knn算法的原理与实现
机器学习基础算法python代码实现可参考: zlxy9892/ml_code
1 原理
knn 是机器学习领域非常基础的一种算法,可解决分类或者回归问题,如果是刚开始入门学习机器学习,knn是一个非常好的入门选择,它有着便于理解,实现简单的特点,那么下面就开始介绍其算法的原理。
首先,knn算法的基本法则是:相同类别的样本之间在特征空间中应当聚集在一起。
如下图所示,假设我们现在红、绿、蓝三种颜色的点,分布在二维空间中,这就对应了分类任务中的训练样点包含了三个类别,且特征数量为2。如果现在我们希望推测图中空心圆的那个点是属于那个类别,那么knn算法将会计算该待推测点与所有训练样点之间的距离,并且挑选出距离最小的k个样点(此处设定k=4),则图中与连接的4个点将被视为推测空心点(待推测点)类别的参考依据。显然,由于这4个点均为红色类别,则该待推测点即被推测为红色类别。
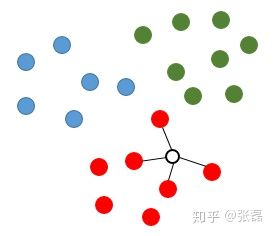 knn图解1
knn图解1
再看另一种情况,如果待推测点在中间的某个位置(如下图所示),则同样也计算出与其最邻近的4个样本点,而此时这4个样本点包含了3个类别(1红、1蓝、2绿),针对这样的情况,knn算法通常采用投票法来进行类别推测,即找出k个样本点中类别出现次数最多的那个类别,因此该待推测点的类型值即被推测为绿色类别。
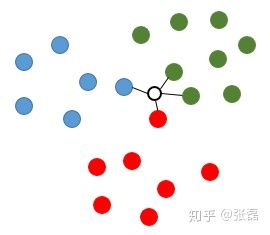 knn图解2
knn图解2
knn的原理就是这么朴素而简单,那么有人会说,这么简单的算法,相比于现在流行的其他较为复杂的机器学习算法,比如神经网络、随机森林等,有什么存在的价值呢?
回答这个问题,我们不妨回想一下机器学习中著名的没有免费午餐定理(no free lunch theorem),对于所有的任意一个问题(学习任务)来说,并不存在最好的模型,反之恰恰提醒了我们,对于特定的学习任务,我们需要去考虑最适合该问题学习器,也就是具体问题具体分析的哲学道理。
那么,knn也必然有其存在的价值,比如说,我们现在拿到一个学习任务,需要去选择一个学习器去解决该问题,而且也没有任何对该问题研究的前车之鉴,那么,从何下手?通常,我们不需要上来就用一个神经网络模型或者强大的集成学习模型去做,而是可以先用一用简单模型做一下“试探”,比如knn就是一个很好的选择,这样的“试探”的好处在哪里呢?我们知道,knn本质上属于懒惰学习的代表,也就是说它根本就没有用训练数据去拟合一个什么模型,而是直接用top-k个近邻的样本点做了个投票就完成了分类任务,那么如果这样一个懒惰模型在当前的问题上就已经能够得到一个较高的精度,则我们可以认为当前的学习任务是比较简单的,不同类别的样本点在特征空间中的分布较为清晰,无需采用复杂模型,反之,若knn得到的精度很低,则传达给我们的信息是:该学习任务有点复杂,往往伴随着的消息就是,当前问题中不同类别样本点在特征空间中分布不是清晰,通常是非线性可分的,需要我们去调用更强大的学习器。从而,一个简单的knn机器学习算法恰恰可以帮助建模者对问题的复杂度有一个大概的判断,协助我们接下来如何展开进一步的工作:继续挖掘特征工程、或者是更换复杂模型等。
2 算法实现
下面使用python自己亲手实现一个knn分类器。
代码链接 : https://github.com/zlxy9892/ml_code/tree/master/basic_algorithm/knn
首先创建一个名为knn.py的文件,用于构建knn实现的类,代码如下。
# -*- coding: utf-8 -*-
import numpy as np
import operator
class KNN(object):
def __init__(self, k=3):
self.k = k
def fit(self, x, y):
self.x = x
self.y = y
def _square_distance(self, v1, v2):
return np.sum(np.square(v1-v2))
def _vote(self, ys):
ys_unique = np.unique(ys)
vote_dict = {}
for y in ys:
if y not in vote_dict.keys():
vote_dict[y] = 1
else:
vote_dict[y] += 1
sorted_vote_dict = sorted(vote_dict.items(), key=operator.itemgetter(1), reverse=True)
return sorted_vote_dict[0][0]
def predict(self, x):
y_pred = []
for i in range(len(x)):
dist_arr = [self._square_distance(x[i], self.x[j]) for j in range(len(self.x))]
sorted_index = np.argsort(dist_arr)
top_k_index = sorted_index[:self.k]
y_pred.append(self._vote(ys=self.y[top_k_index]))
return np.array(y_pred)
def score(self, y_true=None, y_pred=None):
if y_true is None and y_pred is None:
y_pred = self.predict(self.x)
y_true = self.y
score = 0.0
for i in range(len(y_true)):
if y_true[i] == y_pred[i]:
score += 1
score /= len(y_true)
return score
接下来创建train.py文件,用于生成随机的训练样本数据,并调用knn类完成分类任务,并计算推测精度。
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from knn import *
# data generation
np.random.seed(314)
data_size_1 = 300
x1_1 = np.random.normal(loc=5.0, scale=1.0, size=data_size_1)
x2_1 = np.random.normal(loc=4.0, scale=1.0, size=data_size_1)
y_1 = [0 for _ in range(data_size_1)]
data_size_2 = 400
x1_2 = np.random.normal(loc=10.0, scale=2.0, size=data_size_2)
x2_2 = np.random.normal(loc=8.0, scale=2.0, size=data_size_2)
y_2 = [1 for _ in range(data_size_2)]
x1 = np.concatenate((x1_1, x1_2), axis=0)
x2 = np.concatenate((x2_1, x2_2), axis=0)
x = np.hstack((x1.reshape(-1,1), x2.reshape(-1,1)))
y = np.concatenate((y_1, y_2), axis=0)
data_size_all = data_size_1+data_size_2
shuffled_index = np.random.permutation(data_size_all)
x = x[shuffled_index]
y = y[shuffled_index]
split_index = int(data_size_all*0.7)
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
# visualize data
plt.scatter(x_train[:,0], x_train[:,1], c=y_train, marker='.')
plt.show()
plt.scatter(x_test[:,0], x_test[:,1], c=y_test, marker='.')
plt.show()
# data preprocessing
x_train = (x_train - np.min(x_train, axis=0)) / (np.max(x_train, axis=0) - np.min(x_train, axis=0))
x_test = (x_test - np.min(x_test, axis=0)) / (np.max(x_test, axis=0) - np.min(x_test, axis=0))
# knn classifier
clf = KNN(k=3)
clf.fit(x_train, y_train)
print('train accuracy: {:.3}'.format(clf.score()))
y_test_pred = clf.predict(x_test)
print('test accuracy: {:.3}'.format(clf.score(y_test, y_test_pred)))
至此,knn算法原理阐述与代码实现介绍完毕。