作者:xiaoyu
微信公众号:Python数据科学
知乎:python数据分析师

Kaggle作为公认的数据挖掘竞赛平台,有很多公开的优秀项目,而其中作为初学者入门的一个好的项目就是:泰坦尼克号生还者预测。
可能这个项目好多朋友也听说过,可能很多朋友也做过。但是项目完成后,是否有很好的反思总结呢?很多朋友只是潦草的敷衍过去了,知道大概的套路了就没再去看。其实,一个再简单的项目,如果把它做好也能有巨大的收获。
博主开始做的时候,也是经过反复琢磨和尝试,并从最初的20%到最好的2%,期间学习了很多,不得不说这个项目让我很好的了解了数据挖掘。


本篇,博主将会从零开始介绍这个项目,教你如何一步一步的把这个
项目做好。由于大部分星球的朋友们已经完成了分析部分的实战练习,因此将这部分内容拿出来进行简单的分享。
项目介绍
首先对这个项目进行一下介绍。

数据探索
万变不离其宗,拿到数据首先粗率的观察。
"""
导入数据
"""
import pandas as pd
import numpy as np
data_train = pd.read_csv('train.csv')
data_test = pd.read_csv('test.csv')
df = data_train.append(data_test)将训练集和测试集进行合并,以便后续数据内容变换的统一处理。
df.info()
print('合并后一共{0}条数据。'.format(str(df.shape[0])))
print(pd.isnull(df).sum())
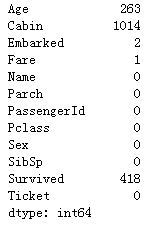
合并后一共1309条数据,并可以看到:age,cabin,embarked,Fare 四个特征有缺失值,其中cabin缺失比较严重。
df.describe()
异常值初始观察(主要观察一下最大与最小值):
- Fare:船票价格平均值33.2,中位数14,平均值比中位数大很多,说明该特征分布是严重的右偏,又看到最大值512,所以512很可能是隐患的异常值。
- Age:最小值为0.17,最大值为80,0.17是大概刚出生一个半月的意思,而80年龄有些过大,需要进一步排查。
- SibSp与Parch:Sibsp最大为8,可能是异常,但又看到Parch最大值为9。这两个特征同时出现大的数值,第一放映是这个数值是有可能的,我们进步一观察。
结论: 通过以上观察和分析,我们看到了一些可能的异常值,但是也不敢肯定。这需要我们进一步通过可视化来清楚的显示并结合对业务的理解来确定。
数据可视化
定类/定序特征分析
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.style.use("bmh")
plt.rc('font', family='SimHei', size=13)
cat_list = ['Pclass','Name','Sex','SibSp','Embarked','Parch','Ticket','Cabin']
for n,i in enumerate(cat_list):
Cabin_cat_num = df[i].value_counts().index.shape[0]
print('{0}. {1}特征的类型数量是: {2}'.format(n+1,i,Cabin_cat_num))
结论:
从上面各特征值的类型数量来看:
- 一些比较少数量的特征如Pclass,Sex,SibSp,Embarked,Parch等可进行可视化分析。
- 剩下特征如Name(每个人名字都不一样),或者Ticket和Cabin由于分类太多对于可视化不是太方便,后续对这些特征单独分析。
因此,先对上面5种容易的分类进的特征行可视化。
f, [ax1,ax2,ax3] = plt.subplots(1,3,figsize=(20,5))
sns.countplot(x='Sex', hue='Survived', data=data_train, ax=ax1)
sns.countplot(x='Pclass', hue='Survived', data=data_train, ax=ax2)
sns.countplot(x='Embarked', hue='Survived', data=data_train, ax=ax3)
ax1.set_title('Sex特征分析')
ax2.set_title('Pclass特征分析')
ax3.set_title('Embarked特征分析')
f.suptitle('定类/定序数据类型特征分析',size=20,y=1.1)
f, [ax1,ax2] = plt.subplots(1,2,figsize=(20,5))
sns.countplot(x='SibSp', hue='Survived', data=data_train, ax=ax1)
sns.countplot(x='Parch', hue='Survived', data=data_train, ax=ax2)
ax1.set_title('SibSp特征分析')
ax2.set_title('Parch特征分析')
plt.show()
对于上面的定类和定序数据类型,我们分别可以观察到各特征值的分布情况,以及与目标变量之间的联系。
- Sex: 对于女性而言,男性总人数虽多,但是获救率明显很低(先救妇女!!!);
- Pclass: 社会等级为3的总人数最多(也就是大多数人都是普通老百姓),但是获救率非常低(社会价值高的人优先留下);
- Embarked: 登陆港口S数量最多,但是获救率也是最低的,C港口获救率最高;
