RobotFramework环境配置二十一:数据驱动(总结)
数据驱动(总结)
RIDE提供的库:
- Create List
- Get File
- Import Variables
- Template
- ExcelLibrary
自定义库:DataCenter.py
- Read Data From Excel
- Read Excel File
- Read CSV File
- Read Column From Excel
- Get Sheet Values From Excel
一、数据驱动测试
注重于测试软件的功能性需求,也即数据驱动测试执行程序所有功能需求的输入条件。
二、总结:根据数据源,灵活地实现KISS。
- 数据较少
数据比较少的时候,可以使用 Create List, Get File & Import Variables。
创建 List 最快捷、最简单,但是处理多维列表就比较麻烦。如何创建多维列表,请查看齐道长的博客。

从 File 获取数据需要自己封装关键字,把原始数据处理并存储为列表。可以处理稍微复杂的数据,不过 File 存储的数据本身格式并不直观。
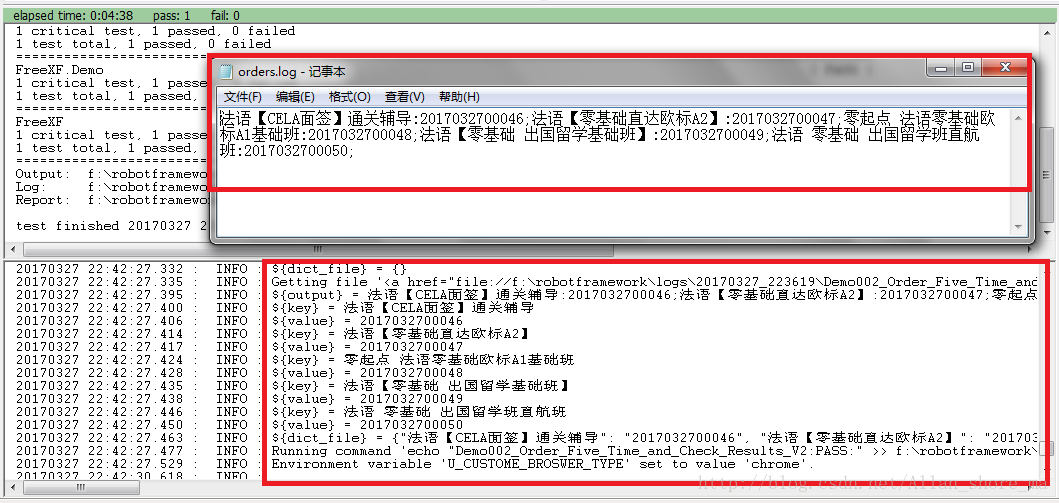
Import Variables 和 Create List 类似。相比 Create List,Import Variables 较灵活。因为 Import Variables 可以直接创建多维列表。
list1 = [[['grade1'], [5, 2, 3, 4], [6, 1, 7, 8]], [['grade2'], [1, 2, 3, 4], [5, 6, 7, 8]]]如果数据较少,比 Get Sheet Values From Excel 跟灵活。例如,在 Get Sheet Values From Excel 方法中的实例就需要把三维列表转换为二维列表。三维列表是从网页上获取并存储的数据。
def Reorgnize_List(self, alsit):
newList = []
for element in alsit:
if isinstance(element, list):
for el in element:
newList.append(natsort.natsorted(el))
OrderedData = natsort.natsorted(newList)
return OrderedData
if __name__ == '__main__':
obj = main()
list1 = [[['grade1'], [5, 2, 3, 4], [6, 1, 7, 8]], [['grade2'], [1, 2, 3, 4], [5, 6, 7, 8]]]
list2 = obj.Reorgnize_List(list1)
print list2测试新的二维列表与 Excel 中读取的数据保持一致。
list1 = [['grade1'], [5, 2, 3, 4], [6, 1, 7, 8]], ['grade2'], [1, 2, 3, 4], [5, 6, 7, 8]]- 数据较多
模板 Template,实现数据驱动简单。

但是,缺乏灵活度。比如,Read Column From Excel 方法中实现的选卡并测试每张卡所包含的课程,数据需要在关键字之间交互传递。如果写在一个关键字中,这个关键字将会过于复杂,不易管理维护。
RIDE 提供的 ExcelLibrary 功能较齐全。缺点较明显,即所有数据加上了行列值,处理起来比较麻烦。

如果不愿意修改源代码也可使用,不过在使用的时候需要小心谨慎。
最后,就是根据自身需求开发自定义关键字实现数据驱动。大家可以灵活运用,不用过于教条。
三、data_center.py 源代码
# -*- encoding = cp936 -*-
# Author: Allan
# Version: 2.0
# Data: 2017-3-20
import os, sys
import csv
import xdrlib
import xlrd
import json
import natsort
class data_center:
def __init__(self):
#Default File Path:
self.data_dir = os.getenv('G_DATACENTER', 'F:\\Robotframework\\common\\resource')
#print self.data_dir
#Current Log Path:
self.curr_dir = os.getenv('G_CURRENTLOG', 'f:\\robotframework\\logs')
#print self.curr_dir
def Read_Data_From_Excel(self, filename, path=None, includeEmptyCells=True):
"""
Returns the values from the file name specified. Returned values is separated and each sublist is one column.
Arguments:
| filename (string) | The selected Excel file that the cell values will be returned from. |
| path | Default dirctory is G_DATACENTER |
Example:
| *Keywords* | *Parameters* |
| ${data} | Read_Data_From_Excel | ExcelRobotTest.xls | %{G_DATACENTER} | includeEmptyCells=True |
"""
if path == None:
file = os.path.join(self.data_dir, filename) # Default File Path
else:
file = os.path.join(path, filename)
try:
data = xlrd.open_workbook(file)
table = data.sheets()[0]
nrows = table.nrows
nclos = table.ncols
listAll=[]
for row in range(2,nrows):
alist=[]
for col in range(1,nclos):
val = table.cell(row,col).value
# Solve issue that get integer data from Excel file would be auto-changed to float type.
alist.append(self.keep_integer_type_from_excel(val))
listAll.append(alist)
#print listAll
listAll = self.unic(listAll)
except Exception, e:
print str(e)
if includeEmptyCells is True:
return listAll
else:
newList = []
for element in listAll:
while "" in element:
element.remove("")
newList.append(natsort.natsorted(element))
OrderedData = natsort.natsorted(newList)
return OrderedData
def Read_Excel_File(self, filename, path=None, includeEmptyCells=True):
"""
Returns the values from the file name specified. Returned values is separated and each sublist is one column.
Arguments:
| filename (string) | The selected Excel file that the cell values will be returned from. |
| path | Default dirctory is G_DATACENTER |
Example:
| *Keywords* | *Parameters* |
| ${data} | Read_Excel_File | ExcelRobotTest.xls | %{G_DATACENTER} | includeEmptyCells=True |
"""
if path == None:
file = os.path.join(self.data_dir, filename) # Default File Path
else:
file = os.path.join(path, filename)
try:
data = xlrd.open_workbook(file)
table = data.sheets()[0]
nrows = table.nrows
nclos = table.ncols
listAll=[]
for row in range(2,nrows):
for col in range(1,nclos):
val = table.cell(row,col).value
# Solve issue that get integer data from Excel file would be auto-changed to float type.
value = self.keep_integer_type_from_excel(val)
# print value, type(value)
listAll.append(value)
#print listAll
listAll = self.unic(listAll)
except Exception, e:
print str(e)
if includeEmptyCells is True:
return listAll
else:
# Delete all empty data
while '' in listAll:
listAll.remove('')
return listAll
def Read_CSV_File(self, filename, path=None):
"""
Returns the values from the sheet name specified.
