用caffe跑自己的图像数据用于分类
本文详细介绍,如何用caffe跑自己的图像数据用于分类。
1 首先需要安装过程见 http://www.cnblogs.com/love6tao/p/5706830.html 同时依据上面教程,生成了caffe.exe
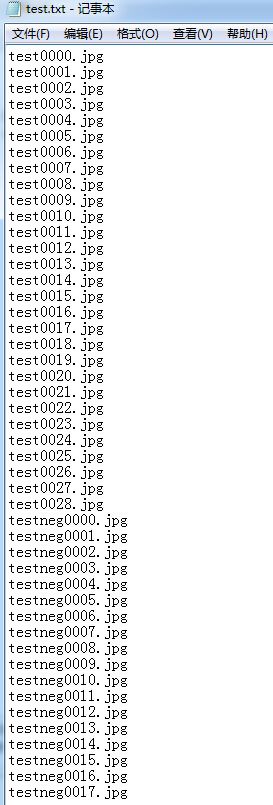
2 构建自己的数据集。分为train和val 两个数据集,本次实验为2分类任务,一个是包含汽车的图像,一个是不包含汽车图像,其中train 为训练数据集,该文件夹中图像命名格式为trainpos0000.jpg和trainneg0000.jpg,图像通过该命名方式连续编码,val为验证数据集或者叫测试数据,该文件夹中图像命名格式为test0000.jpg,和testneg0000.jpg。如下图所示


图像可以用过opencv中cvresize函数就行缩放到256*256.
然后需要准备标签数据,通过新建train.txt val.txt和test.txt就行设置。通过windows命令行进行自动生成,首先在运行中输入cmd ,出现DOS窗口,输入d: 切换到D盘,
再输入cd D:\caffe\caffe-master\caffe-master\mydata\train 切换到train文件夹下 ,输入命令“dir/s/on/b>d:/train.txt”,则会在D盘生成一个名为train的文本文件,里面存放着全部图像的路径。 通过查找替换,最终生成的 train.txt val.txt和test.txt 。其中val.txt和test.txt 相比,test没有标签.注意标签从0开始,如果是二分类,应该是0和1,而不是下图的1和2.


3 讲数据集转化为caffe的数据类型
caffe的数据类型为LMDB和leveldb,caffe并不处理原始数据,而是转化为LMDB或者LEVELDB格式,这样可以保持较高的IO效率。
怎么转换呢?在caffe工程中有convert_imageset的工程,对其进行编译,形成convert_imageset.exe即可。
