目标检测(8)—SSD算法原理理解
转载自:http://www.cnblogs.com/xuanyuyt/p/7222867.html
推荐相关博文:https://zhuanlan.zhihu.com/p/24954433
https://zhuanlan.zhihu.com/p/29410169
一. 算法概述
SSD(Single Shot MutiBox Detectior (one-stage方法)是Wei Liu在ECCV 2016提出的,直接回归目标类别和位置,它是在不同尺度的特征图上进行预测,端到端的训练,图像的分辨率比较低,也能保证检测的精度。
本文提出的SSD算法是一种直接预测目标类别和bounding box的多目标检测算法。与faster rcnn相比,该算法没有生成 proposal 的过程,这就极大提高了检测速度。针对不同大小的目标检测,传统的做法是先将图像转换成不同大小(图像金字塔),然后分别检测,最后将结果综合起来(NMS)。而SSD算法则利用不同卷积层的 feature map 进行综合也能达到同样的效果。文章的核心之一是同时采用lower和upper的feature map做检测。
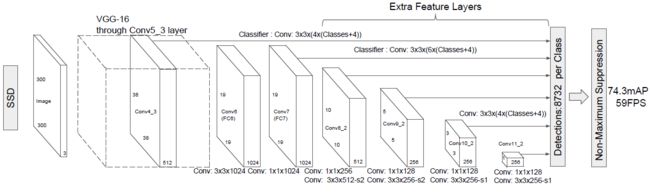 Fig.1 SSD 框架
Fig.1 SSD 框架
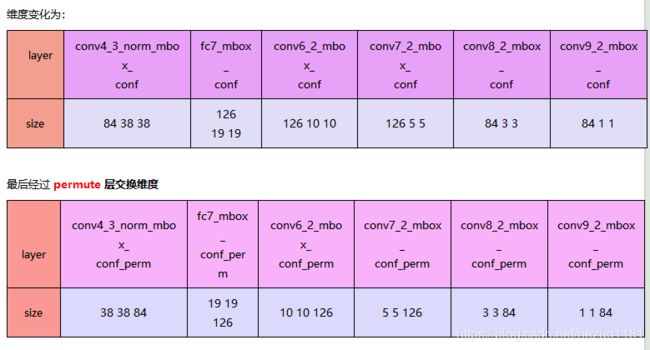
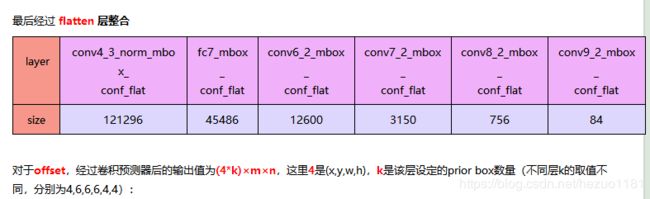
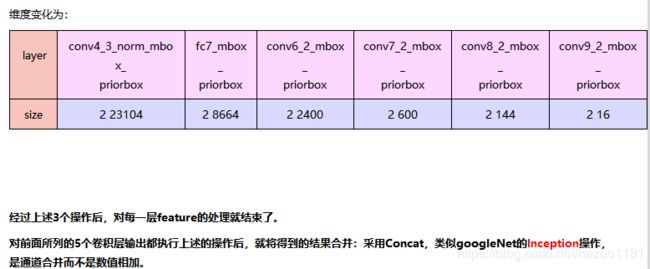
算法的主干网络结构是VGG16,将最后两个全连接层改成卷积层,并随后增加了4个卷积层来构造网络结构。对其中5种不同的卷积层的输出(feature map)分别用两个不同的 3×3 的卷积核进行卷积,一个输出分类用的confidence,每个default box 生成21个类别confidence;一个输出回归用的 localization,每个 default box 生成4个坐标值(x, y, w, h)。此外,这5个feature map还经过 PriorBox 层生成 prior box(生成的是坐标)。上述5个feature map中每一层的default box的数量是给定的(8732个)。最后将前面三个计算结果分别合并然后传给loss层。
主干网络:原始的作者提出的SSD是采用了VGG16,主要是作用到了第五个卷积块,第五个卷积块的第三个卷积层。(每个卷积块由2或者3个卷积层和池化层组成)。
1.主干网络可以采取VGG,ResNet,MobileNets等来代替原来的VGG16,各种卷积神经网。
2.将VGG最后的两个FC改成卷积(主要是原来的VGG,ResNet是用来处理图像分类的,目标检测的时候则有变化),并增加了4个卷积层。
多尺度Feature Map的预测:接下来进行预测的时候,会对接下来的六个不同的尺寸分别进行预测(图中的六条连线),六条连线的输出也分别作为后续检测层的输入。这六个连线也分别包括了6个不同大小的Feature Map.分别是38*38,19*19,10*10,5*5,3*3,1*1
38*38——>19*19:
19*19——>10*10:通过下采样的操作完成,会采用padding 进行补充,19*19*1024经过1*1*256得到19*19*1024,再经过3*3*512,p=1,s=2,得到的输出是10(输出图像的空间尺寸可以计算为([W-F + 2P] / S)+1。在这里,W 是输入尺寸,F 是过滤器的尺寸,P 是填充数量,S 是步幅数字。),往下取整。
10*10——>5*5:10*10*512经过1*1*128得到10*10*128,再经过3*3*256,p=1,s=2;得到5*5*256
5*5——>3*3:5*5*256经过1*1*128得到5*5*128,再经过3*3*356,p=0.s=1得到3*3*256
3*3——>1*1:3*3*256经过1*1*128得到3*3*128,再经过3*3*356,p=0.s=1得到1*1*25
将这六个不同的尺度作为了检测预测层的输入,再通过NMS(非极大值抑制)对检测结果进行合并筛选。
附:VGG16的介绍:

二. Default box


Fig.2 default boxes
作者的实验表明default box的shape数量越多,效果越好。

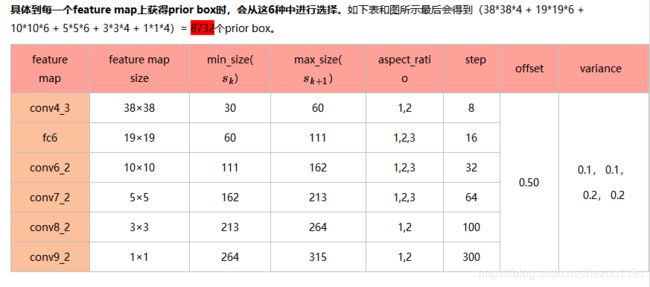
因此,对于每个feature map cell而言,一共有6种default box。
可以看出这种default box在不同的feature层有不同的scale,在同一个feature层又有不同的aspect ratio,因此基本上可以覆盖输入图像中的各种形状和大小的object!
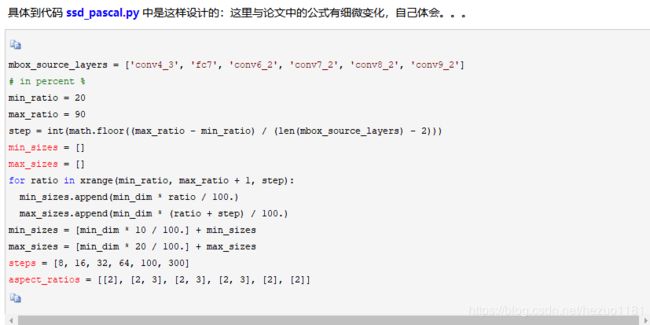
caffe 源码 prior_box_layer.cpp 中是这样提取 prior box 的:
for (int h = 0; h < layer_height; ++h) {
for (int w = 0; w < layer_width; ++w) {
float center_x = (w + offset_) * step_w;
float center_y = (h + offset_) * step_h;
float box_width, box_height;
for (int s = 0; s < min_sizes_.size(); ++s) {
int min_size_ = min_sizes_[s];
// first prior: aspect_ratio = 1, size = min_size
box_width = box_height = min_size_;
// xmin
top_data[idx++] = (center_x - box_width / 2.) / img_width;
// ymin
top_data[idx++] = (center_y - box_height / 2.) / img_height;
// xmax
top_data[idx++] = (center_x + box_width / 2.) / img_width;
// ymax
top_data[idx++] = (center_y + box_height / 2.) / img_height;
if (max_sizes_.size() > 0) {
CHECK_EQ(min_sizes_.size(), max_sizes_.size());
int max_size_ = max_sizes_[s];
// second prior: aspect_ratio = 1, size = sqrt(min_size * max_size)
box_width = box_height = sqrt(min_size_ * max_size_);
// xmin
top_data[idx++] = (center_x - box_width / 2.) / img_width;
// ymin
top_data[idx++] = (center_y - box_height / 2.) / img_height;
// xmax
top_data[idx++] = (center_x + box_width / 2.) / img_width;
// ymax
top_data[idx++] = (center_y + box_height / 2.) / img_height;
}
// rest of priors
for (int r = 0; r < aspect_ratios_.size(); ++r) {
float ar = aspect_ratios_[r];
if (fabs(ar - 1.) < 1e-6) {
continue;
}
box_width = min_size_ * sqrt(ar);
box_height = min_size_ / sqrt(ar);
// xmin
top_data[idx++] = (center_x - box_width / 2.) / img_width;
// ymin
top_data[idx++] = (center_y - box_height / 2.) / img_height;
// xmax
top_data[idx++] = (center_x + box_width / 2.) / img_width;
// ymax
top_data[idx++] = (center_y + box_height / 2.) / img_height;
}
}
}
}
三. 正负样本







