流动的推荐系统——兴趣Feed技术架构与实现
作者:陈开江@刑无刀,金融科技公司天农科技CTO,曾任新浪微博资深推荐算法工程师,考拉FM算法主管,先后负责微博反垃圾、基础数据挖掘、智能客服平台、个性化推荐等产品的后端算法研发,为考拉FM从零构建了个性化音频推荐系统。
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2017年《程序员》
流动的推荐系统
我们经常谈论的推荐系统(Recommender System),从形式上看是比较“静态”的推荐,通常位于网页主要信息的周边,比如电商网站的“看了又看”、“买了又买”。这种推荐系统在大多数场景下无法独立撑起一款产品。
依据维基百科Recommender System词条的定义:“推荐系统是信息过滤系统的子类,专门用于预测用户对一个项目偏好或者评分进行预测”,则兴趣Feed也是一种推荐系统:它预测用户对社交网络中相邻节点动态内容喜好程度,并根据喜好程度决定这些动态内容的展示顺序。
Feed是一种信息流,就是我们看到的“动态”、“新鲜事”。当用户与一些内容源建立了连接(如关注、赞、收藏等)之后,这些内容源产生的新动作,就会源源不断地通过连接流向用户,不同内容源产生的动态被聚合后呈现在用户面前,就是Feed。
传播社交网络动态的Feed,通常默认按照动态产生的时间顺序出现在你面前,称为时间线(timeline)。国外的Twitter、Instagram,一开始都是时间线形式的Feed;国内的微博、QQ空间、微信朋友圈至今仍然是时间线。
但是一些老牌时间线Feed都有计划要切换成依据算法排序的个性化兴趣Feed,微博在2012年尝试过智能排序,Twitter在去年上线了一个叫做“当你不在时发生了什么”的功能,Facebook甚至早就放弃对其NewsFeed的时间线排序。
出现这种情况的原因主要有两个。一方面,智能手机的普及和移动网络的提速,使得UGC越来越容易,用户动态的产生和浏览越来越碎片化,数量和频度陡增,以前用户消费无压力的时间线Feed,开始出现信息过载或者错过一些更感兴趣的内容的情况。Instagram说他们的用户平均错过了70%的内容,Facebook也曾说每个用户每天只能看完1500条新鲜事中的300条而已。另一方面,时间线Feed不利于商业化的开展,商业账号肆无忌惮地以动态的方式发布广告,不仅影响用户体验,还完全绕过平台方进行商业活动,形成一种“公共资源悲剧”。
所以,Feed的发展趋势必然是从时间线到利用算法重排序,按照用户兴趣的相关程度展示Feed,一方面要帮用户解决信息过载问题,另一方面要平衡好平台上的商业价值和用户体验。
成功的兴趣Feed——NewsFeed
一个成功的兴趣Feed,就是Facebook的NewsFeed。那是2006年9月,Facebook上线了朋友新鲜事,与之同时问世的还有MiniFeed(个人动态)。上线至今十周年,NewsFeed已经成为日收入几千万美元的现金牛。
Facebook刚上线这个功能时,曾引发广泛的争议,焦点就是“隐私”问题——我的动态怎么能让别人看见呢?用户不停质疑和抗议,又忍不住继续使用,Facebook就在争议声中增加了最初的隐私控制功能,比如隐藏自己的动态,而NewsFeed就这样坚持了下来。
2009年,Facebook在收购FriendFeed之后,将其赞(like)功能整合进了NewsFeed中,并开始按照热门程度对Feed重排序,这又引起了用户们的反抗,因为大家已经习惯按照时间顺序阅读。
10年来,NewsFeed有数不清的改进,甚至每天线上会同时部署很多算法版本进行AB测试。但EdgeRank算法是这条改进之路的一个标志性建筑,我们可以将NewsFeed排序策略分为EdgeRank前时代、EdgeRank时代和EdgeRank后时代。
在EdgeRank前时代,按照Facebook首席产品官Chris Cox的说法:“最初,NewsFeed排序就是在拍脑袋,给照片加点权重,给系统消息降点权重。”我们的算法工程师们读到这些,想必要会心一笑:今天高大上的Facebook,又是人工智能又是深度学习,竟然也是从这个时代走过来的。
之后,Serkan Piantino(现任Facebook人工智能研究院工程总监)在2010年左右领导开发了第一版EdgeRank算法。
EdgeRank算法
了解大名鼎鼎的EdgeRank是怎么回事,先看朋友的一条新鲜事(动态)诞生后怎么流动到你的面前:
- 首先你的一个朋友产生了一条新鲜事,比如他发布一条想法、赞了一个主页、给一张照片加了标签。
- 然后经过你这个朋友的介绍,到了你的家门口(你的首页),你一开门(登录或者刷新)就可能看见它。
- 总体来说,新的还是比旧的更能得到你的接见。
- 新鲜事不多时,开门一个一个寒暄可能还行,它们也等得起,内容太多时,就得考虑个先来后到了。
这几个步骤,大致刻画了EdgeRank的思想,简单直接。基于这个假设,EdgeRank排序算法主要考虑了三个因素:
- 亲密度。它对应了第二个步骤背后的思想,那么多人介绍过来,我们当然要优先照顾更“喜欢”的人了,亲密度的量化要考虑平日里你和这个朋友“走动”是否频繁、连接是否紧密。
- 边权重。这也是EdgeRank名字含义所在:不同的动态权重不同,点赞动态和发布照片显然不一样。
- 新鲜度。既然是NewsFeed,那么新一些(New)的动态就更受青睐。
三个分数,最终用相乘的方式共同作用于每一条新鲜事的分数,用于排序和筛选,如图1所示。这个排序方法的确很简单,只是量化了三个主要因素,然后主观地相乘,没有任何目标优化思想在背后。根据Facebook披露的消息,早期的EdgeRank的确没有引入机器学习,所以根本称不上是智能的算法。

向机器学习要智能
2011年之后,Facebook内部就不再提EdgeRank算法了,NewsFeed进入EdgeRank后时代。此时的Facebook,月活跃用户超过10亿,约2000万的公共主页,移动设备贡献了大多数流量,面对复杂的上下文因素,必须引入机器学习才能Hold整个场面。
引入机器学习的好处显而易见,原来考虑的因素就是机器学习模型的特征,一个线性模型可以处理大规模的稀疏特征,并且会为每一个特征寻找到最优的参数(即权重)。在这样的框架下,产品和工程人员只需要去尽力发现那些影响排序的特征,然后把特征交给机器学习模型,就万事大吉。
NewsFeed团队成员在原来EdgeRank的基础上,更加细致地定义了不同层级的亲密度。用深度神经网络理解图片内容和文字内容,可以知道相片中的物体是不是用户感兴趣的,还可以分析出新鲜事的讨论话题用于排序。随着产品迭代,考虑的排序因素越来越多,诸如阅读时间长短、视频内容、链接内容,或者取关、隐藏一个源等。前前后后一共考虑了10万多的排序因素(模型的特征空间应该会更高),如果还按照原来的方式去调节权重,显然既不科学又很低效。
