,由于该文件在路径~/caffe-master目录下执行的,所以前面的路径可以省略。
--shuffle
该参数用于打乱图片顺序。
--resize_height=256 --resize_width=256
该参数用于限制图片的尺寸为256*256,因为数据图片可能尺寸不同,在这将尺寸归化。
/home/heimu/caffe-master/examples/images/
该路径为图片数据的存放绝对路径,从根目录开始。
$DATA/train.txt
该文件为图片列表清单,就是上一步生成的,此处为该文件的路径。
$DATA/img_train_lmdb
此处为生成的db文件的存放目录,会自动新生成img_train_lmdb文件。
接下来运行刚刚编辑保存的create_lmdb.sh的脚本文件:
cd ~/caffe-master/
sudo sh examples/images/create_lmdb.sh 如下图所示,可以看到新生成的img_train_lmdb文件

打开img_train_lmdb,如下图:
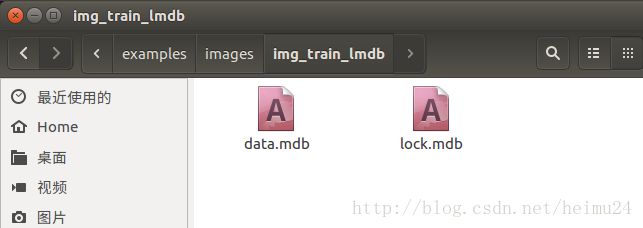
ps:如果在终端直接打开img_train_lmdb文件夹,会遇到权限不够问题,所以需要先执行下面指令,改变文件权限
sudo chmod 777 img_train_lmdb/然后再打开文件即可,至此就生成了caffe框架所需要的lmdb文件。
方法2:终端使用代码直接实现
数据存储如下:
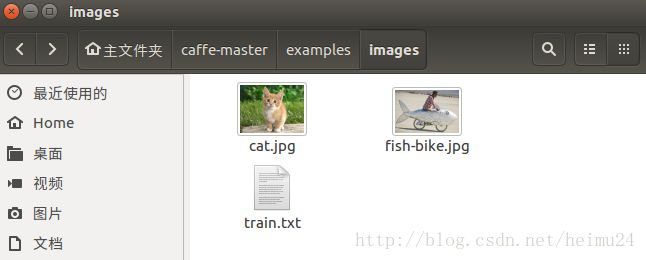
终端输入以下代码:
cd ~/caffe-master/examples/images
/home/heimu/caffe-master/build/tools/convert_imageset --resize_width=256 --resize_height=256 /home/heimu/caffe-master/examples/images/ ./train.txt ./img_train_lmdb注意:此处路径最为需要注意,由于是先进到的image目录下,所以convert_imageset就需要指明绝对路径,不然会提示找不到。
/home/heimu/caffe-master/examples/images/
该路径加上train.txt中的图片路径必须为图片的绝对路径,切记images后面的 / 必不可少!
./train.txt
相当于/home/heimu/caffe-master/examples/images/train.txt
./img_train_lmd
同理,./的意思应该是表示当前目录路径
心得:使用convert_imageset的时候,最关键的一点是注意图片数据的绝对路径不错就行,此处的绝对路径指的是前面的路径加上txt文件中的路径才是图片的绝对路径,切记切记!
结果如下图:

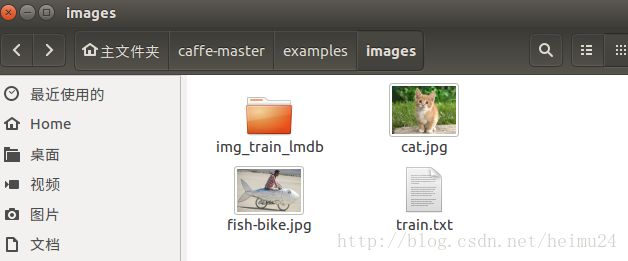
至此生成了db文件,其实两种方法一样,个人推荐第一种!
