冠字号查询系统中HBase写入数据性能测试
机器说明:4台centos虚拟机,每台分别配置2G内存
测试步骤:
为了方便测试,利用hbase shell新建表如下:
create 'identify01', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify02', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify03', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify04', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify05', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify07', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify08', {NAME => 'op_www', VERSIONS => 1000},SPLITS => ['AAAR3333','AABI6666']
create 'identify09', {NAME => 'op_www', VERSIONS => 1000},
SPLITS => [' AAAK3999',' AAAU7999',' AABF1999',' AABP5999']
1. 利用hbase2hbase的MR程序将表'identify_rmb_records'的数据分别导入上述建立的表中。
2. 按照冠字号生成规则,随机生成10w条、20w条数据分别保存在test_10.txt、test_20.txt中。
3. 读取test_10.txt文件数据,然后利用HBase Java API单线程将数据插入identify01表中、利用HBase Java API多线程(5线程,每线程10w条数据)将数据插入identify03表中、利用HBase Java API多线程(10线程,每线程10w条数据)将数据插入identify04表中。
4. 读取test_20.txt文件数据,然后利用HBase Java API单线程将数据插入identify02表中、利用HBase Java API多线程(5线程,每线程20w条数据)将数据插入identify05表中。
5. 将test_10.txt、test_20.txt文件上传到hdfs上,然后利用MR(3个region)将test_10.txt中数据插入到identify07表中、利用MR(3个region)将test_20.txt中数据插入到identify08表中、利用MR(5个region)将test_10中数据插入到identify09表中。
测试结果:
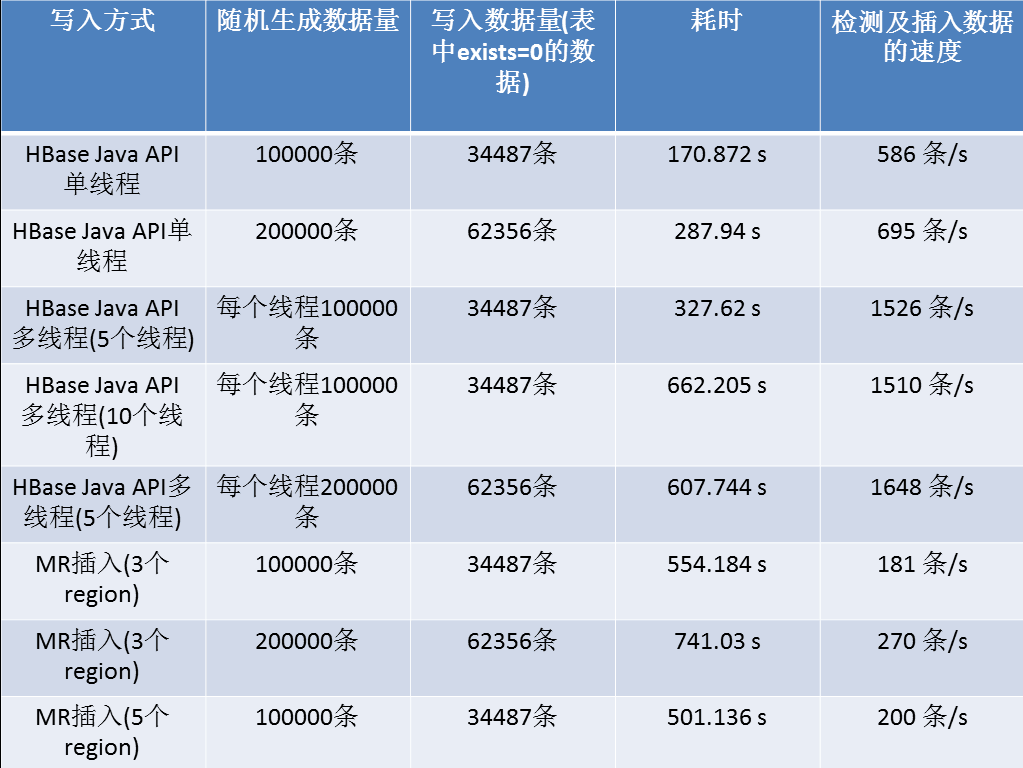
测试总结:
由上述结果可以看出,最适合冠字号查询系统的写入方法是利用HBase Java API多线程的方式。因为冠字号查询系统的目的就是为了实现快速读写,而MR的话,启动
时间开销太大,并且MR更适合做离线数据处理,而不是在线实时数据分析。
测试代码:
HBaseJava API 单线程:
package write;
import java.io.IOException;
import java.util.Date;
import java.util.List;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import demo.Utils;
public class WriteTest {
public static long putData(String tableName,Connection connection,List rowkeys) throws IOException{
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = null;
long start =System.currentTimeMillis();
long count =0;
long putNums = 0;
try {
for(byte[] rowkey:rowkeys){
count++;
put = Utils.generatePutFromRow(rowkey, "1");
if(table.checkAndPut(rowkey, Utils.OP_WWW,
Utils.COL_EXIST, Bytes.toBytes("0"), put)){
putNums++;
}
if (count % 1000 == 0) {
System.out.println("count:"+count);
}
}
long end = System.currentTimeMillis();
System.out.println(new Date()+":"+rowkeys.size()+"条记录,读取耗时:"+(end-start)*1.0/1000+"s");
return putNums;
} catch (Exception e) {
table.close();
return putNums;
}
}
}
package write;
import java.io.IOException;
import java.util.Date;
import java.util.List;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import demo.Utils;
public class WriteThread implements Runnable {
private List rks;
private Table table;
public WriteThread(String tableName ,List rks) throws IOException {
this.table =Utils.getConn().getTable(TableName.valueOf(tableName));
this.rks = rks;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" "+new Date()+":开始读取记录...");
Put put = null;
long count =0;
long putNums = 0;
long start =System.currentTimeMillis();
try{
