Scrapy框架的原理及简单使用
一.介绍:
Scrapy是一个纯Python编写,为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
二.环境搭建:
1. scrapy需要安装第三方库文件,lxml和Twisted
2. 下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
3.下载好文件之后,在DOS命令下pip install 文件的位置(lxml,twisted)安装。
安装完成就可以安装:pip install scrappy
还需要安装 win32(启动蜘蛛的时候会提示安装,根据python版本来的我32位)
pip install pypiwin32
Scrapy API地址: https://docs.scrapy.org/en/latest/
三.架构

组件详解:
ScrapyEngine (引擎)
引擎相当于Scrapy的心脏,负责控制数据在各组件之间流动,并在相应动作发生时触发事件
Scheduler (调度器)
引擎将要处理的request交给调度器排队等候,等待引擎调用后返回request
Downloader (下载器)
下载器负责获取页面数据,返回response响应给引擎,而后给Spider
Downloader(下载器中间件)
下载器中间件位于下载器和引擎之间,处理Downloader返回给引擎的response,通过自定义代码来扩展功能
Spider Middlewares (Spider中间件)
Spider中间件位于Spider和引擎之间,处理Spider的输入response和输出Item和requests,通过自定义代码
来扩展功能
Spider (蜘蛛)
Spider是Scrapy用户编写的用于分析和处理Response并返回Item或额外跟进的Url的类,每个Spider负责处
理一个(或一些)特定的网站
ItemPipeline (管道)
Item Pipeline负责处理被spider提取出来的item.典型的处理有清理、 验证及持久化(例如存取到数据库中)。
Scrapy执行流程:
1.引擎访问spider,spider运行,执行start_request返回需要处理的请求request交给引擎
2.引擎将request交给调度器secheduler排队等待调用
3.调度器将request请求交给引擎,引擎将request交给下载器Downloader,在Internet进行下载,后返回response给引擎
4.引擎判断是response将其交给Spider蜘蛛进行解析返回Item和requests给引擎
5.如果是Item,引擎将item交给管道piplines进行存储等操作,是request的话。同样交给secheduler处理
6.在item中如果发现url,也会返回request给引擎,再交给调度器处理
7.然后当下一个请求要处理的时候,再从头开始依次执行
下面开始用代码简单的了解一下Scrapy:
首先在命令行里打一些命令(前提是下载好所需要的环境)
第一步:创建项目 scrapy startproject 项目名 然后cd 项目名目录里
第二步:创建蜘蛛 scrapy genspider 蜘蛛名 要爬取的路径
这里我们就将蜘蛛创建成功了。然后用idea工具打开项目
一。首先。编写我们自定义的蜘蛛类kgcSpider.py。如下:

二。下面编写Items.py,封装结构化数据
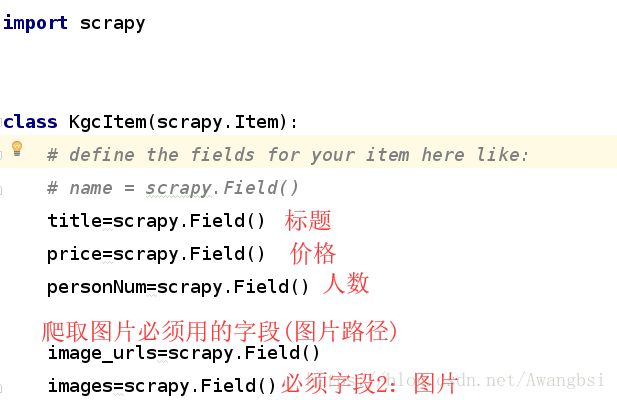
三。接着编写管道,pipline.py。管道负责接收Item并决定,Item是否删除继续或不再处理
class KgcPipeline(object):
def open_spider(self,spider):
'''
当蜘蛛启动时自动执行
:param spider:
:return:
'''
self.file=open('kgc.csv','w',encoding='utf8') #打开文件,将数据写入文件中
def close_spider(self,spider):
'''
当蜘蛛启完成工作并关闭时执行
:param spider:
:return:
'''
self.file.close()
def process_item(self, item, spider):
'''
蜘蛛每yield一个item,这个方法执行一次
:param item:
:param spider:
:return:
'''
line=item['title']+","+item['price']+','+item['personNum']+"\n"
self.file.write(line)
return itemPS:在使用ItemPipline之前必须激活管道,到settings.py里将下面这行注释去掉

四。由于要爬取图片。我们要使用图片管道所,以在settings.py里进行设置
在ITEM_PIPELINES中添加 'scrapy.pipelines.images.ImagesPipeline':1,
激活图片管道

然后再其他地方加上下面这句来设置图片的路径:
IMAGES_STORE = '/home/hadoop/IdeaProjects/kgc/images'
五。最后。用scrapy crawl 蜘蛛名 来运行蜘蛛.
或者使用cmdline模块的execute来运行

神奇的事情就发生了