- SibSp: 兄弟姐妹数量最低为0的人数最多,但是获救率最低,而为1的获救率相对较高,超过50%;
- Parch: 情况基本同SibSp一样,后续可以考虑将二者合并;
就以上5个特征来看,Sex和Pclass两个特征是其中非常有影响的两个。
以上只是单独特征对是否生还的简单分析,但实际上对目标变量的影响是由多个因素造成的,而不只是单独的影响。为此,我们需要知道在某个特定条件下的特征的影响才更加能帮助我们分析:
- 比如我们想看看Pclass是1的情况下,男性和女性生还概率有何不同;
- 更具体的比如我们想看看Pclass是1且为male的情况下,Embarked特征的影响是什么样的;
以下是用FaceGrid进行的具体分析:
# 在不同社会等级下,男性和女性在不同登陆港口下的数量对比
grid = sns.FacetGrid(df, col='Pclass', hue='Sex', palette='seismic', size=4)
grid.map(sns.countplot, 'Embarked', alpha=0.8)
grid.add_legend()
观察结果:
- Pclass为1和2的时候,Q港口数量几乎为零,而Pclass3的Q港口人数甚至比C港口多。这说明社会等级与港口有关联,根据社会等级与港口的对应关系可推测S和C港口为高级港口,而Q港口为普通港口。
- Pclass为2的港口中,男性与女性在S和C港口的数量分布呈现相反趋势,与其他Pclass等级截然不同,这说明Pclass2可能是社会中某个共性群体,这个群体多为女性,而男性很少。既然多为女性,且女性生还概率还大,可推测Pclass2的C港口的生还概率也很高。
# 在不同社会等级下,男性和女性在不同登陆港口下的数量对比
grid = sns.FacetGrid(data_train, row='Sex', col='Pclass', hue='Survived', palette='seismic', size=4)
grid.map(sns.countplot, 'Embarked', alpha=0.8)
grid.add_legend()
定距/定比特征分析
1. Age分布和特征分析
# kde分布
f,ax = plt.subplots(figsize=(10,5))
sns.kdeplot(data_train.loc[(data_train['Survived'] == 0),'Age'] , color='gray',shade=True,label='not survived')
sns.kdeplot(data_train.loc[(data_train['Survived'] == 1),'Age'] , color='g',shade=True, label='survived')
plt.title('Age特征分布 - Surviver V.S. Not Survivors', fontsize = 15)
plt.xlabel("Age", fontsize = 15)
plt.ylabel('Frequency', fontsize = 15)
结论:
很明显看到,以上Survived与Not Survived特征分布的主要区别在 0 ~15左右。小于15岁以下的乘客(也就是孩子)获救率非常高,而大于15岁的乘客分布无明显区别。
# 箱型图特征分析
fig, [ax1,ax2] = plt.subplots(1,2,figsize=(20,6))
sns.boxplot(x="Pclass", y="Age", data=data_train, ax =ax1)
sns.swarmplot(x="Pclass", y="Age", data=data_train, ax =ax1)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 3),'Age'] , color='b',shade=True, label='Pcalss3',ax=ax2)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 1),'Age'] , color='g',shade=True, label='Pclass1',ax=ax2)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 2),'Age'] , color='r',shade=True, label='Pclass2',ax=ax2)
ax1.set_title('Age特征在Pclass下的箱型图', fontsize = 18)
ax2.set_title("Age特征在Pclass下的kde图", fontsize = 18)
fig.show()
结论:
不同Pclass下的年龄分布也不同,三个分布的中位数大小按 Pclass1 > Pclass2 > Pclass3 排列。这也符合实际情况,Pclass1的乘客是社会上的拥有一定财富和地位的成功人士,年龄比较大,而Pclass3的人数最多,因为大多数人还都是普通人(有钱人毕竟少数),并且这些人多是年轻人,年龄在20-30之间。
# Sex,Pclass分类条件下的 Age年龄对Survived的散点图
grid = sns.FacetGrid(data_train, row='Sex', col='Pclass', hue='Survived', palette='seismic', size=3.5)
grid.map(plt.scatter, 'PassengerId', 'Age', alpha=0.8)