破解机器学习和数据的局限
除了全面转向机器学习之外,NewsFeed团队也在重新思考人和算法的关系。他们要关心的是到底“如何把用户真正最关心的找出来”,而不仅仅是“如何提高点击率”。Facebook一直是数据驱动的,这也是他们能够在争议中把NewsFeed坚持下来的信念来源,但是不是唯数据马首是瞻,团队内部一直有很多思考。比如:
- 团队发现有85%的隐藏新鲜事操作来自5%的人,经过与这些用户沟通才发现,原来这5%的人把“隐藏”当作邮件里的“标记已读”了,对喜不喜欢的新鲜事只要看过就会点击隐藏。
- 对于悲伤的事情,用户可能关心但不会点赞。
- 对于有些点赞,用户可能并不是真的感兴趣,只是“点赞狂魔”发狂而已。
- 用户阅读一篇长帖子,读到一半不读了,也并不能说明他对这篇帖子不感兴趣。
这些都让他们开始关注到机器学习和数据的局限。于是,在算法团队之外,Facebook搭建了一个遍布全球的人肉评测小组。人肉评测小组的工作不是简单地对算法筛选结果进行喜欢/不喜欢的标注,而是非常深入地阐述为什么喜欢/不喜欢算法筛选结果,而且他们会与工程师详细交流评测结果,因为这种人肉评测方式可以有效地拆穿数据说谎,让产品远离一味追求提高数据指标的怪圈。
此外,NewsFeed还有两个重要的配套设施:社交关系推荐系统和广告系统。
NewsFeed存在是因为用户建立了大量的社交联系,出现信息过载,因此“你可能感兴趣的人”(people you may know)推荐系统是必不可少的,这是NewsFeed“合法”存在的前提。
这是一个我们在产品形式上比较熟悉的推荐系统,它的核心是一套大规模矩阵分解算法,利用已有的协同矩阵为你推荐可能想建立联系的新Item,包括用户、App、公共主页等。
Facebook的广告形态非常多样,包括:
- Suggested Page(你可能喜欢的公众页)
- Page Post(公众号帖子推广)
- Suggested App(你可能喜欢的应用)
- Video Ads(视频广告)
所有的数据都显示,重排序后的NewsFeed可以让用户阅读积极性提高很多。因此,虽然外界一直有质疑和争吵,但是NewsFeed重排序并没有停止过。显然“大家一起穷,各自拼人品”的时间线不符合商业社会的基本哲学,提高效率的兴趣Feed才是一种必然。
并不复杂的兴趣Feed实现
兴趣Feed如何实现?这里先介绍创意内容收集工具Pinterest的Smart Feed,然后总结一些通用技术点。
Smart Feed技术实现
整个Smart Feed后端主要模块逻辑如图2,由三个部分构成:
- 后台任务(Worker)
- 内容生成器(Content Generator)
- 前端服务(Service)
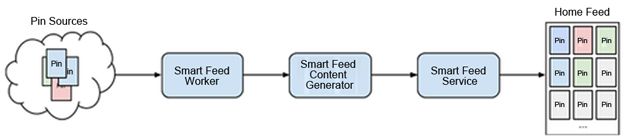
后台任务(worker)
Worker的职责有两个:
- 接收数据源产生的新Pin,决定这个Pin该推送给哪些用户,并针对每一个它该推送的用户,给出这个Pin对这个用户的吸引程度,俗称“打分”。
- 存储这些经过打分的Pin,备用。

打了分的Pin就会根据其不同来源分开存储(Pool)。存储结构是一个优先队列,按照打分排序,新的Pin进来和原来(但用户还未看)的Pin一起排序。
这个存储的Pool可以直接用KV数据库顶上,HBase、Redis都可以,每次送入数据库的数据是一个三元组:(user, pin, score)。Pinterest选用的是HBase。一共有两个HBase集群,一个存还没看过的Pin,一个存已经看过的Pin。
