pytorch一步一步在VGG16上训练自己的数据集
准备数据集及加载,ImageFolder
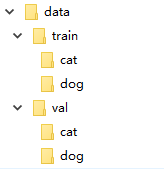
在很多机器学习或者深度学习的任务中,往往我们要提供自己的图片。也就是说我们的数据集不是预先处理好的,像mnist,cifar10等它已经给你处理好了,更多的是原始的图片。比如我们以猫狗分类为例。在data文件下,有两个分别为train和val的文件夹。然后train下是cat和dog两个文件夹,里面存的是自己的图片数据,val文件夹同train。这样我们的数据集就准备好了。
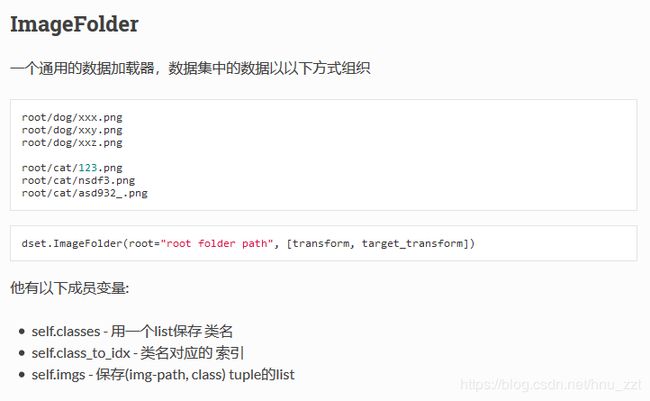
ImageFolder能够以目录名作为标签来对数据集做划分,下面是pytorch中文文档中关于ImageFolder的介绍:
#对训练集做一个变换
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224), #对图片尺寸做一个缩放切割
transforms.RandomHorizontalFlip(), #水平翻转
transforms.ToTensor(), #转化为张量
transforms.Normalize((.5, .5, .5), (.5, .5, .5)) #进行归一化
])
#对测试集做变换
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
train_dir = "G:/data/train" #训练集路径
#定义数据集
train_datasets = datasets.ImageFolder(train_dir, transform=train_transforms)
#加载数据集
train_dataloader = torch.utils.data.DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
val_dir = "G:/datat/val"
val_datasets = datasets.ImageFolder(val_dir, transform=val_transforms)
val_dataloader = torch.utils.data.DataLoader(val_datasets, batch_size=batch_size, shuffle=True)
迁移学习以VGG16为例
下面是迁移代码的实现:
class VGGNet(nn.Module):
def __init__(self, num_classes=2): #num_classes,此处为 二分类值为2
super(VGGNet, self).__init__()
net = models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
net.classifier = nn.Sequential() #将分类层置空,下面将改变我们的分类层
self.features = net #保留VGG16的特征层
self.classifier = nn.Sequential( #定义自己的分类层
nn.Linear(512 * 7 * 7, 512), #512 * 7 * 7不能改变 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
完整代码如下
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import numpy as np
from torchvision import models
batch_size = 16
learning_rate = 0.0002
epoch = 10
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
val_transforms = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.ToTensor(),
transforms.Normalize((.5, .5, .5), (.5, .5, .5))
])
train_dir = './VGGDataSet/train'
train_datasets = datasets.ImageFolder(train_dir, transform=train_transforms)
train_dataloader = torch.utils.data.DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
val_dir = './VGGDataSet/val'
val_datasets = datasets.ImageFolder(val_dir, transform=val_transforms)
val_dataloader = torch.utils.data.DataLoader(val_datasets, batch_size=batch_size, shuffle=True)
class VGGNet(nn.Module):
def __init__(self, num_classes=3):
super(VGGNet, self).__init__()
net = models.vgg16(pretrained=True)
net.classifier = nn.Sequential()
self.features = net
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 512),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
#--------------------训练过程---------------------------------
model = VGGNet()
if torch.cuda.is_available():
model.cuda()
params = [{'params': md.parameters()} for md in model.children()
if md in [model.classifier]]
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_func = nn.CrossEntropyLoss()
Loss_list = []
Accuracy_list = []
for epoch in range(100):
print('epoch {}'.format(epoch + 1))
# training-----------------------------
train_loss = 0.
train_acc = 0.
for batch_x, batch_y in train_dataloader:
batch_x, batch_y = Variable(batch_x).cuda(), Variable(batch_y).cuda()
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.data[0]
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.data[0]
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
train_datasets)), train_acc / (len(train_datasets))))
# evaluation--------------------------------
model.eval()
eval_loss = 0.
eval_acc = 0.
for batch_x, batch_y in val_dataloader:
batch_x, batch_y = Variable(batch_x, volatile=True).cuda(), Variable(batch_y, volatile=True).cuda()
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.data[0]
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.data[0]
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
val_datasets)), eval_acc / (len(val_datasets))))
Loss_list.append(eval_loss / (len(val_datasets)))
Accuracy_list.append(100 * eval_acc / (len(val_datasets)))
x1 = range(0, 100)
x2 = range(0, 100)
y1 = Accuracy_list
y2 = Loss_list
plt.subplot(2, 1, 1)
plt.plot(x1, y1, 'o-')
plt.title('Test accuracy vs. epoches')
plt.ylabel('Test accuracy')
plt.subplot(2, 1, 2)
plt.plot(x2, y2, '.-')
plt.xlabel('Test loss vs. epoches')
plt.ylabel('Test loss')
plt.show()
# plt.savefig("accuracy_loss.jpg")