python爬虫系列(2):分析Ajax 爬取搜狗高清壁纸
这次我们来分析一下Ajax(至于Ajax是什么意思请自行百度了,这里就不过多解释),爬取一些高清壁纸,等待下载到本地之后,然后我们再慢慢的筛选这些壁纸。那么这次的目标就是搜狗壁纸,啥1280*720的,1366*768的,1920*1080的统统拿下,先看一下本次目标URL :
http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD&from=home#%E5%85%A8%E9%83%A8%269
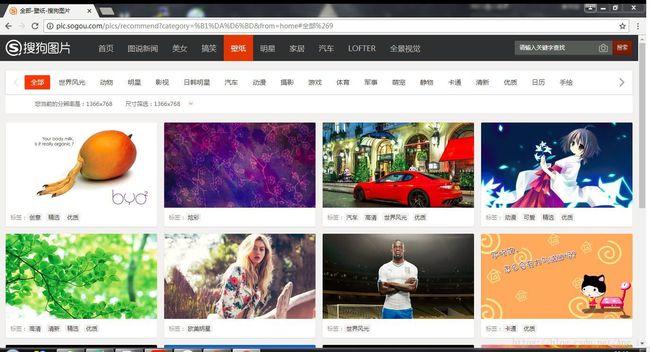
可以看到,在壁纸这一大标题之下有很多的小栏目标题,世界风光、动物、明星、影视、日韩明星、汽车......后面还有美女栏哦~~哈哈,接下来我们将这些统统纳入囊中,开始分析。
打开浏览器的开发者工具,我们在这个页面多往下翻动几页,然后观察一下,找到我们要的列表和请求的Ajax数据:
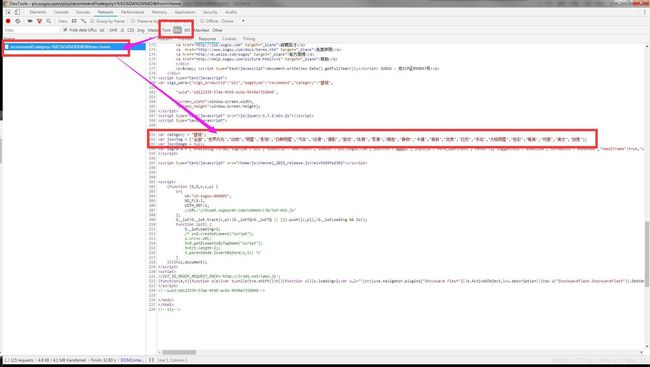

从上面可以看到,壁纸的分类在请求的html文档中有,我们可以使用正则表达式将这个分类提取出来。下面则是请求的Ajax数据:
category:壁纸
tag:全部
start:0
len:15
width:1366
height:768
大概可以知道tag就是壁纸的所属的类,start观察其他几个请求可以发现是起始页,每次增长为15(起始就是下一页),width和
height不用说就是我们期望的图片分辨率了,下面代码就是找到这些分类和我们期望的壁纸分辨率:
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
#通过输入尺寸大小和壁纸种类返回壁纸资源的url
def get_wallPaperTypeAndDpi():
dpi = ((1920, 1080), (1366, 768), (1280, 720)) #暂时只添加这几种常见的分辨率
url = 'http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD&from=home'
try:
response = requests.get(url, headers = header)
if response.status_code == 200:
allTop = re.findall('var jsonTag = (\[.*?\]);' ,response.text, re.S)
wallPaperList = allTop[0][2:-2]
wallPaperList = wallPaperList.split('","') #获取到列表
for num,item in zip(range(1,30), wallPaperList):
print(num, item)
type_num = input('输入期望的壁纸类型:')
for num,(x,y) in zip(range(1,4), dpi):
print(num, x, '*',y)
dpi_num = input('输入期望的壁纸类型:')
print(wallPaperList[int(type_num) - 1],dpi[int(dpi_num) - 1])
return wallPaperList[int(type_num) - 1],dpi[int(dpi_num) - 1]
else:
print('response.status_code = ', response.status_code)
except:
print('请求失败或者输入有误!')然后构造url:
#获取其中一类图片的资源列表
def get_url(dpi = (1920, 1080), start = 0, picType = '全部'):
params = {
'category': '壁纸',
'tag': picType,
'start': start,
'len': '15',
'width': dpi[0],
'height': dpi[1],
}
print(params)
return 'http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?' + urlencode(params)我们在这些其中一个图片点击进去之后,可以看到有一个下载字样,我们点击这个下载,然后图片就自动下载了。我们在图片下载的地方可以看到这个图片的下载链接为:
http://imgstore02.cdn.sogou.com/v2/thumb/dl/11546631.jpg?appid=10150005&referer=sogou.com&url=https://img01.sogoucdn.com/app/a/100520021/7dd43e802a873bf2d9eff8b7488618b7
再看一下之前请求的Ajax数据里面,去all_items里面找一找,可以发现一些规律,id=11546631,pic_url = https://img01.sogoucdn.com/app/a/100520021/7dd43e802a873bf2d9eff8b7488618b7,这个和图片的下载地址貌似找到了联系,这样就可以断定,图片的高清下载地址就是:
http://imgstore02.cdn.sogou.com/v2/thumb/dl/' + id + '.jpg?appid=10150005&referer=sogou.com&url=' + pic_url,

然后在js脚本里搜索一下imgstore关键字,发现确实就是我们想的那样,下载地址就是那样构造的:
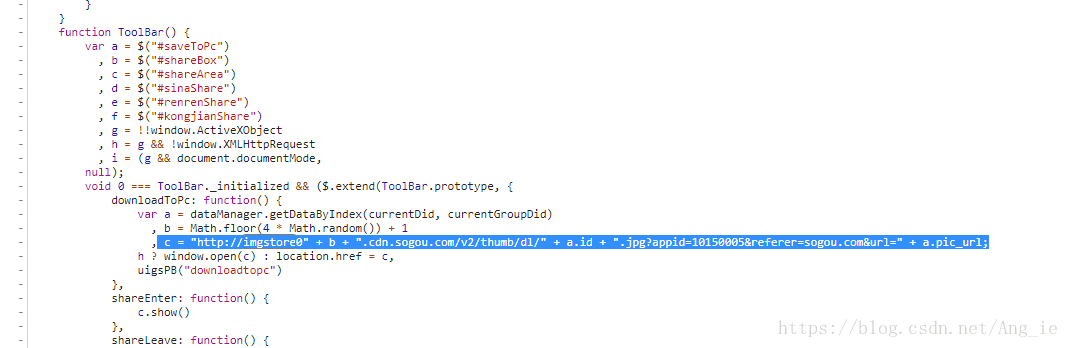
只是那个b值是随机构造的,所以我们就写一个固定值,1-4都是可以的,所以就可以写出得到高清图片的下载地址函数:
#获取图片的下载url
def get_imageUrl(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
all_items = response.json().get('all_items')
if all_items != None:
for item in all_items:
pic_url = item.get('pic_url')
id = item.get('id')
yield {
'url' : 'http://imgstore04.cdn.sogou.com/v2/thumb/dl/' + str(id) + '.jpg?appid=10150005&referer=sogou.com&url=' + pic_url,
'title' : str(id) + '.jpg'
}最后得到了高清的壁纸图片下载链接,就直接拿这个链接地址去下载就好了,下面是下载保存图片的方法:
#保存图片
def save_image(image_info):
global COUNT
savePath = 'F:\\picture\\wallPaper\\'
try:
response = requests.get(image_info.get('url'), headers=header)
savePath = savePath + image_info.get('title')
if response.status_code == 200:
if not os.path.isfile(savePath):
with open(savePath, 'wb') as f:
f.write(response.content)
print(image_info.get('title'),' ->OK\n')
COUNT += 1 #用于计数成功下载了多少张图片
except requests.ConnectionError:
print('保存图片失败.')最后将所有的代码都贴上:
import re,os
import requests
from urllib.parse import urlencode
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
COUNT = 0
#通过输入尺寸大小和壁纸种类返回壁纸资源的url
def get_wallPaperTypeAndDpi():
dpi = ((1920, 1080), (1366, 768), (1280, 720)) #暂时只添加这几种常见的分辨率
url = 'http://pic.sogou.com/pics/recommend?category=%B1%DA%D6%BD&from=home'
try:
response = requests.get(url, headers = header)
if response.status_code == 200:
allTop = re.findall('var jsonTag = (\[.*?\]);' ,response.text, re.S)
wallPaperList = allTop[0][2:-2]
wallPaperList = wallPaperList.split('","') #获取到列表
for num,item in zip(range(1,30), wallPaperList):
print(num, item)
type_num = input('输入期望的壁纸类型:')
for num,(x,y) in zip(range(1,4), dpi):
print(num, x, '*',y)
dpi_num = input('输入期望的壁纸类型:')
print(wallPaperList[int(type_num) - 1],dpi[int(dpi_num) - 1])
return wallPaperList[int(type_num) - 1],dpi[int(dpi_num) - 1]
else:
print('response.status_code = ', response.status_code)
except:
print('请求失败或者输入有误!')
#获取其中一类图片的资源列表
def get_url(dpi = (1920, 1080), start = 0, picType = '全部'):
params = {
'category': '壁纸',
'tag': picType,
'start': start,
'len': '15',
'width': dpi[0],
'height': dpi[1],
}
print(params)
return 'http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?' + urlencode(params)
#获取图片的下载url
def get_imageUrl(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
all_items = response.json().get('all_items')
if all_items != None:
for item in all_items:
pic_url = item.get('pic_url')
id = item.get('id')
yield {
'url' : 'http://imgstore04.cdn.sogou.com/v2/thumb/dl/' + str(id) + '.jpg?appid=10150005&referer=sogou.com&url=' + pic_url,
'title' : str(id) + '.jpg'
}
#保存图片
def save_image(image_info):
global COUNT
savePath = 'F:\\picture\\wallPaper\\'
try:
print(image_info.get('url'))
response = requests.get(image_info.get('url'), headers=header)
savePath = savePath + image_info.get('title')
if response.status_code == 200:
if not os.path.isfile(savePath):
with open(savePath, 'wb') as f:
f.write(response.content)
print(image_info.get('title'),' ->OK\n')
COUNT += 1
except requests.ConnectionError:
print('Failed to Save Image.')
picType,dpi = get_wallPaperTypeAndDpi()
for num in range(0, 90, 15):
imageUrl = get_imageUrl(get_url(dpi, num, picType))
for x in imageUrl:
save_image(x)
print('总共下载%d张'%COUNT)运行结果图,有些重复的图片,但是分辨率是不同的:
