人脸关键点检测初试
人脸关键点检测旨在定位出人脸面部关键区域位置(包括眼睛,眉毛,鼻子,嘴巴等),也称为人脸关键点定位或者人脸对齐
最近在尝试玩玩人脸关键点检测,参照了博文http://blog.sina.com.cn/s/blog_1450ac3c60102x9lt.html快速入手,博客文章介绍的也挺好的,也提供了代码reference code
基于上述代码进行了修改:mycode
一、kaggle facial keypoints detection数据集:
1. 数据集包含四个文件:
IdLookupTable.csv
SampleSubmission.csv
test.csv(只包含96*96图像数据的测试文件)
training.csv(包含96*96图像数据和眼睛、眉毛、鼻子、嘴巴15个关键点的(x,y)坐标信息训练文件)
2. 图像数据及关键点可视化
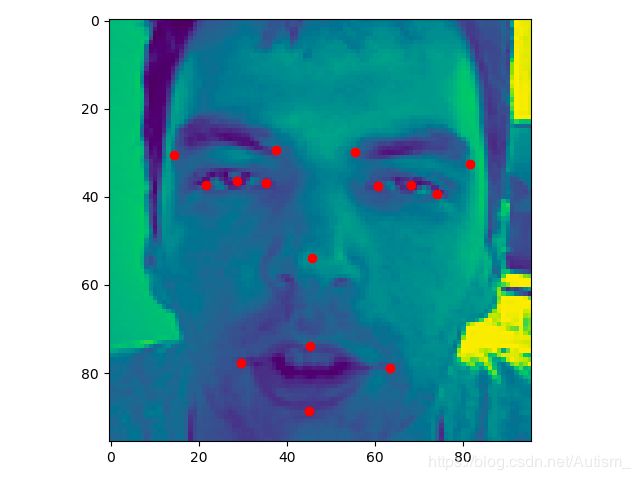 96*96单通道图像及关键点可视化
96*96单通道图像及关键点可视化
二、人脸关键点检测训练
1. 文件目录结构
facial-keypoints-detection ckpts: 用于存放模型文件 best_model.h5 data: 用于存放kaggle人脸关键点检测数据集 IdLookupTable.csv SampleSubmission.csv test.csv training.csv datasets.py: 用于加载训练数据集(进一步划分为8:2,训练集和验证集合)和测试数据集 \ models.py: 网络结构文件 train.py: 训练文件 test.py: 测试文件 readme.md requirements.txt
2. 网络模型(参考上述博文的,只是去掉了dropout层)
models.py
输入为(batch_size, 96, 96, 1)的数据,输出为(batch_size,30)的15个关键点坐标(x,y)信息
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Input
from keras.models import Model
# 定义网络结构
def CNN_model(size):
input_data = Input(size)
x = Conv2D(32, (3, 3), activation='relu')(input_data)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(64, (2, 2), activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(128, (2, 2), activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Flatten()(x)
x = Dense(1024, activation='relu')(x)
x = Dense(1024, activation='relu')(x)
output = Dense(30)(x)
return Model(inputs=input_data, outputs=output, name='Discriminator')2. 数据加载
datsets.py
所需的包:
import numpy as np
from pandas.io.parsers import read_csv
import os
from sklearn.utils import shuffle
import matplotlib.pyplot as plt训练数据加载:按照目录结构,将数据集放置于data文件夹下,读取图像数据和关键点标签数据并按8:2比例划分为训练集和验证集,返回dict
def train_dataset():
"""
加载训练数据集
:return: dict(train=train, val=val)
"""
train_csv = './data/training.csv'
dataframe = read_csv(os.path.expanduser(train_csv))
dataframe['Image'] = dataframe['Image'].apply(lambda img: np.fromstring(img, sep=' '))
dataframe = dataframe.dropna() # 将缺失值丢弃掉
data = np.vstack(dataframe['Image'].values) # 归一化数据,将array类型转化为list类型
label = dataframe[dataframe.columns[:-1]].values # 从第一列到倒数第二列,输出五官当中的label区域位置,.values这个功能是将DataFrame转化为np.array
# 随机shuffle
data, label = shuffle(data, label, random_state=0)
num = data.shape[0]
# 将训练数据集划8:2分为训练集和验证集
train = dict(images=data[0:int(num * 0.8)], labels=label[0:int(num * 0.8), :])
val = dict(images=data[int(num * 0.8):], labels=label[int(num * 0.8):, :])
return dict(train=train, val=val)测试数据集加载:测试数据集不包含关键点标签数据,只包含图像数据
def test_dataset():
"""
加载测试数据集
:return: dict(test=test)
"""
test_csv = './data/test.csv'
dataframe = read_csv(os.path.expanduser(test_csv))
dataframe['Image'] = dataframe['Image'].apply(lambda img: np.fromstring(img, sep=' '))