自己制作简单数据集
2.1制作自己的简单数据集
博主从网上下载了一些图片,分为两类,bird60张和cat60张,其中50张bird和50张cat作为训练集,10张bird和10张cat作为验证集,在/home/heimu/caffe-master/data下新建文件夹myself,然后在myself文件夹下新建两个文件夹,train和val,即训练集和测试集,然后train文件夹下新建两个文件夹,bird和cat,bird文件夹下放50张bird图片,cat文件夹下放50张cat图片,在val文件夹下放10张bird和10张cat,至此准备好了我们的数据,如下图所示
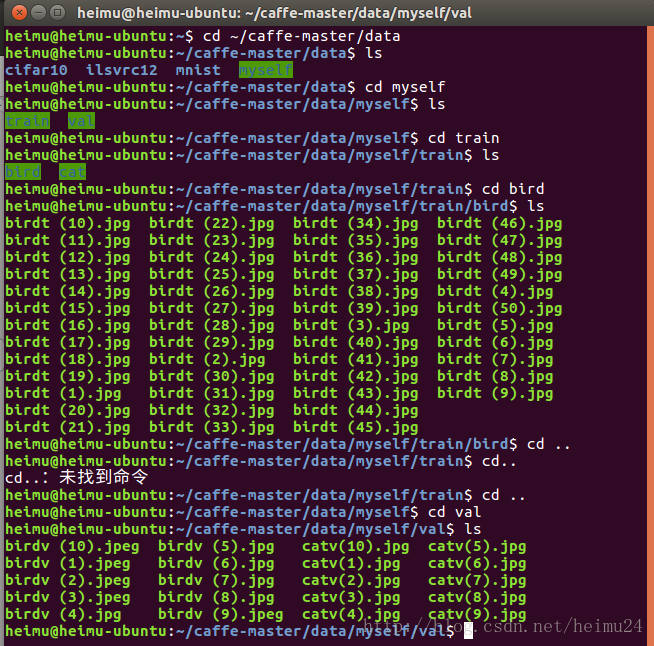

注意:为了便于处理,应该将图片统一命名,如上图
2.2生成train.txt和val.txt,即训练集和验证机列表清单
在路径/home/heimu/caffe-master/examples/新建一个myself文件夹,用来存放配置文件和脚本文件。
ps:上面的例子由于简单所以数据和配置文件等文件放在了一起,推荐分开两个目录。
cd ~/caffe-master/
sudo mkdir examples/myself- 指令mkdir,make directory,新建目录
然后新建脚本文件create_filelist,用来生成train.txt
sudo gedit examples/myself/create_filelist.sh将以下代码编辑进去,保存退出:
DATA=data/myself
MY=examples/myself
echo "Create train.txt..."
rm -rf $DATA/train.txt
find $DATA/train/bird -name birdt*.jpg | cut -d '/' -f5 | sed "s:^:bird/:" | sed "s/$/ 1/">>$MY/train.txt
find $DATA/train/cat -name catt*.jpg | cut -d '/' -f5 | sed "s:^:cat/:" | sed "s/$/ 2/">>$MY/train.txt
echo "Create val.txt..."
rm -rf $DATA/val.txt
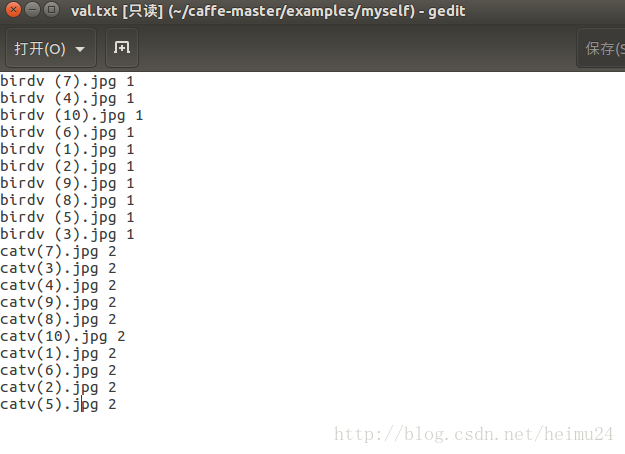
find $DATA/val -name birdv*.jpg | cut -d '/' -f4 | sed "s/$/ 1/">>$MY/val.txt
find $DATA/val -name catv*.jpg | cut -d '/' -f4 | sed "s/$/ 2/">>$MY/val.txt
echo "All done"
代码解释:
rm -rf $DATA/train.txt 表示清除该路径下的train.txt文件
find $DATA/train/bird -name birdt*.jpg此处为find指令的用法。
$DATA/train/bird表示具体的图片路径
birdt*.jpg 表示在以图片名字以birdt开始的jpg图片
cut -d '/' -f5 此处为cut指令的用法,具体表示请百度,此处表示以’/’为分隔符,由于该指令在caffe-master目录下执行,之后路径为/data/myself/train/bird/然后是图片名字,所以要采取的图片的名字为第5个,所以为-f5,下面val集的图片路径为/data/myself/val/然后是图片名字,为第4个,所以为-f4
sed "s:^:bird/:" 此处表示给图片名字加前缀’bird/’,表示一种路径
由于train文件夹下又分了两个文件夹,所以此处加前缀,表示路径
val文件夹下直接就是图片,所以不需要前缀。
sed "s/$/ 1/" 加后缀’ 1’,也就是标签
$MY/train.txt 表示在/examples/myself/路径下产生train.txt,以上内容全部保存到此。
ps:此处create_filelist.sh的制作有另外一种方法,如下:
准备工作:
原始数据:train文件夹下的bird图片和cat图片分别在各自的文件夹下,即train文件夹下有两个文件夹,bird和cat,但是val文件夹目录下并没有再分开bird和cat,而是将验证集10张bird和10张cat一起放到了val文件夹下,这是上述方法的图片数据的存储格式。
变更之处:此处需要将val文件夹下新建两个文件夹,bird和cat1(因为在代码中需要使用该文件夹名称,而cat是Ubuntu中的一个指令,冲突),同时将train文件夹下的cat文件夹重命名为cat1,将10张bird图片放到bird文件夹下,10张cat文件夹放到cat_1文件夹下,即可!