当数据源产生了新的Pin之后,需要由一个叫PinLater的模块经过Zen(封装了HBase基本操作的图数据存储模块)推送给粉丝。这里推送是异步的,有几秒到几分钟的延迟。
内容生成器(Content Generator)
如图4,内容生成器要做的是:
- 决定返回多少个Pin,数量不是固定的,会根据用户访问频繁程度以及上次看到的新内容多少来决定。
- 分配来源的比例构成,这块Pinterest没有透露分配比例,我们可以猜一下,也许是固定比例,也许是有一些启发式算法。
- 将Pin排成一定的顺序,按照分数排序就好了。
- 待推送内容要从Pool中删除,以保证每次请求的都是没看过的。
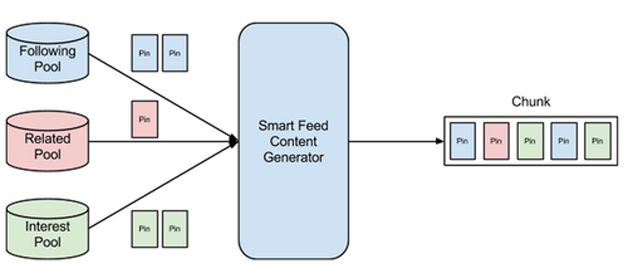
每一次产生的待推送内容合在一起叫做一个“块”(chunk)。
前端服务(Feed service)
如图5,Feed service提供前端的服务。为了提供高可用服务,Feed service的任务有二个:
- 接收从内容生成器返回的“新”内容。
- 新内容合并上一次的“旧”内容。
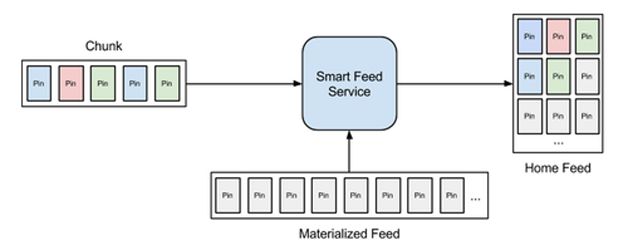
Pinterest排序算法
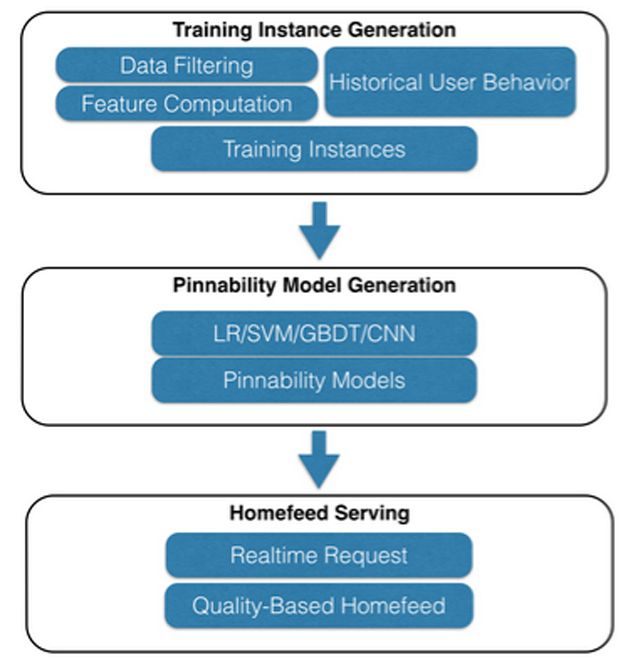
排序算法名字叫做Pinnability。我们可以将其翻译成“可Pin度”,可Pin度是一组机器学习模型,用于衡量一个用户对一条Pin产生互动的可能性。

Pinnability模型用到的机器学习算法都是比较常用的模型,包括逻辑回归(LR)、支持向量机(SVM)、GBDT和卷积神经网络(CNN)。整个Pinnability的模型流程如图7所示。模型产生的流程分为三个阶段:准备训练数据、训练模型、上线使用。
兴趣Feed的技术要点
分析完Pinterest的兴趣Feed实现,我们再总结一下一个通用的兴趣Feed需要考虑哪些方面。
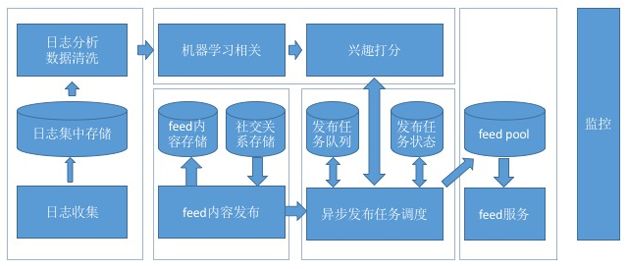
整体逻辑
整体逻辑上,一个兴趣Feed逻辑结构大致如图8所示。
数据模型
Feed这种形式又叫做Activity Stream。顾名思义,就是用户的动作(Activity)形成的数据流(Stream)。
Feed的基本数据有三个:用户(User)、动态(Activity)和关系(Connection)。
表达用户动态(Activity)的元素有相应的规范,叫做Atom,可以参考它,并结合产品需求,定义出自己的Feed数据模型。根据Atom的定义,一条动态包含以下元素:
- Time:发生的时间。
- Actor:由谁发出的?通常Actor就是用户ID,但是我们也可以扩展到其它拟人化物体上,如关注的一个“店铺”、收藏的一部“电影”。
- Verb:动词,动态核心是哪一个动作?比如“follow”、“like”等。
- Object:动作作用到最主要的对象,只能有一个。
- Target:动作的最终目标,与verb有关,可以没有。它对应英语中介词to后接的事物,比如“John saved a movie to his wishlist”(John保存了一部电影到清单里),这里电影就是Object,而清单就是Target。
- Title:动态的标题,自然语言描述。
