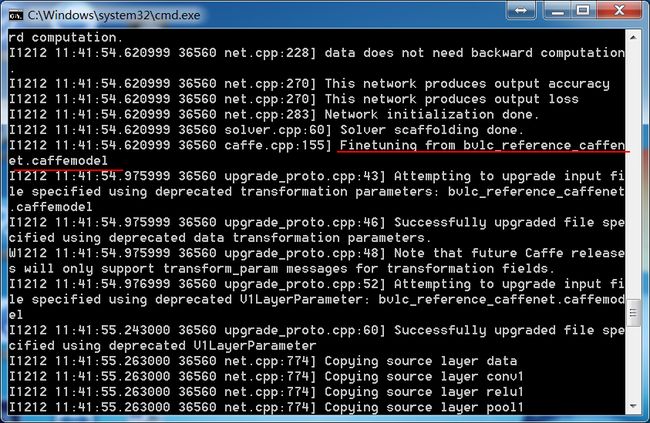
用已有模型进行微调 finetune
一、 准备数据集
可以下载我的练习数据:http://pan.baidu.com/s/1MotUe,放在data/re根目录下。
这些数据共有500张图片,400张用于训练,100张用于测试。分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。
在examples/根目录下新建文件夹 mydata1,在此文件夹内放入训练集、测试集等相关文件。
1. 训练集
1)创建训练集
在examples/mydata1根目录下,新建imgtrainset文件夹 和 train.txt 文本文件
(注意: txt文件内,类别必须从0开始标注,不能从3开始)

2)利用caffe现成的convert_imageset程序,把训练集从img格式转换成lmdb格式(需要归一到相同尺寸227*227),并且gray为false(caffenet网络模型输入的是三通道图片),并且需要打乱数据集(不能全0后面跟全1,再跟全2,以此类推),所以一定要加shuffle=true,不然训练的时候会出错(loss会很大)
新建convert_image_traindata.bat,内容如下:
SET GLOG_logtostderr=1
E:\study_materials\Caffe\caffe-master\caffe-master\Build\x64\Release\convert_imageset.exe imgtrainset/ train.txt train_modelre_lmdb -resize_width=227 -resize_height=227--backend=lmdb --gray=false--shuffle=true
pause

则在examples/mydata1根目录下,就会多一个文件:train_modelre_lmdb
2. 测试集
1)创建测试集
在examples/mydata1根目录下,新建imgtestset文件夹 和 val.txt 文本文件
(同样的,txt文件内必须从0开始)

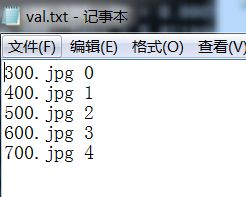
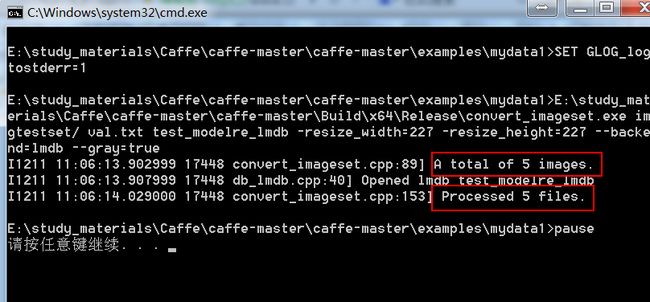
2)利用caffe现成的convert_imageset程序,把测试集从img格式转换成lmdb格式
新建convert_image_testdata.bat,内容如下:
SET GLOG_logtostderr=1
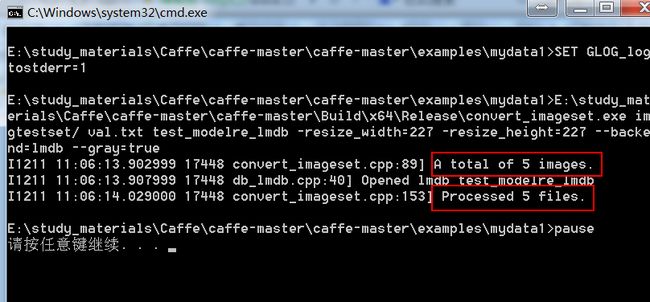
E:\study_materials\Caffe\caffe-master\caffe-master\Build\x64\Release\convert_imageset.exe imgtestset/ val.txt test_modelre_lmdb -resize_width=227 -resize_height=227 --backend=lmdb --gray=false --shuffle=true
pause

则在examples/mydata1根目录下,就会多一个文件:test_modelre_lmdb
二、 计算数据集的均值文件(均值文件只有一个(由训练集生成的))
在examples/mydata1根目录下新建image_mean_train.bat ,内容如下:
E:\study_materials\Caffe\caffe-master\caffe-master\Build\x64\Release\compute_image_mean.exe E:\study_materials\Caffe\caffe-master\caffe-master\examples\mydata1\train_modelre_lmdb E:\study_materials\Caffe\caffe-master\caffe-master\examples\mydata1\modelre_train_mean.binaryproto --backend=lmdb

则在examples/mydata1根目录下,就会多一个文件:modelre_train_mean.binaryproto
三、 修改网络(调整网络层参数)
修改train_val.prototxt文件内容
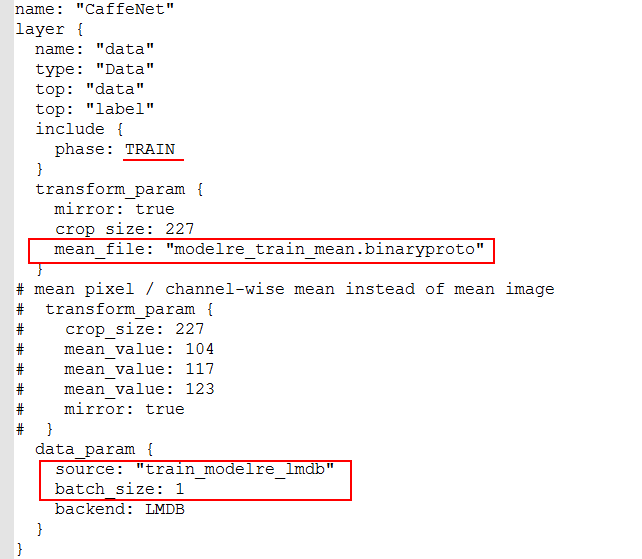
1.训练部分修改 (因为训练集不多,所以batch_size可以设置为1,不过训练会比较慢)
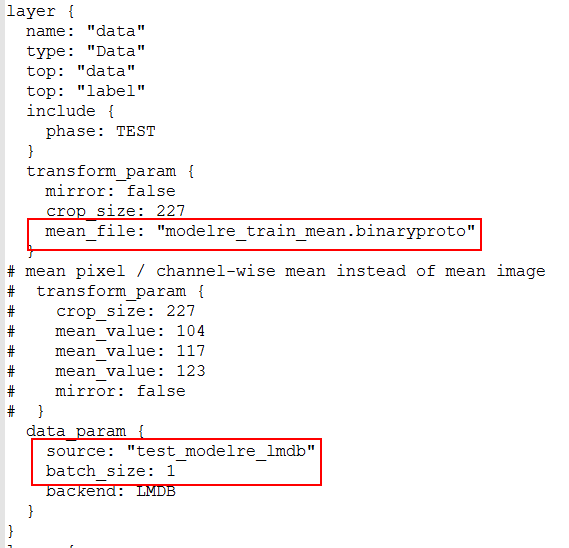
2.测试部分修改
3.fc8层修改(修改名字之后,这样预训练模型赋值的时候这里就会因为名字不匹配从而自动的进行重新训练)

四、 修改Solver参数
修改solver.prototxt文件内容
- test_iter从1000改为了5(因为我用的测试集很少,每一类一个,一共5个,而batch_size我设置了1,所以5/1=5),因为数据量减少了。
- base_lr从0.01变成了0.0001(一开始我设置了0.001,一直出现loss=1.#QUAN的情况),这个很重要,微调时的基本学习速率不能太大。
- 学习策略lr_policy没有改变(依旧为step)。
- 步长stepsize从原来的100000变成了200。
- 最大的迭代次数max_iter也从450000变成了1000。
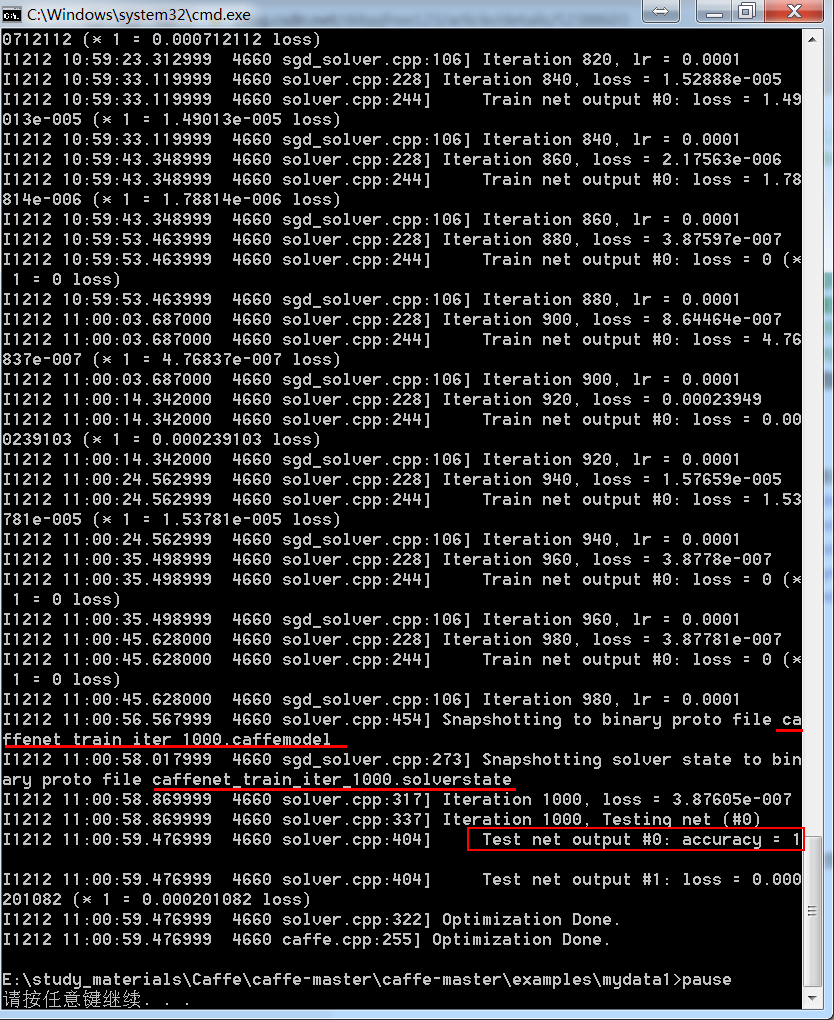
- 而test_interval和snapshot则根据自己的喜好设置,一个是设置多少次输出accuracy;一个是设置多少次输出一次caffemodel和solverstate。
参考资料:
http://blog.csdn.net/helloworldding/article/details/76559855
https://www.cnblogs.com/louyihang-loves-baiyan/p/5038758.html
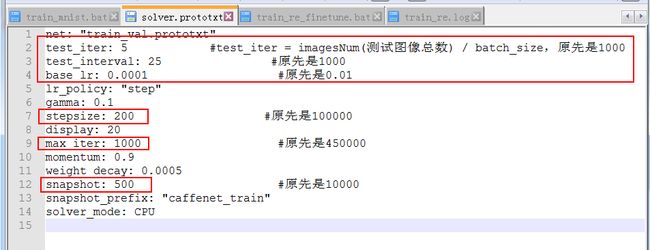
参数设置说明
1.训练样本
总共:25个batch_size:1
将所有样本处理完一次(称为一代,即epoch)需要:25/1=25 次迭代才能完成
所以这里将test_interval设置为25,即处理完一次所有的训练数据后,才去进行测试。所以这个数要大于等于25.
如果想训练40代,则最大迭代次数为1000;
2.测试样本
同理,有5个测试样本,batch_size为1,那么需要5次才能完整的测试一次。 所以test_iter为5;这个数要大于等于5.3.学习率
学习率变化规律我们设置为随着迭代次数的增加,慢慢变低。总共迭代1000次,我们将变化5次,所以stepsize设置为1000/5=200,即每迭代200次,我们就降低一次学习率。
4. Step 学习策略

(注:stepsize不能太小,如果太小会导致学习率再后来越来越小,达不到充分收敛的效果)
五、 启动训练,加载预训练模型微调
train -solver solver.prototxt -weights bvlc_reference_caffenet.caffemodel
2>&1 | tee train_re.log
pause