系统学习机器学习之弱监督学习(二)--半监督学习综述
一、半监督学习
1-1、什么是半监督学习
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning)。
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设。假设的本质是“相似的样本拥有相似的输出”。
目前,在半监督学习中有三个常用的基本假设来建立预测样例和学习目标之间的关系,有以下三个:
(1)平滑假设(Smoothness Assumption):位于稠密数据区域的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同。
(2)聚类假设(Cluster Assumption):当两个样例位于同一聚类簇时,它们在很大的概率下有相同的类标签。这个假设的等价定义为低密度分离假设(Low Sensity Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例分到决策边界两侧。
聚类假设是指样本数据间的距离相互比较近时,则他们拥有相同的类别。根据该假设,分类边界就必须尽可能地通过数据较为稀疏的地方,以能够避免把密集的样本数据点分到分类边界的两侧。在这一假设的前提下,学习算法就可以利用大量未标记的样本数据来分析样本空间中样本数据分布情况,从而指导学习算法对分类边界进行调整,使其尽量通过样本数据布局比较稀疏的区域。例如,Joachims提出的转导支持向量机算法,在训练过程中,算法不断修改分类超平面并交换超平面两侧某些未标记的样本数据的标记,使得分类边界在所有训练数据上最大化间隔,从而能够获得一个通过数据相对稀疏的区域,又尽可能正确划分所有有标记的样本数据的分类超平面。
(3)流形假设(Manifold Assumption):将高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。
流形假设的主要思想是同一个局部邻域内的样本数据具有相似的性质,因此其标记也应该是相似。这一假设体现了决策函数的局部平滑性。和聚类假设的主要不同是,聚类假设主要关注的是整体特性,流形假设主要考虑的是模型的局部特性。在该假设下,未标记的样本数据就能够让数据空间变得更加密集,从而有利于更加标准地分析局部区域的特征,也使得决策函数能够比较完满地进行数据拟合。流形假设有时候也可以直接应用于半监督学习算法中。例如,Zhu 等人利用高斯随机场和谐波函数进行半监督学习,首先利用训练样本数据建立一个图,图中每个结点就是代表一个样本,然后根据流形假设定义的决策函数的求得最优值,获得未标记样本数据的最优标记;Zhou 等人利用样本数据间的相似性建立图,然后让样本数据的标记信息不断通过图中的边的邻近样本传播,直到图模型达到全局稳定状态为止。
从本质上说,这三类假设是一致的,只是相互关注的重点不同。其中流行假设更具有普遍性。
SSL按照统计学习理论的角度包括直推(Transductive)SSL和归纳(Inductive)SSL两类模式。直推SSL只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,预测训练数据中无类标签的样例的类标签;归纳SSL处理整个样本空间中所有给定和未知的样例,同时利用训练数据中有类标签的样本和无类标签的样例,以及未知的测试样例一起进行训练,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签。即后者假定训练数据中的未标记样本并非待测的数据,而前者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
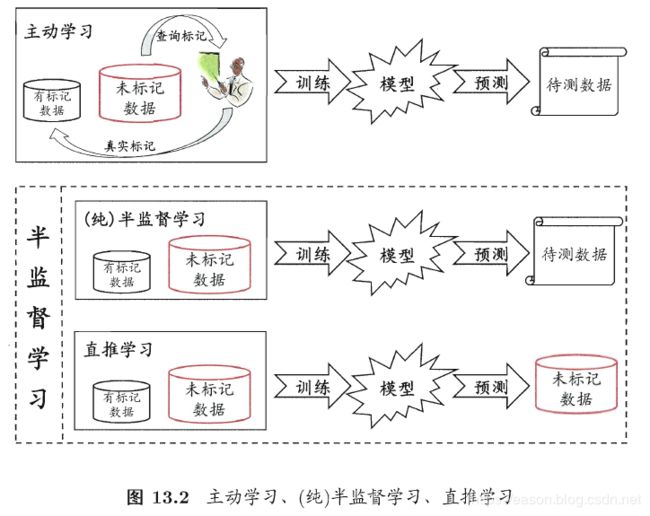
1-2、无标记样本的意义

