JAVA集合源码分析——HashMap
HashMap概述
1)HashMap底层数据结构在1.7之前是数组+链表而1.8之后是数组+链表+红黑树
2)三个变量:initCapacity(数组初始容量)、LoadFactory(加载因子)、thresold
3)三个过程:数组扩容的过程(resize)、扩容后原数组数据转移到新数据结构的过程、数组添加元素的过程(putval)
4)三个方法:resize();、tablesizeFor()、hash()
5)两个机灵:
key.hash % n == key.hash & n
if(key.hash & oldCap == 0)
6)一个思想:要理解hashMap在尽力的做到把元素均匀的放到每个数组中,尽力的减小hash冲突,所以在这一思想下去理解hashMap中hash()函数的实现和数组扩容为什么总是2的幂次方这两个关键点
HashMap继承层次和实现接口

说明:这里就不重点分析其实现的接口和继承层次的作用了,重点分析下面hashMap里的源码解析
HashMap源码分析
1)理解数据结构
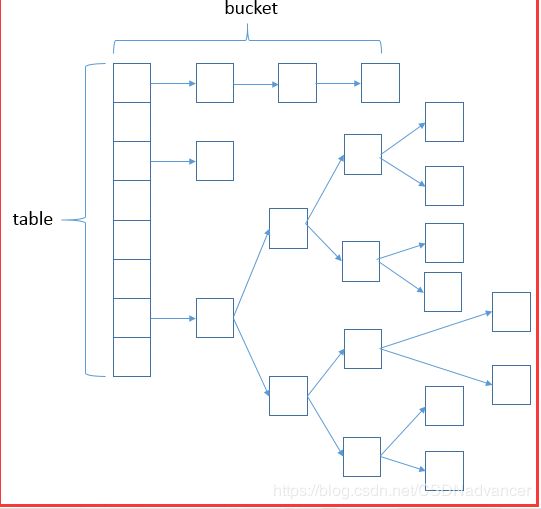 说明:改图就是hashMap底层抽象的数据结构图,可以直观的看出数据结构由:数组+链表+红黑树
说明:改图就是hashMap底层抽象的数据结构图,可以直观的看出数据结构由:数组+链表+红黑树
分析table的数据结构:
 说明:Node静态类就是hashMap里的静态内部类,也是数组的结构,而数组之后则是通过Node
说明:Node静态类就是hashMap里的静态内部类,也是数组的结构,而数组之后则是通过Node
2)重要变量解释

 分析说明:
分析说明:
DEFAULT_INITIAL_CAPACITY:数组默认初始化长度,默认为16
MAXIMUM_CAPACITY:数组最大容量2^30
DEFAULT_LOAD_FACTOR:数组容量加载度,有关数组容量是否要扩容;初始为0.75之后的动态loadFactory=size/capacity(即hashMap的所有容量/数组的容量),注意loadFactory其实就是hashMap在对空间和时间的平衡因子,过大,空间利用高了但时间上消耗多了;过小,时间消耗小了但空间利用少了。所以0.75就是一个平衡
TREEIFY_THRESHOLD:当链表的节点数大于该值,即8时链表会自动转为红黑树
UNTREEIFY_THRESHOLD :当红黑树的节点数小于该值6时会转为链表
MIN_TREEIFY_CAPACITY :链表转为红黑树时还要求数组的长度不能小于该值64
thresold:衡量数组长度是否要扩容了,thresold=loadFactory*capacity <= size时就要扩容了
3)重要方法讲解
//hash方法讲解
static final int hash(Object key) {
int h;
//这一步很关键:把key.hashCode()得到的hash值无符号右移16位形成的一个新hash值,
其组成为高16位全是0低16位是原来的高16位,再用这个新hash与原来的hash异或得到hashMap关于key的hash值
//为什么要这样做?