- Summary:通常是一小段HTML代码,是对这个Activity的描述,还可能包含类似缩略图这样的可视化元素,可以理解为Activity的view,不是必须的。
举个例子: 2016年5月6日23:51:01(Time)@刑无刀(Actor)分享了(Verb) 一条微博(Object)给 @ResysChina(Target)。Title就是前面这句话去掉括号后的内容,Summary暂略。
关系即连接。互联网产品里处处皆连接,有强有弱,好友关系、关注关系等社交是较强的连接,还有点赞、收藏、评论、浏览,这些动作都可以认为用户和另一个对象之间建立了连接。有了连接,就有Feed的传递和发布。
定义一个连接的元素有:
- from: 连接的发起方。
- to:被连接方。
- type/name: 连接的类型/名字、关注、加好友、点赞、浏览、评论等。
- affinity:连接的强弱。
如果把建立一个连接也视为一个Atom模型的话,from就对应其中的Actor,to就对应其中的Object。
连接的发起从from到to,动态的流动从to到from。连接和动态是相互加强的,类似蛋和鸡的关系:有了动态,就会产生新的连接;有了新的连接,就可以喂(Feed)给你更多的动态内容。
发布新动态
用户登录/刷新后,Feed是怎么产生的?内容出现在受众的Feed中,这个过程称为Fan-out。
我们的直觉上是这样实现的:
- 获取用户所有连接的终点(如好友或者关注对象)。
- 获取这些连接终点(关注对象)产生的新内容(Activity)。
- 排序后输出。

这就是行话说的拉模式(Fan-out-on-load),Feed是在用户登录/刷新后实时产生的。
拉模式的好处如下:
- 实现简单直接:一行SQL就搞定了。
- 实时:内容产生了,受众只要刷新就看得见。
但是也存在不足:
- 随着连接数的增加,这个操作的复杂度是指数级增加的,显然不可取。
- 内存中要保留每个人的产生的内容。
- 服务很难做到高可用。
与拉模式对应的,还有一个推模式(Fan-out-on-write)。

当一个用户(Actor)产生了一条Activity后,不管受众是否刷新,立即将这条内容推送给相应的用户(和这个Actor建立了连接的人),系统为每一个用户单独开辟一个Feed存储区域,用于接收推送的内容。当用户登录后,系统只需要读取他自己的Feed即可。
推模式的好处显而易见:在用户访问自己的Feed时,几乎没有任何复杂的查询操作,所以服务可用性较高。
推模式也有如下的不足:
- 大量的写操作:每一个粉丝都要写一次。
- 大量的冗余存储:每一条内容都要存储N份(受众数量)。
- 非实时:一条内容产生后,有一定的延迟才会到达受众Feed中。
既然两者各有优劣,那么将两者结合起来呢?一种简单的结合方案是全局的:
- 对于活跃度高的用户,使用推模式,每次他们刷新时不用等待太久,而且内容页相对多一些。
- 对于活跃度没有那么高的用户,使用拉模式,当他们登录时才拉取最新的内容。
- 对于热门的内容生产者,缓存其最新的N条内容,用于不同场景下拉取。
还有一种结合方案是分用户的,这是Etsy的设计方案:
- 如果受众用户与内容产生用户之间的亲密度高,则优先推送,因为这个内容更可能被这个受众所感兴趣。
- 如果受众用户与内容产生用户之间的亲密度低,则推迟推送或者不推送。
- 也不是完全遵循亲密度顺序,而是采用与之相关的概率。