for(byte[] rowkey:rks){
count++;
put = Utils.generatePutFromRow(rowkey, "1");
if(table.checkAndPut(rowkey, Utils.OP_WWW,
Utils.COL_EXIST, Bytes.toBytes("0"), put)){
putNums++;
}
if (count % 1000 == 0) {
System.out.println("count:"+count);
}
}
long end = System.currentTimeMillis();
System.out.println(Thread.currentThread().getName()+" "+new Date()
+":"+rks.size()+"条记录,读取耗时:"+(end-start)*1.0/1000+"s");
}catch(Exception e){
e.printStackTrace();
}
}
} identify01- identify05测试main入口:
package write;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.util.ToolRunner;
import org.apache.jasper.tagplugins.jstl.core.If;
import demo.ReadThread;
import demo.Utils;
import hbase2hbase.HBaseToHBase;
public class AllTest {
public static List list_10; //保存10w条数据
public static List list_20; // 保存20w条数据
public static void main(String[] args) throws Exception {
// 随机生成测试数据并写入到txt中
// list_10 = Utils.generateRowKey(100000);
// list_20 = Utils.generateRowKey(200000);
// writeToFile("C:\\Users\\Administrator\\Desktop\\test_10.txt", list_10);
// writeToFile("C:\\Users\\Administrator\\Desktop\\test_20.txt", list_20);
list_10 = readFromFile("C:\\Users\\Administrator\\Desktop\\test_10.txt");
list_20 = readFromFile("C:\\Users\\Administrator\\Desktop\\test_20.txt");
// 测试单线程写入identify01数据库10w条数据
System.out.println(WriteTest.putData("identify01",
Utils.getConn(), list_10));
// 测试单线程写入identify02数据库20w条数据
System.out.println(WriteTest.putData("identify02",
Utils.getConn(), list_20));
// 测试多线程写入identify03数据库10w条数据
int threadSize1 = 5;
for(int i=0;i list) throws IOException{
FileWriter fw = new FileWriter(fileName);
BufferedWriter bw = new BufferedWriter(fw);
for (byte[] bs : list) {
bw.write(new String(bs)+"\n");
}
bw.close();
fw.close();
}
public static List readFromFile(String fileName) throws IOException{
List list = new ArrayList<>();
BufferedReader bf = new BufferedReader(new FileReader(fileName));
String read = null;
while ((read =bf.readLine()) != null ) {
list.add(Bytes.toBytes(read));
}
bf.close();
return list;
}
}
package demo;
import java.io.IOException;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class Utils {
public static String TABLE = "identify_rmb_records";
private static DecimalFormat df = new DecimalFormat( "0000" );
public static String[] crownSizePrefixes =null;
static Random random = new Random();
public static byte[] OP_WWW = Bytes.toBytes("op_www");
public static byte[] COL_EXIST = Bytes.toBytes("exists");
static {
crownSizePrefixes = new String[26*2];
for (int i = 0; i < crownSizePrefixes.length/2; i++) {
crownSizePrefixes[i] = "AAA" + (char) (65 + i);
crownSizePrefixes[i+26] = "AAB" + (char) (65 + i);
}
}
public static Put generatePutFromRow(byte[] row, String exist) {
Put put = null;
try {
put = new Put(row);
put.addColumn(OP_WWW, COL_EXIST, Bytes.toBytes(exist));
} catch (Exception e) {
e.printStackTrace();
}
return put;
}
/**
