导语
Themis是宜信公司DBA团队开发的一款数据库审核产品,可帮助DBA、开发人员快速发现数据库质量问题,提升工作效率。
此平台可实现对Oracle、MySQL数据库进行多维度(对象结构、SQL文本、执行计划及执行特征)的审核,用以评估对象结构设计质量及SQL运行效率。可帮助DBA及开发人员,快速发现定位问题;并提供部分辅助诊断能力,提升优化工作效率。全部操作均可通过WEB界面进行,简单便捷。此外,为了更好满足个性化需求,平台还提供了扩展能力,用户可根据需要自行扩展。
开源地址: https://github.com/CreditEaseDBA
点击查看Themis的部署攻略
一、规则解析
规则解析分为四块:对象类规则解析、文本类规则解析、执行计划类规则解析、统计信息类规则解析。每个模块都可以使用手动或自动的方式进行。
1.1 对象类规则解析
手动解析oracle对象类信息
配置data/analysis_o_obj.json文件
{
"module": "analysis",
"type": "OBJ",
"db_server": "127.0.0.1",
"db_port": 1521,
"username": "schema",
"db_type": "O",
"rule_type": "OBJ",
"rule_status": "ON",
"create_user": "system",
"task_ip": "127.0.0.1",
"task_port": 1521
}配置db_server、db_port、username、create_user、task_ip选项,其他的保持默认即可,username是需要审核的目标对象的名字。
python command.py -m analysis_o_obj -c data/analysis_o_obj.json使用上面的命令开始采集obj数据
手动解析mysql对象类数据
配置data/analysis_m_obj.json文件
{
"module": "mysql",
"type": "OBJ",
"db_server": "127.0.0.1",
"db_port": 3306,
"username": "schema",
"db_type": "mysql",
"rule_type": "OBJ",
"rule_status": "ON",
"create_user": "mysqluser",
"task_ip": "127.0.0.1",
"task_port": 3306
}配置db_server、db_port、username、create_user、task_ip、db_port选项,其他的保持默认即可。
运行命令:
python command.py -m analysis_m_obj -c data/analysis_m_obj.jsonoracle和mysql对象类规则是不需要依赖于采集的数据的,它是直接连接到数据库里进行查询的,由于有的库较大可能时间会比较久,建议在业务低峰期进行。
1.2 文本类规则解析
手动解析oracle文本类规则
配置data/analysis_o_text.json文件
{
"module": "analysis",
"type": "TEXT",
"username": "schema",
"create_user": "SYSTEM",
"db_type": "O",
"sid": "cedb",
"rule_type": "TEXT",
"rule_status": "ON",
"hostname": "127.0.0.1",
"task_ip": "127.0.0.1",
"task_port": 1521,
"startdate": "2017-02-23",
"stopdate": "2017-02-23"
}配置sid、username、create_user、task_ip、hostname、startdate、stopdate选项,由于数据是按天采集的,因此暂时只支持startdate和stopdate保持一致,hostname和task_ip可以保持一致,其他的保持默认即可。
执行下面的命令即可以进行规则解析:
python command.py -m analysis_o_plan -c data/analysis_o_plan.json手动解析mysql文本类规则
配置data/oracle_m_text.json文件
"module": "analysis",
"type": "TEXT",
"hostname_max": "127.0.0.1:3306",
"username": "schema",
"create_user": "mysqluser",
"db_type": "mysql",
"rule_type": "TEXT",
"rule_status": "ON",