在中小型的社交网络上,采用纯推模式就够用了,结合的方案可以等业务发展到一定规模后再考虑。
一个推模式的Feed发布实现很简单:
- 一个集中存储所有动态内容的数据库,一般是MySQL。
- 为每个用户保存各自排序后的Feed,一般是Key-Value数据库,如Redis或者HBase。
- 一个类似Pinlater的分布式异步任务队列,Celery是一个不错的选择。
按兴趣排序
兴趣Feed的排序,要避免陷入两个误区:
- 没有目标的排序。设计排序算法之前,一定要先弄清楚:为什么要对时间序重排?希望达到什么目标?目标用哪些指标量化?只有先确定目标,才能检验和优化算法。
- 人工量化排序因素。我们经常见到的产品或者运营的同学要求对某个因素加权、降权。这样做很不明智,因为人的知识利于做启发,不利于做量化。人可以告诉算法很多可能有用的排序因素,缩短效果提升的路径,但是人直接指定参数的权重,对效果提升来说基本上有百害而无一利。
我们从机器学习的思路来简单设计一个提升互动率的兴趣Feed。首先,定义好互动行为包括哪些,比如点赞、转发、评论和查看详情等。其次,区分好正向互动和负向互动,比如隐藏某条内容、点击不感兴趣等是负向的互动。
这是一个典型的二分类监督学习问题,将正向的互动视为同一类。一条动态产生之后,展示给用户之前,用机器学习来预测用户对产生正向互动的概率,预测的概率就可以作为兴趣排序分数输出。
能产生概率输出的二分类算法都可以用在这里,包括贝叶斯、最大熵和逻辑回归等。互联网常用的是逻辑回归,它有很多好处:
- 线性模型,足够简单。
- 产生0-1之间的输出,互相可以比较。
- 开源实现多,初始技术成本小。
- 工业界已经反复验证过。
用机器学习来为兴趣Feed排序,最重要的是将<动态,受众>这个数据对表示成特征向量。特征向量就是排序因素的向量化表述。在算法选定后,人工可以花很多力气在寻找影响排序的因素上,这就是传说中的“特征工程”。特征工程还包括对已有的特征进行选择,选择的目的是:机器学习模型完成后,以RPC的方式提供服务,供Feed系统中新动态内容发布时调用。
关于RPC框架,选用Apache Thrift即可。机器学习模型训练框架有很多,我们可以选Vowpal Wabbit,它是一个分布式机器学习框架,可以和Hadoop轻松结合。
数据和效果追踪
我们既要通过历史数据来寻找算法的最优参数,又要通过新的数据验证排序效果,所以我们要关注数据的存储和使用。
与兴趣Feed相关的数据有:
- 目标有关的互动行为数据(记录每一个用户在Feed上的操作行为)。
- 曝光给用户的内容(一条曝光要有唯一的ID,曝光的内容仅记录ID即可)。
- 互动行为与曝光的映射关系(每条互动数据要对应到一条曝光数据)。
- 用户profile(提供用户特征,来自离线挖掘和数据同步)。
- Feed内容分析数据(提供内容特征)。
日志的收集和存储,一般选用Kafka和Hadoop即可,用Hive处理数据,生成训练样本,监控产品指标。其中比较重要的是模型的参数更新,即训练模型。
对于一个初级的兴趣Feed,没必要做到在线实时更新排序算法的参数,所以数据的pipeline可以借鉴Pinterest。例如,选用逻辑回归预测互动行为排序Feed,离线阶段关注模型的AUC是否有提升。
另外,互动数据相比全部曝光数据,数量会小得多,所以在生成训练数据时需要对负样本(展示了却没有产生互动的样本)进行采样,采样比例也是一个可以优化的参数,固定算法和特征后选择效果最好的比例。