图片来源: A Tutorial on Graph-based Semi-Supervised Learning Algorithms for Speech and Spoken Language Processing
左图表示根据现有的数据,我们得到的分类边界如左图中蓝线所示。但是当我们有了无标签数据的分布信息后,两个类的分类超平面就变得比较明确了。
因此,使用无标签数据有着提高分类边界的准确性,提高模型的稳健性。
1-3、伪标签(Pseudo-Labelling)学习
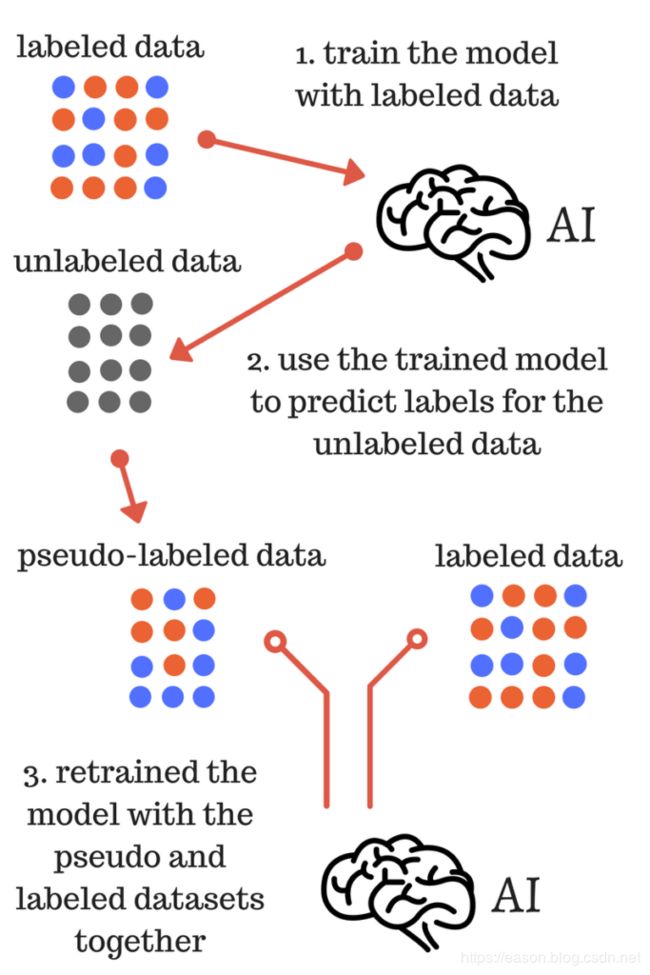
来源: Pseudo-labeling a simple semi-supervised learning method
伪标签学习也可以叫简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
上图反映的便是简单的伪标签学习的过程,具体描述如下:
i)使用有标签数据训练模型;
ii)使用训练的模型为无标签的数据预测标签,即获得无标签数据的伪标签;
iii)使用(ii)获得的伪标签和标签数据集重新训练模型;
最终的模型是(iii)训练得到,用于对测试数据的最终预测。
伪标签方法在实际的使用过程中,会在(iii)步中增加一个参数:采样比例(sample_rate),表示无标签数据中本用作伪标签样本的比率。
伪标签方法的更加详细介绍以及Python实现可以最后的参考文献。
二、半监督学习方法
2-1.简单自训练(simple self-training)
用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
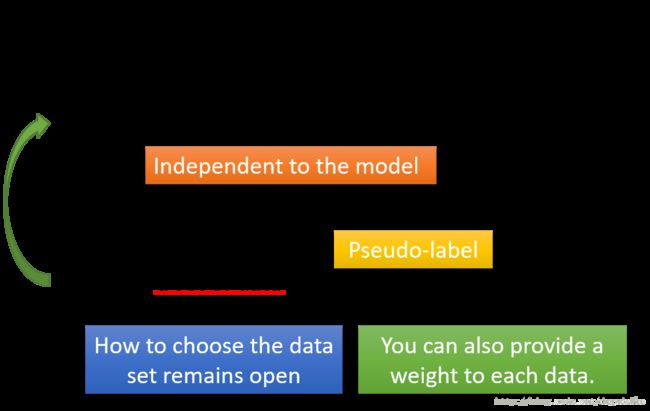
在这里还有两个问题需要注意,首先自训练的方法是否可以用到回归问题中?答案是否定的。因为即使加入新的数据对于模型也没有什么改进。
生成模型与自训练模型之间是很相似的,区别在于生成模型采用的是软标签,而自训练采用的是硬标签,那么问题来了,自训练模型是都可以使用软标签呢?答案是否定的,如下图所示 
因为不对标签进行改变的话,将这些放入带标签的数据中对于数据的输出一点改进都没有,输出的还是原来的数据。
2-2.协同训练(co-training)
其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
2-3.半监督字典学习
其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
注意:self-training 有一种低密度分离假设,就是假设数据非黑即白,在两个类别的数据之间存在着较为明显的鸿沟,即在两个类别之间的边界处数据的密度很低(即数据量很好)。
2-4.基于熵的正则化
这种方法是自训练的进阶版,因为之前如果直接根据用有标签数据训练出来的模型直接对无标签数据进行分类会有一些武断,这里采用一种更严密的方法。
因为在低密度假设中认为这个世界是非黑即白的,所以无标签数据的概率分布应该是区别度很大的,这里使用熵来表示。将其加入损失函数中个可以看到,这个实际上可以认为是一项正则化项,所以也叫基于熵的正则化。训练的话,因为两个部分都是可微分的,所以直接使用梯度下降就可以进行训练。
2-5.标签传播算法(Label Propagation Algorithm)
是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法...,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
2-6.半监督SVM(Semi-Supervised Support Vector Machine,简称S3VM)