其他步骤都一样,只是将create_filelist.sh代码部分换成下列代码:
代码:
DATA=data/myself
MY=examples/myself
echo "Create train.txt..."
rm -rf $DATA/train.txt
ls $DATA/train/bird | sed "s:^:bird/:" | sed "s/$/ 1/">>$MY/train.txt
ls $DATA/train/cat1 | sed "s:^:cat1/:" | sed "s/$/ 2/">>$MY/train.txt
echo "Create val.txt..."
rm -rf $DATA/val.txt
ls $DATA/val/bird | sed "s:^:bird/:" | sed "s/$/ 1/">>$MY/val.txt
ls $DATA/val/cat1 | sed "s:^:cat1/:" | sed "s/$/ 2/">>$MY/val.txt
echo "All done"
代码解释:
此处代码和上面代码的改变支出就是将find和cut命令替换为了ls命令,ls表示列举,具体含义可以百度,此处不细讲
!!感觉这种方式简单点!!!然后在caffe-master根目录下执行此sh文件
cd ~/caffe-master/
sudo sh examples/myself/create_filelist.sh执行结果如下图


2.3转换生成db文件
新建sh脚本文件
cd ~/caffe-master/
sudo gedit examples/myself/create_lmdb.sh编辑该sh文件,代码如下:
MY=examples/myself
echo "Create train lmdb.."
rm -rf $MY/train_lmdb
build/tools/convert_imageset --shuffle --resize_height=256 --resize_width=256 /home/heimu/caffe-master/data/myself/train/ $MY/train.txt $MY/train_lmdb
echo "Create val lmdb.."
rm -rf $MY/val_lmdb
build/tools/convert_imageset --shuffle --resize_width=256 --resize_height=256 /home/heimu/caffe-master/data/myself/val/ $MY/val.txt $MY/val_lmdb
echo "All Done.."保存退出,执行create_lmdb.sh文件,代码如下
cd ~/caffe-master/
sudo sh examples/myself/create_lmdb.sh结果如下图:
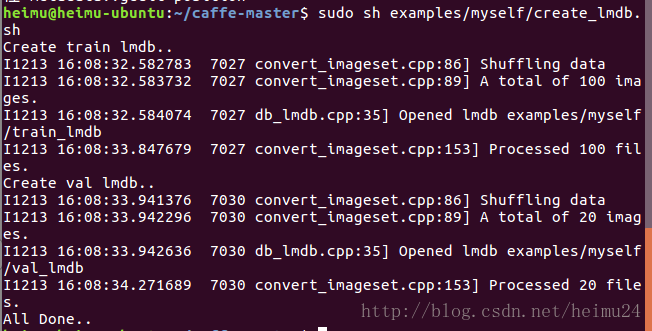
至此,所有转换过程完成个人推荐新建脚本建sh的方式执行,重点在于理解代码的意思的,确实ubuntu有很多指令,很多用法,不懂得百度咯,代码搞懂之后,就可以根据自己的数据自己的需求修改脚本文件来达到自己的需求!
总结:自己查找了相关的教程,看了相关的讲解,跟着做了一遍,成功了,然后花了一天的时间写这篇博客,在写的过程自己又做了一遍,而且跟着写博客的思路,不懂的地方自己又查找资料,加上备注,虽然这样可能慢点,但是只有自己亲手动一动,才能真正理解,获益匪浅!
推荐博客:
http://blog.csdn.net/u010193446/article/details/53406754
http://www.cnblogs.com/denny402/p/5083300.html