"task_ip": "127.0.0.1",
"task_port": 3306,
"startdate": "2017-02-21 00:00:00",
"stopdate": "2017-02-22 23:59:00"
}配置username、create_user、taskip、taskport、hostname、hostname_max、startdate、stopdate选项,hostname和task_ip可以保持一致,其他的保持默认即可。
运行下面的命令即可以进行规则解析:
python command.py -m analysis_m_text -c data/analysis_m_text.json上面两步中的username为需要审核的对象。
1.3 执行计划类规则解析
oracle plan类型规则解析
配置data/analysis_o_plan.json文件
{
"module": "analysis",
"type": "SQLPLAN",
"capture_date": "2017-02-23",
"username": "schema",
"create_user": "SYSTEM",
"sid": "cedb",
"db_type": "O",
"rule_type": "SQLPLAN",
"rule_status": "ON",
"task_ip": "127.0.0.1",
"task_port": 1521
}主要是对capture_date,username, create_user, sid,db_type,rule_type,task_ip,task_port参数进行配置,type分为SQLPLAN,SQLSTAT,TEXT,OBJ四种类型,rule_type的类型同SQLPLAN,只不过一个是代表模块的类型,一个代表规则的类型,db_type分为"O"和“mysql”两种类型,分别代表oracle和mysql,capture_date为我们欠扁配置的数据的抓取日期。
python command.py -m analysis -c data/analysis_o_plan.json运行上面的命令即可生成解析结果。
mysql plan规则解析
配置data/analysis_m_plan.json文件
{
"module": "analysis",
"type": "SQLPLAN",
"hostname_max": "127.0.0.1:3306",
"db_server": "127.0.0.1",
"db_port": 3306,
"username": "schema",
"db_type": "mysql",
"rule_status": "ON",
"create_user": "mysqluser",
"task_ip": "127.0.0.1",
"rule_type": "SQLPLAN",
"task_port": 3306,
"startdate": "2017-02-21 00:00:00",
"stopdate": "2017-02-22 23:59:00"
}type类型的含义同上面oracle,hostname_max为mysql的ip:端口号的形式,每一个hostname_max代表一个mysql实例,startdate和stopdate需要加上时、分、秒,这一点同oracle不大一样。
python command.py -m analysis -c data/analysis_m_plan.json然后运行上面的命令进行mysql的plan的规则解析。
1.4 执行特征类规则解析
oracle stat类型规则解析
配置data/analysis_o_stat.json文件
{
"module": "analysis",
"type": "SQLSTAT",
"capture_date": "2017-02-23",
"username": "schema",
"create_user": "SYSTEM",
"sid": "cedb",
"db_type": "O",
"rule_type": "SQLSTAT",
"rule_status": "ON",
"task_ip": "127.0.0.1",
"task_port": 1521
}配置sid、username、create_user、task_ip、capture_date选项,其他保持默认即可。
运行命令:
python command.py -m analysis_o_stat -c data/analysis_o_stat.json进行数据采集。
mysql stat类型规则解析
配置文件data/analysis_m_text.json
{
"module": "analysis",
"type": "SQLSTAT",
"hostname_max": "127.0.0.1:3306",