Fig.4 SSD data argument
四. 网络结构


Fig.5 SSD 流程
SSD 网络中输入图片尺寸是3×300×300,经过pool5层后输出为512×19×19,接下来经过fc6(改成卷积层)
layer {
name: "fc6"
type: "Convolution"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 1024
pad: 6
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
dilation: 6
}
}
layer {
name: "conv6_2_mbox_conf"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_conf"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 126
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "conv6_2_mbox_loc"
type: "Convolution"
bottom: "conv6_2"
top: "conv6_2_mbox_loc"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 24
pad: 1
kernel_size: 3
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.0
}
}
}

layer {
name: "conv6_2_mbox_priorbox"
type: "PriorBox"
bottom: "conv6_2"
bottom: "data"
top: "conv6_2_mbox_priorbox"
prior_box_param {
min_size: 111.0
max_size: 162.0
aspect_ratio: 2.0
aspect_ratio: 3.0
flip: true
clip: false
variance: 0.10000000149
variance: 0.10000000149
variance: 0.20000000298
variance: 0.20000000298
step: 32.0
offset: 0.5
}
}
layer {
name: "mbox_loc"
type: "Concat"
bottom: "conv4_3_norm_mbox_loc_flat"
bottom: "fc7_mbox_loc_flat"
bottom: "conv6_2_mbox_loc_flat"
bottom: "conv7_2_mbox_loc_flat"
bottom: "conv8_2_mbox_loc_flat"
bottom: "conv9_2_mbox_loc_flat"
top: "mbox_loc"
concat_param {
axis: 1
}
}
layer {
name: "mbox_conf"
type: "Concat"
bottom: "conv4_3_norm_mbox_conf_flat"
bottom: "fc7_mbox_conf_flat"
bottom: "conv6_2_mbox_conf_flat"
bottom: "conv7_2_mbox_conf_flat"
bottom: "conv8_2_mbox_conf_flat"
bottom: "conv9_2_mbox_conf_flat"
top: "mbox_conf"
concat_param {
axis: 1
}
}
layer {
name: "mbox_priorbox"
type: "Concat"
bottom: "conv4_3_norm_mbox_priorbox"
bottom: "fc7_mbox_priorbox"
bottom: "conv6_2_mbox_priorbox"
bottom: "conv7_2_mbox_priorbox"
bottom: "conv8_2_mbox_priorbox"
bottom: "conv9_2_mbox_priorbox"
top: "mbox_priorbox"
concat_param {
axis: 2
}
}
layer {
name: "mbox_loss"
type: "MultiBoxLoss"
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 21
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: MAX_NEGATIVE
}
}


五. 代码