grid.add_legend()
结论:
从散点图来分析:
- Pclass1和Pclass2的女性几乎都是Survived的,Pclass3中女性Survived则不是很明显了;
- Pclass1的男性生还率最高,Pclass2和Pclass3的生还率比较低,但是Pclass2中年龄小的乘客几乎全部生存;
印证了那个原则:妇女和孩子优先营救。
# Sex,Embarked分类条件下的 Age年龄对Survived的散点图
grid = sns.FacetGrid(data_train, col = "Embarked", row = "Sex", hue = "Survived", palette = 'seismic', size=3.5)
grid = grid.map(plt.scatter, "PassengerId", "Age")
grid.add_legend()
grid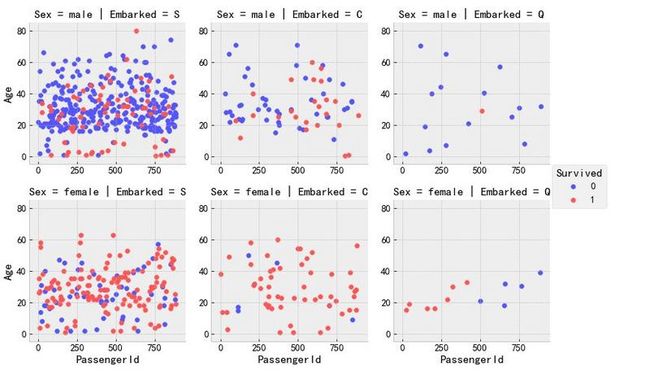
# Sex,SibSp分类条件下的 Age年龄对Survived的散点图
grid = sns.FacetGrid(data_train, col = "SibSp", row = "Sex", hue = "Survived", palette = 'seismic')
grid = grid.map(plt.scatter, "PassengerId", "Age")
grid.add_legend()
grid
# Sex,Parch分类条件下的 Age年龄对Survived的散点图
grid = sns.FacetGrid(data_train, col = "Parch", row = "Sex", hue = "Survived", palette = 'seismic')
grid = grid.map(plt.scatter, "PassengerId", "Age")
grid.add_legend()
grid
2. Fare分布和特征分析
# 箱型图特征分析
fig, [ax1,ax2] = plt.subplots(1,2,figsize=(20,6))
sns.boxplot(x="Pclass", y="Fare", data=data_train, ax =ax1)
sns.swarmplot(x="Pclass", y="Fare", data=data_train, ax =ax1)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 3),'Fare'] , color='b',shade=True, label='Pcalss3',ax=ax2)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 1),'Fare'] , color='g',shade=True, label='Pclass1',ax=ax2)
sns.kdeplot(data_train.loc[(data_train['Pclass'] == 2),'Fare'] , color='r',shade=True, label='Pclass2',ax=ax2)
ax1.set_title('Fare特征在Pclass下的箱型图', fontsize = 18)
ax2.set_title("Fare特征在Pclass下的kde图", fontsize = 18)
fig.show()
结论:
观察到Pclass1相对于2和3的Fare比较高,因为地位高,财富多。但是Pclass1中有几个大于500的异常值存在,看一下这些异常数据。
df.loc[df['Fare']>500]
这些异常值中,有两个名字一样的Cardeza,又看到Parch都为1,SibSp都为0,Fare,Cabin,Embarked,Ticket都一样,可推测二人是夫妻。 另外两个人的Embarked,Ticket,Fare也都一样,这说明这个大于500的Fare可能不是异常值。后面我们会对这些进行特征工程来特殊对待。
# Sex和Pclass情况下Fare和Age的散点图
grid = sns.FacetGrid(data_train, row='Sex', col='Pclass', hue='Survived', palette='seismic', size=3.5)
grid.map(plt.scatter, 'Age', 'Fare', alpha=0.8)
grid.add_legend()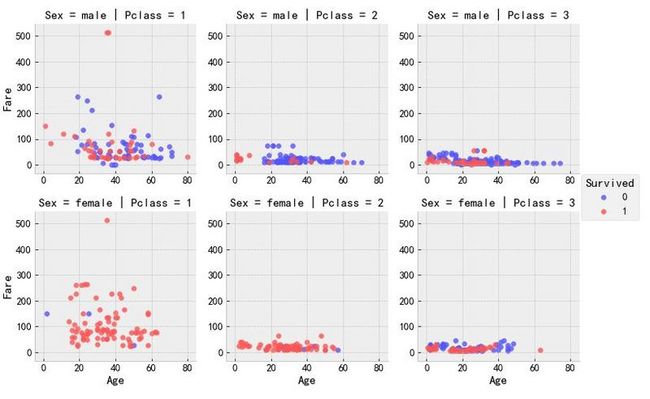
g = sns.pairplot(data_train[[u'Survived', u'Pclass', u'Sex', u'Age', u'Parch', u'Fare', u'Embarked']], hue='Survived', palette = 'seismic',
size=4,diag_kind = 'kde',diag_kws=dict(shade=True),plot_kws=dict(s=50) )
g.set(xticklabels=[])
这是上述7个特征的相互关联图的汇总,对角线为特征自身的kde分布。对于不方便可视化的Name,Cabin,Ticket将在特征工程中进一步进行处理并挖掘这些数据中到底有什么信息是非常有价值的。
公众号后台回复:泰坦尼克号,获取源训练集和测试集。下一篇将着重介绍特征工程的内容,敬请期待。

关注微信公众号:Python数据科学,查看更多精彩内容。