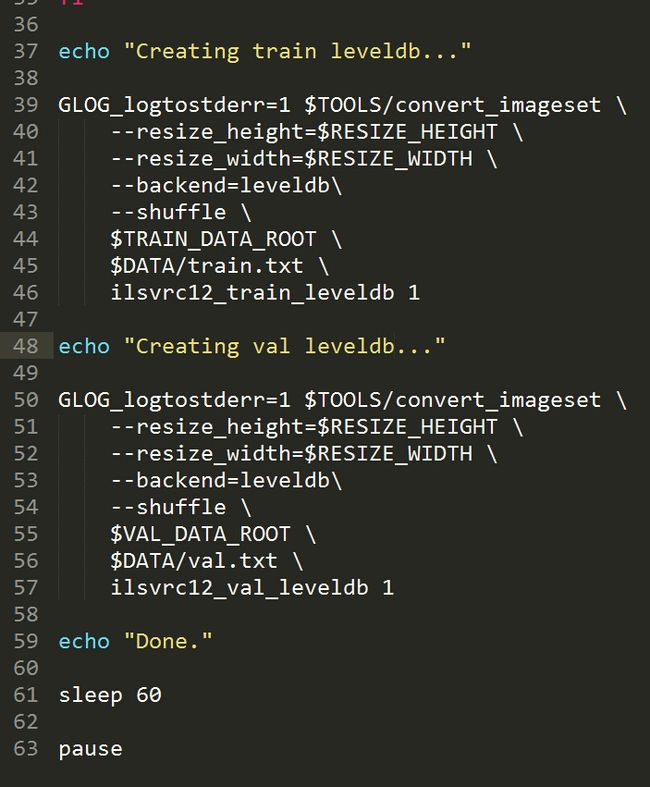
然后利用create_imagenet.sh使数据集生成leveldb格式的文件。create_imagenet.sh放在examples/imagenet中,将它拷贝到数据集的路径下,本文数据集
关键的是修改create_imagenet.sh中的路径使之能够进行数据转换
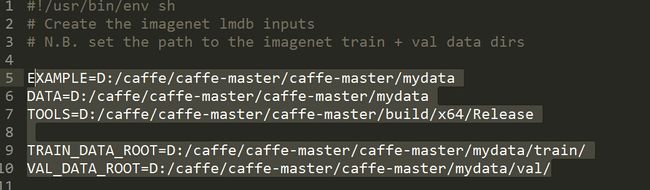
example设定为数据集的路径 data也设定为数据集路径 tools为convert_imageset.exe的路径
train_data_root 训练数据集路径 val_data_root 测试数据集路径
后面resize为false则其不需要转换为256*256
由于本文是转为leveldb文件类型 添加了这一句代码 ”--backend=leveldb\ “ 同时注意train.txt val.txt的路径是data路径下,
运行该程序,生成了两个leveldb文件夹,ilsvrc12_train_leveldb和ilsvrc12_val_leveldb
4 计算图像的均值
首先生成compute_image_mean.exe文件,该文件在caffe工程中也存在对应程序,对其进行编译,形成compute_image_mean.exe即可。
然后在examples/imagenet下有一个sh文件make_imagenet_mean.sh,将它拷贝到个人数据文件夹mydata中,然后打开这个文件进行编辑。
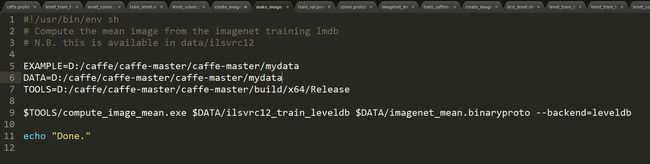
example是数据集路径 data 为数据集路径 tools为compute_image_mean.exe路径
第9行为利用exe 对train_leveldb 数据生成 imagenet_mean.binaryproto
运行make_imagenet_mean.sh后,会生成了 imagenet_mean.binaryproto
5 开始设计网络
5.1 设置train_val.prototxt文件
从caffe-root\models\bvlc_reference_caffenet中拷贝train_val.prototxt进行修改。
设置 mean_file: 和数据source:
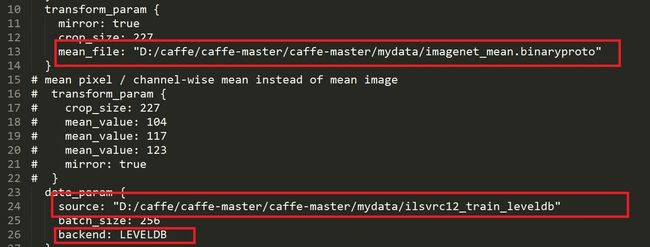
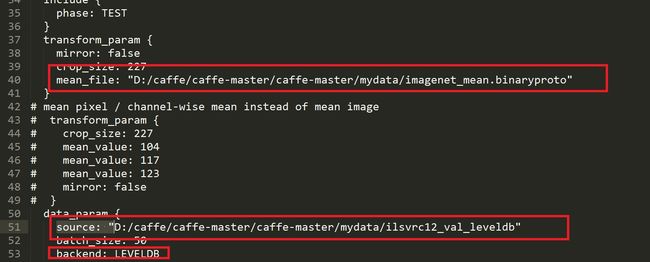
5.2 设置solver.prototxt文件
从caffe-root\models\bvlc_reference_caffenet中拷贝solver.prototxt进行修改。net的路径为上面设置的路径 ,后面迭代的参数按照实际情况修改。
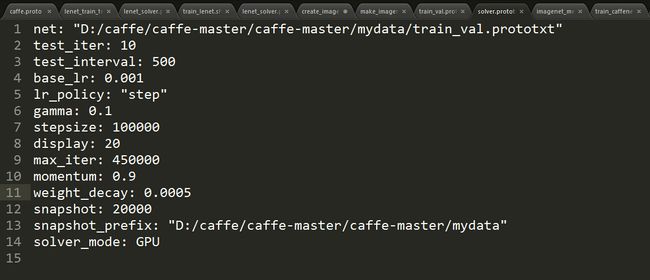
5-3 训练网络,运行train_caffenet.sh文件
从caffe-root\\examples\imagenet中拷贝train_caffenet.sh进行修改。

设置caffe.exe路径 和上述solver.prototxt文件路径
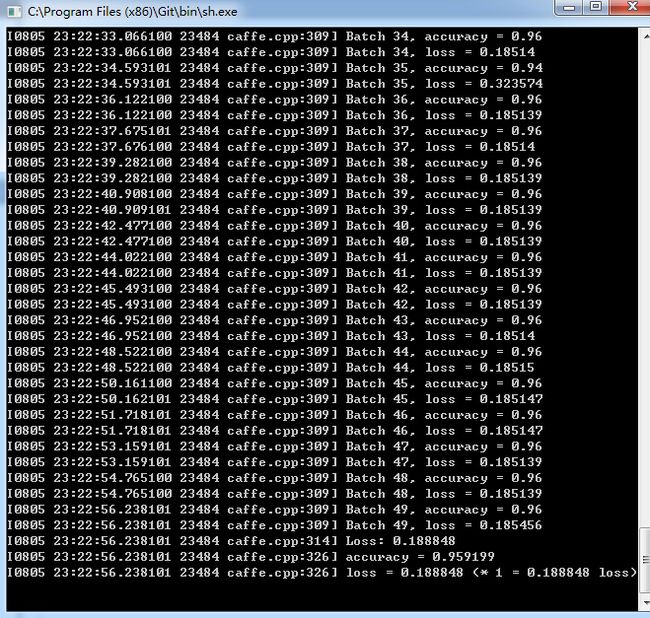
训练结果:运行train_caffenet.sh文件效果
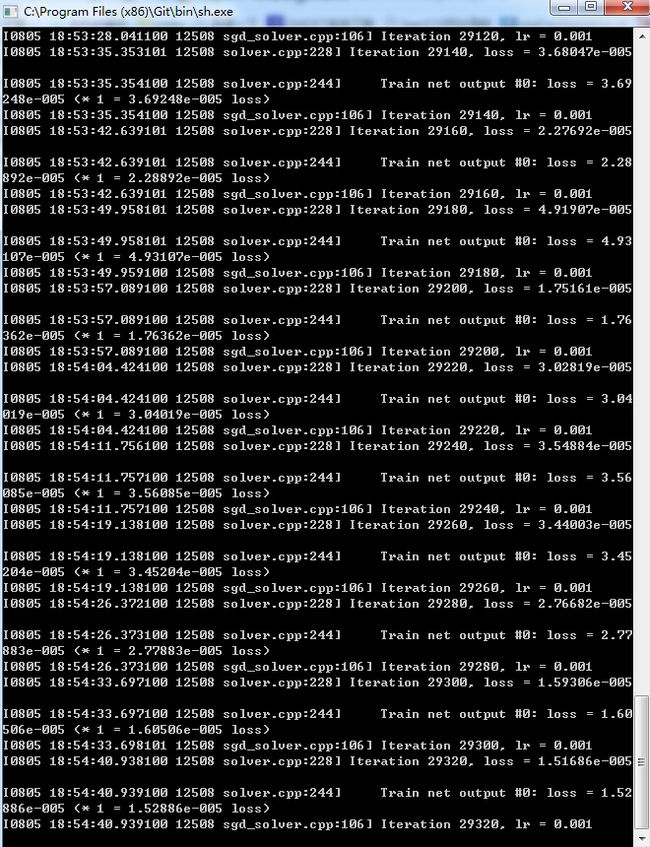
本机配置是win7+cude8.0+1080的显卡,可以看到loss在不断的降低。这是在设置好solve参数的情况下。
生成的model 为 mydata_iter_100.caffemodel
5-4 测试网络
在数据目录下新建一个文本文件,然后将后缀名改成sh。填入以下语句:

首先设置caffe.exe的路径 然后设置网络的路径,最后设置载入的训练参数路径。运行该sh文件,得到最后的分类正确率为:95%
到处,整个训练和测试过程走通了,后续就是调节参数的问题了。