Arguments:
| filename (string) | The selected CSV file that the cell values will be returned from. |
| path | Default dirctory is G_DATACENTER |
Example:
| *Keywords* | *Parameters* |
| ${data} | Read_CSV_File | ExcelRobotTest.csv | %{G_DATACENTER} |
"""
if path == None:
file = os.path.join(self.data_dir, filename) # Default File Path
else:
file = os.path.join(path, filename)
data = []
with open(file, 'rb') as csvfile:
data = [each for each in csv.DictReader(csvfile)]
# reader =csv.reader(csvfile)
# for col in reader:
# data.append(col)
return self.unic(data)
def is_number(self, val):
# Check if value is number not str.
try:
float(val)
return True
except ValueError:
pass
try:
import unicodedata
unicodedata.numeric(val)
return True
except (TypeError, ValueError):
pass
def keep_integer_type_from_excel(self, value):
# Keep integer number as integer type. When reading from excel it has been changed to float type.
if self.is_number(value) and type(value) != unicode and value%1 == 0:
return str(int(value))
else:
return value
def unic(self, item):
# Resolved Chinese mess code.
try:
item = json.dumps(item, ensure_ascii=False, encoding='cp936')
except UnicodeDecodeError:
try:
item = json.dumps(item, ensure_ascii=False, encoding='cp936')
except:
pass
except:
pass
item = json.loads(item, encoding='cp936') # Convert json data string back
return item
def Read_Column_From_Excel(self, filename, column, path=None, includeEmptyCells=True):
reload(sys)
sys.setdefaultencoding('cp936')
alist = []
if path == None:
file = os.path.join(self.data_dir, filename) #Default Data Directory
else:
file = os.path.join(path, filename)
try:
excel_data = xlrd.open_workbook(file)
table = excel_data.sheets()[0]
for row_index in range(2, table.nrows):
value = table.cell(row_index, int(column)).value
print value
alist.append(self.keep_integer_type_from_excel(value))
#print alist
listAll = self.unic(alist)
except Exception, e:
print str(e)
if includeEmptyCells is True:
return listAll
else:
# Delete all empty data
while '' in listAll:
listAll.remove('')
return listAll
def Get_Sheet_Values_From_Excel(self, filename, sheetname, path=None, includeEmptyCells=True):
"""
Returns the values from the sheet name specified.
Arguments:
| Sheet Name (string) | The selected sheet that the cell values will be returned from. |
| Include Empty Cells (default=True) | The empty cells will be included by default. To deactivate and only return cells with values, pass 'False' in the variable. |
Example:
| *Keywords* | *Parameters* |
| Get Sheet Values | ExcelRobotTest.csv | TestSheet1 | %{G_DATACENTER} | includeEmptyCells=True |
"""
if path == None:
file = os.path.join(self.data_dir, filename) #Default Data Directory
else:
file = os.path.join(path, filename)
try:
excel_data = xlrd.open_workbook(file)
sheetNames = self.get_sheet_names(excel_data)
my_sheet_index = sheetNames.index(sheetname)
#print my_sheet_index
table = excel_data.sheet_by_index(my_sheet_index)
nrows = table.nrows
nclos = table.ncols
listAll=[]
for row in range(2,nrows):
alist=[]
for col in range(1,nclos):
val = table.cell(row,col).value
# Solve issue that get integer data from Excel file would be auto-changed to float type.
alist.append(self.keep_integer_type_from_excel(val))
listAll.append(alist)
#print listAll
listAll = self.unic(listAll)
except Exception, e:
print str(e)
if includeEmptyCells is True:
return listAll
else:
newList = []
for element in listAll:
while "" in element:
element.remove("")
newList.append(natsort.natsorted(element))
OrderedData = natsort.natsorted(newList)
return OrderedData
def get_sheet_names(self, wb):
"""
Returns the names of all the worksheets in the current workbook.
Example:
| *Keywords* | *Parameters* |
| ${sheetNames} | Get Sheets Names |
"""
sheetNames = wb.sheet_names()
return sheetNames