基于深度学的目标检测方法三之基于回归的方法
基于回归的方式就是彻底的去掉了region思想,也不使用RPN,直接在一个网络中进行回归和分类。其代表的方法主要有YOLO和SSD。由于减少了一个网络同时可以减少一些重复的计算,所以其在速度上有了较大的提升。
- YOLO
YOLO的思想是将一幅图分成SxS个网格,然后让每个网格负责检测物体中心落在这个网格上的物体。
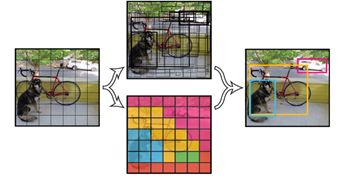
其中,每个网格负责预测一个物体,输出这个物体的每个位置坐标,以及这个物体每个位置坐标对应的conference(这个网格所属物体的类别概率)。因此输出的大小是![]() ,其中
,其中![]() 表示网格的个数,
表示网格的个数,![]() 表示每个网格预测的候选框个数,
表示每个网格预测的候选框个数,![]() 表示需要预测的类别数。其中
表示需要预测的类别数。其中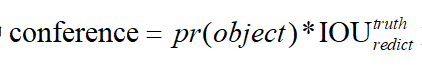 如果有Object则第一项是1,没有则第一项是0。具体网络结构如下:
如果有Object则第一项是1,没有则第一项是0。具体网络结构如下:
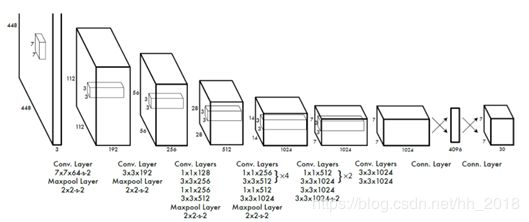
根据网络结构得出了每个class的概率和对应的位置。最后根据概率和位置得出联合函数 ,根据score的阀值和以及NMS过滤掉一部分的候选框得出对应的值。
,根据score的阀值和以及NMS过滤掉一部分的候选框得出对应的值。
对于YOLO来说使用的是7x7的格子,每个格子预测出两个Bounding box框,因此总共预测出了7X7X2=98个Bounding box。
优缺点:
(1):速度快,其增强版在Tian X GPU上能跑到45fps,简化版能达到155fps。
(2):对靠的比较近的物体以及小物体效果不好,因为默认的每一个格子只检测一个物体。
(3):由于格子是方正的,所对于一些不常见的形状泛化能力较差。
YOLOV2(YOLO9000)
YOLOV2主要是在YOLO上进行了大规模的改进,提高了MAP值,保证了速度,是目前在速度方面做得最好的模型。其具体改进方面如下:
(1):过拟合方面:去掉了dropout层,根据inception net的思想选择了Bath Normalization在每一层的输入进行归一化,使输入的数据有相同的分布,加速学习的效率也避免过拟合。
(2):改变模型的输入:目前对于一些常见的模型均是在ImageNet上进行预训练,然后在新的数据集上进行微调的,对于YOLOV1来说存在一个问题就是ImageNet使用的是224X224的分辨率作为输入,但是低分辨率不利于检测,所以训练检测模型时直接以448X448作为基础,这样直接使用预训练的分辨率迁移就会导致网络对新分辨率的适应性变差,因此YOLOV2在ImageNet上训练分类模型时添加了把448X448转化为224X224的微调部分,使其在输入的时候直接适应高分辨率,这样整个模型的MAP提高了约4%。
(3):使用锚点(anchor boxes):在YOLOV1中,由于输出的图片被划分成了7X7的格子,每个格子使用了2个边框,最后采用全连接的方式直接对边界框进行预测。由于在选取的时候是根据具体图片的宽和高进行的,因此对于图片中的不同宽度比和不同高度比的物体定位较为困难。YOLOV2采用Faster R-CNN中的anchor的思想,对特征图中的每个锚点进行预测,预测的预选框形状是事先预测好的,然后对每一个框预测4个坐标值,一个置信度和个类别数(和Faster不一样,这是直接基于预选框做预测)。在模型的输入上,使用416X416的输入经过32倍下采样之后变成13X13的奇数大小,因为奇数大小在划分格子的时候整个图只有一个中心区域,对于一副图中,大的对象一般会占据图像的中心,所以希望用一个区域预测。相对于YOLOV1此时的Box盒子反而变多。
(4):候选框大小:YOLOV2采用对数据集进行聚类的方式,找出对应的5个先验框作为预测过程中的anchor方法采用的框。
(5):添加passthrough层:即将低层大区域特征转化成小区域和高层小区域融合以达到特征融合的目的解决小目标问题。具体流程如下:
对于一个26X26的特征,抽取2X2的区域将转化为通道数(变成4个通道)。
(6):多尺度训练,由于YOLOV2去掉了全连接层,因此同一个网络可以对不同的输入尺寸进行训练。增强了模型的鲁棒性,当然改变尺寸也就意味着要对模型输出后的检测层进行修改。
(7):使用新的Darknet-19网络结构。
基于上述改进,行成了现在的YOLOV2网络结构图。其具体如下:

YOLO9000的结构和YOLOv2的相同,区别在于YOLO9000可以识别9000类的物品。采用了分类和检测联合训练的策略,在ImageNet上训练分类,在COCO数据集上训练检测,这样就可以扩充检测出的类别(因为ImageNet上的类别是比较多的),由于两个物体种类并不是完全互斥的,因此采用一种层级的方法,建立一个树结构,在预测时会给出一个区域和树状概率图,根据树的分支找到对应的概率图就是所需要的类别。
YOLOV3
YOLOV3更多的是一种总结性的东西,其主要是在YOLOV2的基础上有以下几方面的改进:
(1):改变预测函数,使用逻辑回归预测即将softmax改为sigmoid。主要是有的物品也许不属于一类。比如woman即属于woman也属于man。
(2):改变网络结构:加入残差的思想以加深网络的构造,将网络扩深为Darknet-53。
(3):采用FPN的思想,多个尺度相融合来进行预测。
SSD
SSD是一种采用高低尺度相结合的策略,基于回归的一种模型,在实现上采用VGG16网络为基础。去掉最后的全连接层改成卷积层,增加4个卷积层来构造网络结构。然后结合前面部分高纬度的网络结构,总共挑选出5个卷积层分别使用3X3的卷积计算,然后并行生成两个分支,一个是用来分类的,一个是用来预测边框的。最后在将所有的分支在通道上进行拼接(类似于inception),最终利用softmax进行分类。其具体流程大概如下:
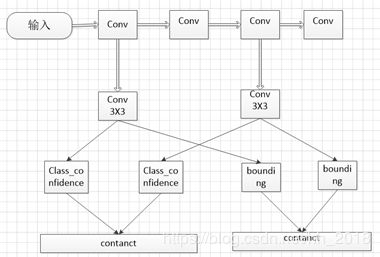
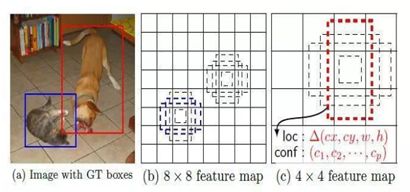
在该算法中,需要生成预测框的坐标,该预测框的生成方式借鉴了Faster中anchor的思想,在feature map的小格子上(借鉴了YOLO)均有一系列的defeat box(图中的虚线框),然后对每个defeat box均预测坐标值和类别。由于每个feature map的大小不一样,所以对应的defeat box框的比例也不一样。
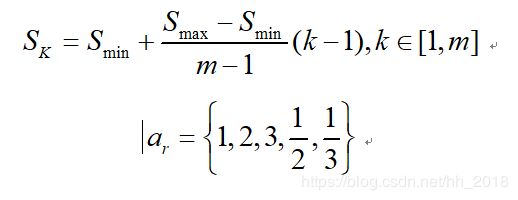
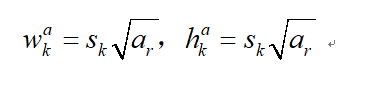
其中![]() 表示第
表示第![]() 个feature map ,
个feature map ,![]() 表示最底层 的scale,
表示最底层 的scale,![]() 表示最高层的scale。
表示最高层的scale。