Hadoop Erasure Coding结构分析
前言
Hadoop-3.0-alpha2版本最近已经发布了,在Hadoop-3.0-alpha2版本中,社区继续fix了许多关于HDFS EC特性相关的issue。而Hadoop EC作为3.0版本中具有重大意义的feature,我们非常有必要去学习,并用好这个特性。在之前的文章中,笔者或多或少介绍过EC技术的原理知(再聊HDFS Erasure Coding)以及EC技术在Hadoop中的运用(Hadoop 3.0 Erasure Coding 纠删码功能预分析)。最近笔者重新阅读、学习了EC相关的代码,本文将要阐述的是EC在Hadoop整个工程项目中的一个结构,包括各个部分代码结构的组成以及关键代码的实现等等。
EC在Hadoop工程中的结构
首先看到这里,有些人可能会疑惑这里为什么不说是EC在HDFS中的结构呢?尽管目前EC的主要使用部分是在HDFS内部,但并不代表EC技术在未来不会被用在其它的组件上。所以社区将EC技术最最基础的部分定义在了Hadoop-Common过程下,例如EC内部中的基础块类,以及编解码算法类等等。
EC另外一部分内容的定义就自然在HDFS组件内了,比如说我们需要定义一个完全针对EC方式的数据流类:DFSStripedInputStream数据输入流类和DFSStripedOutputStream数据输出流类。总的归纳起来一句话,由于EC下的数据的条带式存储方式与原本的副本连续式的存储方式不同,这需要在许多地方做一个适配和改造。所以想要在HDFS内引入EC技术,工程量其实是不少的。笔者大致地阅读了EC相关的代码,主要存在于下面的一些HDFS模块中:
第一个,BlockManager类。EC的引入,需要在BlockManager中做多处的变更。在很多块相关处理的方法内部,需要增加是否为条带块逻辑的判断,
if(block.isStriped()){
// EC模式下的块处理逻辑
}第二个,ErasureCodingPolicyManager类。ErasureCodingPolicyManager是全新构造的一个类,用来管理EC策略类的。而EC策略类内部会包含具体将要使用到的EC编解码模式,数据块/加密块的数量组成等等。这些策略类到时会设置到具体的文件中的,类似于HDFS现有的StoragePolicy。
第三个,ECCLI。通过名称不难理解,此类就是EC的命令行接口类,主要为获取和设置EC策略的2类命令。
第四个,NamenodeFsck。此类内部也需要适配hdfs fsck命令对于EC文件块的扫描,识别。目前的代码中NamenodeFsck为EC文件构造了一份额外的结果报告。
第五个,Metric。Metric统计指标在EC中也是需要的,目前HDFS只针对EC中Reconstruction Task部分进行了metric的统计。包括重构任务中失败的task数,读取的字节数等等指标。
第六个,数据读写模块。之前在上文中也已提过,由于EC Strip方式的存储模式与传统副本的Contiguous存储方式的不同,原先的DFSInputStream/DFSOuputStream也将不再适用。社区为此实现了它们的继承子类DFSStripedInputStream、DFSStripedOutputStream。此部分内容在下文中还将会具体提到。
第七个,其它部分。其它部分指的是HDFS内部其它地方对于EC做出的小小适配,比如说Balancer/Mover块转移相关的部分,或者说是EC文件的数据保存,它是如何将EC相关的信息持久化到fsimage中的,又或者说EC文件的块恢复是怎么做的等等。这些都是更加细节方面的内容了,感兴趣的同学可以自行做更为深入的分析和学习。
综述所述的结构,大致为下图所示的结构:
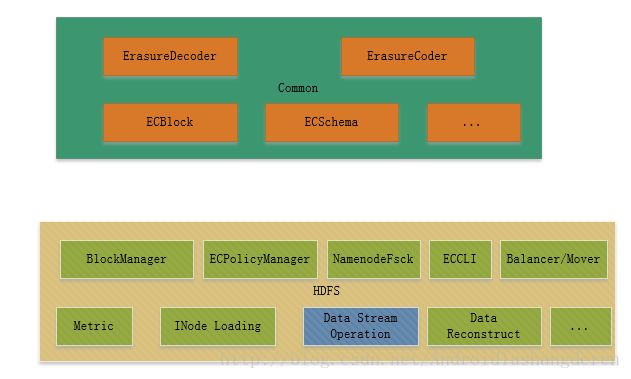
图1-1 Hadoop EC结构
EC部分关键点的实现逻辑
下面笔者来谈谈几个EC的关键点实现逻辑。
EC下的数据流操作
EC下的数据流操作实质上指的是数据流类DFSStripedInputStream/DFSStripedOutputStream是如何被使用的。笔者在阅读此类代码的时候,发现其中会有一个独特的编/解码类。此类的作用是将dataBlock和parityBlock数据进行编/解码处理。按照读取数据时进行解密处理,写入数据时进行编码处理的原则,DFSStripedInputStream包含的是ErasureEncoder对象而DFSStripedOutputStream用的则是EnsureDecoder对象。