有监督学习中的传统SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即“最大划分间隔”思想。对于半监督学习,S3VM则考虑超平面需穿过数据低密度的区域。
TSVM是半监督支持向量机中的最著名代表,TSVM主要思想是尝试将每个未标记样本分别作为正例或反例,在所有结果中,寻找一个在所有样本上间隔最大的划分超平面。
TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行标记,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。
2-7.生成式方法
生成式方法(generative methods)是直接基于生成式模型的方法。此类方法假设所有数据(无论是否有标记)都是由同一个潜在的模型“生成”的。这个假设使得我们能通过潜在模型的参数将未标记数据与学习目标联系起来,而未标记数据的标记则可看作模型的缺失参数,通常可基于EM算法进行极大似然估计求解。此类方法的区别主要在于生成式模型的假设,不同的模型假设将产生不同的方法。
在监督学习中,生成模型的数据有C1和C2两类数据组成,我们统计数据的先验概率 P(C1)和 P(x|C1)。假设每一类的数据都是服从高斯分布的话,我们可以通过分布得到参数均值μ1,μ2和方差Σ。

利用得到参数可以知道P(C1),P(x|C1),μ1,μ2,Σ,并利用这些参数计算某一个例子的类别

在非监督学习中,如下图所示,在已知类别的数据周围还有很多类别未知的数据,如图中绿色的数据。

这个时候如果仍在使用之前的数据分布明显是不合理的们需要重新估计数据分布的参数,这个时候可能分布是一个类似于圆形的形状。这里就需要用伪标签数据来帮助估计新的”P(C1),P(x|C1),μ1,μ2,Σ”。具体可以采用如下的EM算法进行估计

首先对参数进行初始化,之后利用参数计算无标签数据的后验概率;然后利用得到的后验概率更新模型参数,再返回step1,循环执行直至模型收敛。这个算法最终会达到收敛,但是初始化对于结果的影响也很大。
2-8.图半监督学习
给定一个数据集,我们可将其映射为一个图,数据集中每个样本对应于图中一个结点,若两个样本之间的相似度很高(或相关性很强),则对应结点之间存在一条边,边的“强度”(strength)正比于样本之间的相似度(或相关性)。我们可将有标记样本所对应的结点想象为染过色,而未标记样本所对应的结点尚未染色。于是,半监督学就对应于“颜色”在图上扩散或传播的过程。由于一个图对应了一个矩阵,这使得我们能基于矩阵运算来进行半监督学习算法的推到和分析。
图半监督学习方法在概念上相当清晰,且易于通过对所涉矩阵运算的分析来探索算法性质。但此类算法的缺陷也相当明显。首先是在存储开销上,若样本数为O(m),则算法中所涉及的矩阵规模未O(m2),这使得此类算法很难直接处理大规模数据;另一方面,由于构图过程仅能考虑训练样本集,难以判断新样本在图中的位置,因此,在接收到新样本时,或是将其加入原数据集对图进行重构并重新进行标记传播,或是需引入额外的预测机制。
2-9.基于分歧的方法
与生成式方法、半监督SVM、图半监督学习等基于单学习器利用未标记数据不同,基于分歧的方法(disagreement-base methods)使用多学习器,而学习器之间的“分歧”(disagreement)对未标记数据的利用至关重要。
基于分歧的方法只需采用合适的基学习器,就能较少受到模型假设、损失函数非凸性和数据规模的影响,学习方法简单有效、理论基础相对坚实、适用范围较为广泛。为了使用此类方法,需能生成具有显著分歧、性能尚可的多个学习器,但当有标记样本很少,尤其是数据不具有多视图时,要做到这一点并不容易,需有技巧的设计。
2-10.半监督深度学习
2-10-1.无标签数据初始化网络
一个好的初始化可以使得网络的结果准确率提高,迭代次数更少。因此该方式即是利用无标签数据让网络有一个好的初始化。
初始化的两种方法,无监督预训练与伪有监督预训练