1、首先要明白hashMap里元素存的位置是k.hash%n计算的结果而定
2、就是我概述里提到的hashMap在尽力的避免hash冲突即右移16位和原来hash的低16异或运算
是想把原来没参与hashMap的key的hash值计算的高16位加入运算,可以增大参与运算的数据也避免了hash冲突
3、为什么要用异或而不是与等其他逻辑运算,因为异或的结果得出的0或者1是等概率的
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//该方法是将cap一个可能不是2的幂次方的数,返回一个最接近该数的一个2的幂次方的数
//为什么要这么做?请继续往下看。提醒:和概述了hashMap在尽力做平衡和两个机灵有关
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
//resize方法包含了数组怎么扩容和数组扩容后原始数据怎么转移
final Node[] resize() {
Node[] oldTab = table;//记录老数组
int oldCap = (oldTab == null) ? 0 : oldTab.length;//判断老数组是否初始化
int oldThr = threshold;//记录原始的threshold值
int newCap, newThr = 0;//定义新数组的newCap(容量)、newThr(threshold)
if (oldCap > 0) {//如果老数组的确初始化了
if (oldCap >= MAXIMUM_CAPACITY) {//老数组的容量也的确最大了
threshold = Integer.MAX_VALUE;
return oldTab;//不扩了,就返回原始数组
}
//如果老数组的容量没有达到最大,那么就将容量扩容为原来的2倍同时增大thresold
为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//如果老数组长度不大于0但oldthr大于0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {//老数组的length和thresold都不大于0
newCap = DEFAULT_INITIAL_CAPACITY;//初始化新数组,设定长度为默认容量16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//计算thresold
}
if (newThr == 0) {//如果计算的newThr为0
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];//这里才真的创建好新的数组
table = newTab;
//开始转移原数组里的数据
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
//如果原数组里的位置只有一个普通的节点那么该节点在新数组里的位置就是
newIndex=k.hash&newCap-1
if ((e = oldTab[j]) != null) {//如果原数组的下标有元素才转移,没元素就不管
oldTab[j] = null;
if (e.next == null)//该节点没有链表即是普通节点
newTab[e.hash & (newCap - 1)] = e;//普通节点在新数组里的位置计算
else if (e instanceof TreeNode)//如果该节点有下节点但又是红黑树节点,那么就打散加的新数组里
((TreeNode)e).split(this, newTab, j, oldCap);
else { // 如果有下节点不是红黑树那么就是链表了
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {//这里很关键
为什么?为什么不是e.hash & newCap-1
1、首先知道hashMap的数组长度是2的幂次方(下面会讲)
2、还要知道任何一个2的幂次方的数-1会得到高位为0其余为全为1
(比如 16-1 得到01111)
3、所以如果e.hash & oldCap == 0那么就说明在oldCap对应e.hash的值
的这一为必然是0;所以如果用e.hash & newCap-1得到的结果和该节点在原数组中的下标一样,
或者说该节点也应该在新数组中和原数组一样的下标位置
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;//如果与老数组最高位对应的hash的那一位不是0
那么该节点在新数组的位置就是oldCap+e.hash&newCap-1
}
}
}
}
}
return newTab;
}
说明:resize()方法比较重要,重点理解如何扩容和老数据到新数组里的下标是怎么转换的
//说明:该方法是put底层调用的方法也很重要,要理解整个过程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//添加元素前要先判断数组是否初始化
n = (tab = resize()).length;//没有就初始化,这里resize方法就是上面分析的第一次就是将数组长度赋值为16
if ((p = tab[i = (n - 1) & hash]) == null)//注意这里
在这里开发者用(n-1) & hash来计算节点的下标,但计算下标不是应该hash % n吗?
所以这里开发者要求数组的长度必须是2的幂次方这样才能保证(n-1) & hash == hash % n
所以这里也就是为什么数组的长度每次要是2的幂次方的原因
tab[i] = newNode(hash, key, value, null);//如果下标对应位置没有元素那么就在该处添加
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果该节点是红黑树那么就按红黑树的规则加入
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {//遍历链表
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);//在链表末尾加入该元素
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//如果加入后链表的长度大于8了那么就转为红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // 如果存在该加入元素的k对应的节点那么就替换原来的老值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//加入元素后判断数组是否要扩容
resize();
afterNodeInsertion(evict);
return null;
}
说明:putval的过程如下:
1、判断数组是否初始化,没有就初始化
2、判断带插入的位置是否存在元素,没有就直接插入,存在分三种情况
1)是红黑树的节点:那么就按红黑树的规则插入
2)是链表的节点那么就遍历链表把该元素插入到末尾或者替换链表中与其key相同的元素
3)带插入位置的元素的k和该元素相同,那么就直接替换老值
4)判断是否要扩容
总结
1)总体把握hashMap的底层数据结构:数组+链表+红黑树
2)理解为什么数组的长度一直是2的幂次方和数组扩容过程
3)掌握老数据如何确定新位置的过程
4)掌握resize()和putval()和thresold、loadfactory的作用