ErasureEncoder、EnsureDecoder这种涉及到具体EC算法的编码类是从哪里传进来的呢?其实通过代码不难发现,答案是从文件中的ECPolicy中取来的。ECPolicy就是在这个时候被应用到文件数据中的。我们再来看一个更加原始的问题,DFSStripedInputStream/DFSStripedOutputStream是怎么生存的呢?这里要从DFSClient端说起了,DFSClient通过open方法创建出数据输入流准备进行数据的读取,通过create方法创建出输出流对象进行数据的写入。
所以EC下的数据流模型如图1-2所示:

图1-2 EC数据读写模型
EC相关数据的持久化
这部分的内容笔者一直觉得比较好奇的,最近也花了一些时间进行学习,最终发现可能这里的持久化还不能称之为完全的持久化。当然了,首先EC数据文件也是用INodeFile类进行存储的,最终也会被持久化到FSImage中。但是在持久化的数据中,它与笔者原本所想的有些不一样。主要为下面2点:
- EC文件区别于普通INodeFile文件,最大的区别是它引入了ECPolicy这个对象,里面包含了具体EC算法的很多信息。如果按照正常逻辑,
应该是也要被持久化到FSImage中的,但是这里只存了一个ECPolicy Id。 - 基于上一点ECPolicy Id的存储,HDFS内部并不是另起一个新的字段来存储这个id,而是与replication复用了同一个字段。因为在EC中
其实是不应该有副本的概念的,它本身就能够做数据恢复。所以当在EC文件时,这里讲ECPolicy id赋给了replication字段,同时也节省
了字段空间。
然后EC文件做数据恢复的时候,是通过反向获取的方式得到ECPolicy具体信息的。相关代码如下:
// 加载INodeFile文件对象
private INodeFile loadINodeFile(INodeSection.INode n) {
assert n.getType() == INodeSection.INode.Type.FILE;
INodeSection.INodeFile f = n.getFile();
List bp = f.getBlocksList();
// 获取文件副本值
short replication = (short) f.getReplication();
// 获取块类型
BlockType blockType = PBHelperClient.convert(f.getBlockType());
LoaderContext state = parent.getLoaderContext();
// 根据块类型得到ECPolicy策略信息,id为副本值
ErasureCodingPolicy ecPolicy = (blockType == BlockType.STRIPED) ?
ErasureCodingPolicyManager.getPolicyByPolicyID((byte) replication) :
null;
// 进行块信息的恢复
BlockInfo[] blocks = new BlockInfo[bp.size()];
for (int i = 0; i < bp.size(); ++i) {
BlockProto b = bp.get(i);
if (blockType == BlockType.STRIPED) {
blocks[i] = new BlockInfoStriped(PBHelperClient.convert(b), ecPolicy);
} else {
blocks[i] = new BlockInfoContiguous(PBHelperClient.convert(b),
replication);
}
}
...
} 上述代码为FSImageFormatPBINode类中的代码,在反向加载FSImage中会用到。下面是笔者个人的观点:
- 这种持久化的方式其实是一种简化版的持久化方案,它本身没有持久化ECPolicy的信息,在一定程度上会牺牲一点效率,因为每次都要从
ErasureCodingPolicyManager中进行重新获取。 - 与replication共用一个字段是否稳妥,个人觉得如果是EC文件,这个值应该就设置为恒定值1即可,然后另行存储EC的元数据信息。这样在结构上更易理解。
关于此话题的讨论目前在社区上早已有相应的JIRA:HDFS-7869(Erasure Coding: Persist erasure coding policies in NameNode),感兴趣的同学可以到这个JIRA上看看。
参考资料
[1].Erasure Coding: Persist erasure coding policies in NameNode, https://issues.apache.org/jira/browse/HDFS-7859