* 把0~9999 转为 0000~9999
* @param num
* @return
*/
public static String formatCrownSizeSuffix(int num){
return df.format(num);
}
public static Table getTable() throws IOException{
return getConn().getTable(TableName.valueOf(TABLE));
}
public static String getRandomCrownSize(){
return crownSizePrefixes[random.nextInt(crownSizePrefixes.length)]
+formatCrownSizeSuffix(random.nextInt(10000));
}
public static Connection getConn() throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.master", "master:16000");// 指定HMaster
conf.set("hbase.rootdir", "hdfs://master:8020/hbase");// 指定HBase在HDFS上存储路径
conf.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");// 指定使用的Zookeeper集群
conf.set("hbase.zookeeper.property.clientPort", "2181");// 指定使用Zookeeper集群的端口
Connection connection = ConnectionFactory.createConnection(conf);// 获取连
return connection;
}
public static List generateRowKey(long size){
System.out.println(new Date()+"开始生成"+size +"条记录...");
long start =System.currentTimeMillis();
List rowkeys = new ArrayList<>();
for(int i=0;i hbase2hbase的MR Driver:
package hbase2hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Job Driver驱动类
* @author wmh
*
*
*
*/
public class HBaseToHBase extends Configured implements Tool {
public static String FROMTABLE=null;
@Override
public int run(String[] args) throws Exception {
if(args.length!=2){
System.err.println("Usage:\n ImportToHBase \n rowkey file path");
return -1;
}
Configuration conf = getConf();
String jobName ="From table "+FROMTABLE;
FROMTABLE = args[0];
conf.set("filePath", args[1]);
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(HBaseToHBase.class);
// 设置HBase表输入:表名、scan、Mapper类、mapper输出键类型、mapper输出值类型(提示:参考ExportFromHBase)
TableMapReduceUtil.initTableMapperJob(
FROMTABLE,
new Scan(),
H2HMapper.class,
ImmutableBytesWritable.class,
Put.class,
job);
// 设置HBase表输出:表名,reducer类(提示:参考ImportToHBase)
TableMapReduceUtil.initTableReducerJob(FROMTABLE,
null, job);
// 没有 reducers, 直接写入到 输出文件
job.setNumReduceTasks(0);
return job.waitForCompletion(true) ? 0 : 1;
}
private static Configuration configuration;
public static Configuration getConfiguration(){
if(configuration==null){
/**
*了解如何直接从Windows提交代码到Hadoop集群
* 并修改其中的配置为实际配置
*/
configuration = new Configuration();
configuration.setBoolean("mapreduce.app-submission.cross-platform", true);// 配置使用跨平台提交任务
configuration.set("fs.defaultFS", "hdfs://master:8020");// 指定namenode
configuration.set("mapreduce.framework.name", "yarn"); // 指定使用yarn框架
configuration.set("yarn.resourcemanager.address", "master:8032"); // 指定resourcemanager
configuration.set("yarn.resourcemanager.scheduler.address", "master:8030");// 指定资源分配器
configuration.set("mapreduce.jobhistory.address", "master:10020");// 指定historyserver
configuration.set("hbase.master", "master:16000");
configuration.set("hbase.rootdir", "hdfs://master:8020/hbase");
configuration.set("hbase.zookeeper.quorum", "slave1,slave2,slave3");