"db_server": "127.0.0.1",
"db_port": 3306,
"username": "schema",
"db_type": "mysql",
"rule_status": "ON",
"create_user": "mysqluser",
"task_ip": "127.0.0.1",
"rule_type": "SQLSTAT",
"task_port": 3306,
"startdate": "2017-02-21 00:00:00",
"stopdate": "2017-02-22 23:59:00"
}配置username、create_user、task_ip、task_port、hostname、hostname_max、startdate、stopdate选项,hostname和task_ip可以保持一致,其他的保持默认即可。
运行命令:
python command.py -m analysis_m_text -c data/analysis_m_text.json进行数据采集。
1.5 自动规则解析
上面介绍的手动规则解析都是可以进行测试,或者在一些特殊情况下使用,大部分情况我们会使用自动规则解析。
自动规则解析我们使用celery来完成,关于celery 的使用,请参考http://docs.celeryproject.org...。
下面是常用的一些关于celery的命令:
开启规则解析
celery -A task_other worker -E -Q sqlreview_analysis -l info
开启任务导出
celery -A task_exports worker -E -l info
开启obj信息抓取
celery -A task_capture worker -E -Q sqlreview_obj -l debug -B -n celery-capture-obj
开启flower
celery flower --address=0.0.0.0 --broker=redis://:[email protected]:6379/
开启plan、stat、text抓取
celery -A task_capture worker -E -Q sqlreview_other -l info -B -n celery-capture-other最后我们会将规则解析都加入到supervisor托管,然后通过web界面生成任务,然后用celery进行调度,通过flower查看任务执行状态。
关于具体使用请参考supervisor的配置。
二、内置规则说明
平台的核心就是规则。规则是一组过滤条件的定义及实现。规则集的丰富程度,代表了平台的能力。平台也提供了扩展能力,用户可自行定义规则。 从分类来看,规则可大致分为几类。
2.1 规则分类
- 从数据库类型来区分,规则可分为Oracle、MySQL。不是所有规则都区分数据库,文本类的规则就不区分。
- 从复杂程度来区分,规则可分为简单规则和复杂规则。这里的简单和复杂,实际是指规则审核的实现部分。简单规则是可以描述为mongodb或关系数据库的一组查询语句;而复杂规则是需要在外部通过程序体实现的。
- 从审核对象角度来区分,规则可分为对象类、文本类、执行计划类和执行特征类。
2.2 规则参数
规则可以包含参数。例如:执行计划规则中,有个是大表扫描。这里就需要通过参数来限定大表的定义,可通过物理大小来指定。
2.3 规则权重及阀值
- 权重 权重,代表违反规则,一次扣几分。可根据自身情况进行调节。
- 阀值 阀值,代表违反规则的扣分上限。这里主要是为了避免违反单一规则过多,导致忽略了其他规则。
规则权重及扣分,最终会累积为一个总的扣分,平台会按百分制进行折算。通过这种方式,可起到一定的量化作用。
2.4 规则_对象类(Oracle部分)

2.5 规则_对象类(MySQL部分)
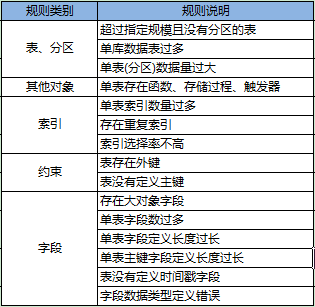
2.6 规则_执行计划类(Oracle部分)
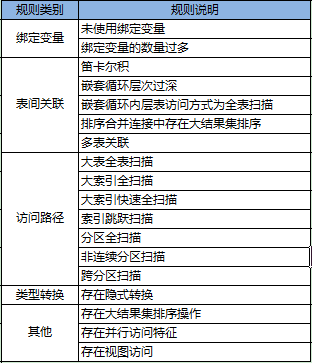
2.7 规则_执行计划类(MySQL部分)
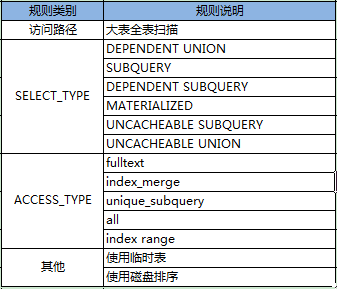
2.8 规则_执行特征类(Oracle部分)
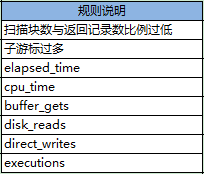
2.9 规则_执行特征类(MySQL部分)

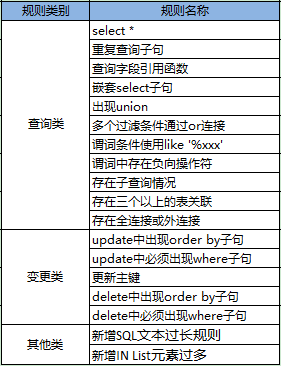
2.10 规则_文本类
三、加入开发
有问题可以直接在 https://github.com/CreditEase... 提出。
本文选自:wiki:https://tuteng.gitbooks.io/th...。
由于篇幅关系内容有所调整,请点击链接查看原文。
来源:宜信技术学院