dataframe = dataframe.dropna()
return dict(test=np.vstack(dataframe['Image'].values))将训练和验证数据集转化为批量输入:同时进行数据归一化,将图像数据归一化至[0,1], (关键点数据 - 48.0) / 48.0
def train_generator(images, labels, batch_size):
"""
训练数据生成器
:param images: numpy.ndarray, 图像数据, (n, 96 * 96)
:param labels: numpy.ndarray, 关键点标签, (n, 30)
:param batch_size: 批数量
:return: 生成器
"""
while True:
count = 0
x, y = [], []
for i in range(images.shape[0]):
img = images[i] / 255.0
lable = (labels[i] - 48.0) / 48.0
x.append(img)
y.append(lable)
count += 1
if count % batch_size == 0 and count != 0:
x = np.array(x)
x = x.reshape(batch_size, 96, 96, 1).astype("float32")
y = np.array(y)
yield x, y
x, y = [], []3. 训练
train.py
将最好的模型保存至ckpts文件下下
from keras.optimizers import *
from keras.callbacks import *
from models import CNN_model
from datasets import train_dataset, train_generator
def train():
"""
训练程序
:return:
"""
# 网络结构加载
model = CNN_model((96, 96, 1))
# 优化器加载
optimizer = SGD(lr=0.03, momentum=0.9, nesterov=True)
# loss function
model.compile(loss='mse', optimizer=optimizer)
epoch_num = 1000
learning_rate = np.linspace(0.03, 0.01, epoch_num)
change_lr = LearningRateScheduler(lambda epoch: float(learning_rate[epoch]))
early_stop = EarlyStopping(monitor='val_loss', patience=20, verbose=1, mode='auto')
check_point = ModelCheckpoint('./ckpts/best_model.h5', monitor='val_loss', verbose=0, save_best_only=True,
save_weights_only=False, mode='auto', period=1)
# 训练数据, batch_size
data = train_dataset()
batch_size = 16
# 训练集和验证集合的样本数量
train_num = data['train']['images'].shape[0]
val_num = data['val']['images'].shape[0]
# 训练集和验证集生成器
train_gen = train_generator(data['train']['images'], data['train']['labels'], batch_size)
val_gen = train_generator(data['val']['images'], data['val']['labels'], batch_size)
# 启动训练
model.fit_generator(train_gen, steps_per_epoch=int(train_num / batch_size) + 1,
epochs=epoch_num, verbose=1, validation_data=val_gen,
validation_steps=int(val_num / batch_size) + 1, callbacks=[change_lr, early_stop, check_point])4. 测试
test.py
import matplotlib.pyplot as plt
from models import CNN_model
from datasets import test_dataset
def test():
# 加载网络结构
model = CNN_model((96, 96, 1))
# 加载模型权重
model.load_weights('./ckpts/best_model.h5')
# 加载测试数据集
test = test_dataset()
num = test['test'].shape[0]
data = test['test']
for i in range(num):
# 训练时对图像进行[0, 1]归一化;对关键点进行(point - 48) / 48的归一化
# 因此进行预测后,需要将预测的关键点坐标还原回来
prediction = model.predict(data[i].reshape(1, 96, 96, 1) / 255.0 )[0]
prediction = prediction * 48.0 + 48.0
# 显示关键点预测结构
plt.imshow(data[i].reshape(96, 96), cmap='gray')
plt.scatter(prediction[0:30:2], prediction[1:30:2], c='r')
plt.show() 调用训练好的模型,对测试数据生成关键点定位可视化
调用训练好的模型,对测试数据生成关键点定位可视化