AB测试时关注具体的产品目标是否有提升,比如互动率等,同时还要根据产品具体形态关注一些辅助指标。
兴趣Feed的挑战及应对
兴趣Feed是在互联网深度发展之后的一种必然趋势,很多Feed类产品都已经在数据上验证了这一点。但是我们还是要清醒地认识到:兴趣Feed类产品虽然概念简单,挑战却不少。
用户习惯
时间排序的Feed非常自然,用户很容易接受。而一旦用算法决定Feed的排列顺序,用户是否能够接受,非常挑战产品的设计能力。尤其是如果一开始是时间线Feed,要转变成兴趣Feed,这个切换相对于一开始就是兴趣Feed,用户习惯改变要更难一些。
面对这一挑战,我们需要考虑几点:
- 是不是真的需要兴趣Feed?信息没有过载是不需要兴趣Feed的。是否信息过载,数据很容易验证:到底用户错过的了多少内容?
- 兴趣Feed产品设计需要深入思考,虽然用算法为用户过滤了他不感兴趣的内容,但是在UI/UE上需要淡化技术痕迹,呈现出更自然的浏览方式,比如说是不是可以考虑算法筛选后,展示上依然是时间序。
- 兴趣Feed的算法效果提升要快。一开始兴趣Feed排序效果不好很正常,只要在用户失去耐心之前将其做到可用,风险就会小很多。
技术上的挑战
在一个需要用算法排序的Feed类产品上,数据量级应该不会小了,而且如果兴趣Feed真的有效,那么数据量增加速度也会提升,所以相应的技术挑战会很快出现。
- Feed服务的高可用。要保证关键模块故障时优雅降级,任何数据都有冗余,并且能够热切换。
- 大规模机器学习。高维稀疏的特征空间,超大的样本量,这些都要求机器学习平台能够处理大规模学习问题,它一定是并行化的,也方便算法工程师快速进行迭代。
- 在线实验系统。对在线流量进行正交切分,尽量多地进行不同实验,而且同时进行的实验之间互不影响,得到的实验结论科学有效。这一块可以参考Google的在线实验系统,国内百度等大型互联网公司也公开分享过它们的实验系统如何划分流量。
算法的边界
我们不得不承认,算法是有边界的。只不过很多产品距离边界还很远,还没有充分把数据中蕴含的价值挖掘出来。Facebook建立人肉评测小组,说明他们已经非常重视利用人的创造力弥补算法的不足。
由于大多数人在大多数情况下是非理性的,感兴趣的标准也会呈现不一致的情况,再加上社会群体心理的干扰,为个人寻找兴趣内容是一个非常复杂的课题。
另外,算法本身的引入,也给整个产品增加了复杂度,在算法干预下再测量用户对内容的感兴趣程度,很类似量子理论中的“测不准原理”。
面对算法接管我们的Feed内容,我们既不能做出太多主观决策,相信科学的算法一定能够得到比纯人力主观指定的规则更好的结果,但是也不能偷懒,需要从数据中得到启示,用我们上帝般的视角巡视整个局面,帮助算法表现得更好。
订阅2016年程序员(含iOS、Android及印刷版)请访问 http://dingyue.programmer.com.cn 
订阅咨询:
• 在线咨询(QQ):2251809102
• 电话咨询:010-64351436
• 更多消息,欢迎关注“程序员编辑部”
130+位讲师,16大分论坛,中国科学院院士陈润生、滴滴出行高级副总裁章文嵩、联想集团高级副总裁兼CTO芮勇、上交所前总工程师白硕等专家将亲临[2016中国大数据技术大(http://bdtc2016.hadooper.cn/dct/page/1),票价折扣即将结束,预购从速。