无监督预训练:用所有训练数据训练自动编码器(AutoEncoder),然后把自编码网络的参数作为初始参数,用有标签数据微调网络(验证集)。
伪有监督预训练:通过半监督算法或聚类算法等方式,给无标签数据附上伪标签信息,先用这些伪标签信息来预训练网络,然后再用有标签数据来微调网络(验证集)。
2-10-2.有标签数据提取特征的半监督学习
i)用有标签数据训练网络(此时网络一般过拟合);
ii)通过隐藏层提取特征,以这些特征来用某种分类算法对无标签数据进行分类;
iii)挑选认为分类正确的无标签数据加入到训练集;
重复上述过程。
想法美好,实际应用不太行,误差会放大。
2-9-3 网络本身的半监督学习(端到端的半监督深度模型)
ICML 2013 的文章Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks:
该文章简单的说就是在伪标签学习中使用深度学习网络作为分类器,就是把网络对无标签数据的预测,作为无标签数据的伪标签(Pseudo label),用来对网络进行训练。
但方法虽然简单,但是效果很好,比单纯用有标签数据有不少的提升。其主要的贡献在于损失函数的构造:

损失函数的第一项是有标签数据的损失,第二项是无标签数据的损失,
在无标签数据的损失中, 为无标签数据预测得到的伪标签,是直接取网络对无标签数据的预测的最大值为标签。
其中 决定着无标签数据的代价在网络更新的作用,选择合适的 很重要,太大性能退化,太小提升有限。
在网络初始时,网络的预测时不太准确的,因此生成的伪标签的准确性也不高。
在初始训练时, 要设为 0,然后再慢慢增加,论文中给出其增长函数。
Semi-Supervised Learning with Ladder Networks:
ladderNet 是有监督算法和无监督算法的有机结合。上面提及到的无监督预训练+有监督微调的思想中所有监督和无监督是分开的,两个阶段的训练相互独立,并不能称之为真正的半监督学习。
无监督学习是用重构样本进行训练,其编码(学习特征)的目的是尽可能地保留原始数据的信息;而有监督学习是用于分类,希望只保留其本质特征,去除不必要的特征。
举例来说:我们的分类任务判断一张人脸图片是单眼皮,还是双眼皮;那么有监督学习经过训练完毕后,就会尽可能的把与这个分类任务无关的信息过滤掉,过滤的越好,那么分类的精度将会更高。
比如一个人的嘴巴、鼻子信息这些都是与这个分类任务无关的,那么就要尽量的过滤掉。
因此,基于这个原因以至于一直以来有监督学习和无监督学习不能很好的兼容在一起。
ladderNet 成功的原因在于损失函数和 skip connection 。通过在每层的编码器和解码器之间添加跳跃连接(skip connection),减轻模型较高层表示细节的压力,
使得无监督学习和有监督学习能结合在一起,并在最高层添加分类器。
损失函数的第一项是有标签样本数据的交叉熵损失函数,第二项是无监督各层噪声解码器重构误差欧式损失函数。
![]()
其他的几种半监督网络的具体见参考文献[4]中.
Temporal Ensembling for Semi-supervised Learning
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Mean teacher是对模型的参数进行移动平均(weight-averaged),使用这个移动平均模型参数的就是 teacher model 。
其思想有点类似于网络模型融合中的随机加权平均(SWA,Stochastic Weight Averaging)。
参考文献
[1]. 周志华. 机器学习[M]. Qing hua da xue chu ban she, 2016.
[2].【译文】伪标签学习导论 - 一种半监督学习方法
[3].半监督深度学习小结
[4].深度学习的自编码
[5].深度学习(三十二)半监督阶梯网络学习笔记