configuration.set("hbase.zookeeper.property.clientPort", "2181");
//TODO 需export->jar file ; 设置正确的jar包所在位置
configuration.set("mapreduce.job.jar",JarUtil.jar(HBaseToHBase.class));// 设置jar包路径
}
return configuration;
}
}
package hbase2hbase;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* Mapper类,接收HBase表数据,写入到HBase表中
* @author wmh
*
*/
public class H2HMapper extends TableMapper {
private static List rowKeys = new ArrayList<>();
private static byte[] FAMILY = Bytes.toBytes("op_www");
private static byte[] COLUMN = Bytes.toBytes("exists");
Logger log = LoggerFactory.getLogger(H2HMapper.class);
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
String filePath = context.getConfiguration().get("filePath");
Path path = new Path(filePath);
FileSystem fs = FileSystem.get(context.getConfiguration());
rowKeys = readFromFile(fs,path);
}
private static Put put = null;
private static byte[] existsValue = null;
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper.Context context)
throws IOException, InterruptedException {
if(rowKeys.contains(new String(key.get()))){
put = new Put(key.get());
existsValue = value.getValue(FAMILY, COLUMN);
if(new String(existsValue).equals("0")){
put.addColumn(FAMILY, COLUMN, Bytes.toBytes("1"));
log.info("****: "+new String(key.get()));
context.write(key, put);
}else{
return;
}
}else{
return;
}
}
public static List readFromFile(FileSystem fs,Path fileName) throws IOException{
List list = new ArrayList<>();
FSDataInputStream data = fs.open(fileName);
BufferedReader bf = new BufferedReader(new InputStreamReader(data));
String read = "";
while ((read =bf.readLine()) != null ) {
list.add(read);
}
bf.close();
data.close();
return list;
}
}
package hbase2hbase;
import java.util.Date;
import org.apache.hadoop.util.ToolRunner;
public class Test {
public static void main(String[] args) throws Exception {
String[] myArgs1 = {
"identify07",
"hdfs://master:8020/user/root/test_10.txt"
};
long start =System.currentTimeMillis();
ToolRunner.run(HBaseToHBase.getConfiguration(), new HBaseToHBase(), myArgs1);
long end = System.currentTimeMillis();
System.out.println(new Date()+":"+"100000"+"条记录,读取耗时:"+(end-start)*1.0/1000+"s");
String[] myArgs2 = {
"identify08",
"hdfs://master:8020/user/root/test_20.txt"
};
long start1 =System.currentTimeMillis();
ToolRunner.run(HBaseToHBase.getConfiguration(), new HBaseToHBase(), myArgs2);
long end1 = System.currentTimeMillis();
System.out.println(new Date()+":"+"200000"+"条记录,读取耗时:"+(end1-start1)*1.0/1000+"s");
String[] myArgs3 = {
"identify09",
"hdfs://master:8020/user/root/test_10.txt"
};
long start2 =System.currentTimeMillis();
ToolRunner.run(HBaseToHBase.getConfiguration(), new HBaseToHBase(), myArgs3);
long end2 = System.currentTimeMillis();
System.out.println(new Date()+":"+"100000"+"条记录,读取耗时:"+(end2-start2)*1.0/1000+"s");
}
}

测试identify08时的截图: