浅谈hive及理论
为什么使用它
Hive会把sql语句转换成mr,如果单独写mr的过程很复杂
它是什么
Hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并可以使用sql语句查询
架构图
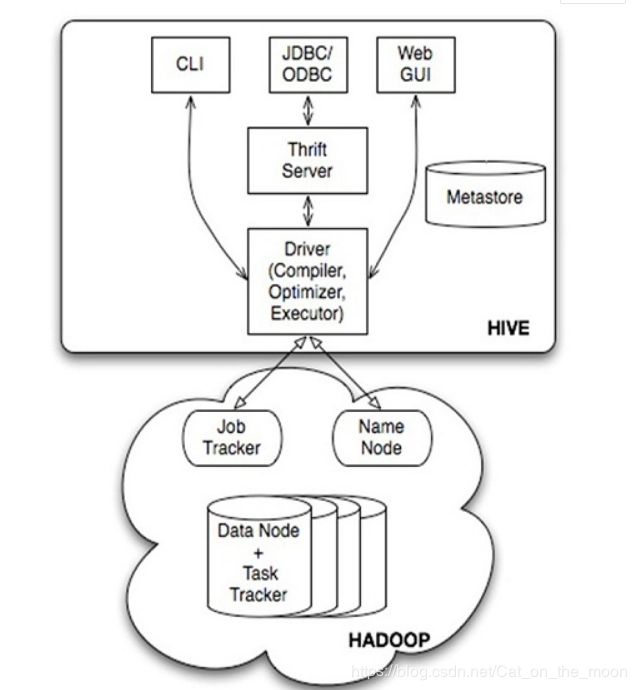
组件介绍
用户接口:Cli,Client和WebGUI,其中最常用的是cli,cli启动的时候会同时启动一个hive副本,client是hive客户端,用户连接到hiveServer.在启动client模式的时候,需要指出hiveServer所在的节点,并且在该节点启动hiveServer.WUI是通过浏览器也能访问Hive
Metastore:元数据包括表名,表所属数据库,拥有者,列,字段,类型等存储到数据库表中-mysql
Complier:编译器.optimizer:优化器. executor:解释器,完成sql查询语句存储到hdfs上,并在随后有mapperreduce调用执行
Hive的客户端连接服务器走的是thrift协议
JDBC/ODBC是hive的java实现
Hive与hadoop的关系:hive利用hdfs存储数据,利用mapperreduce查询分析数据
优缺点
优点:1.简单易上手,提供了类似sql的查询语句2.可扩展,为大数据集设计了计算能力(mr作为计算引擎,hdfs作为存储系统)3,多接口,可通过beeline,JDBC,thrift
缺点:1.hive的效率比较低(mr)2.不支持更新,删除,插入
应用场景:1.数据挖掘-用户行为分析2.非实时分析-日志分析,文本分析3数据汇总-每天点击情况,流量统计
OLAP和OLTP
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁,并行事务处理多,但是一般都很短。使用一般用途或事务处理模板。
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长事务,但是一般事务的个数很少,往往是一个事务独占系统
对比: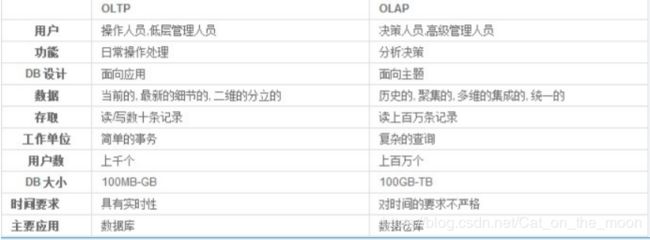
hive建模理论
名词解释:
DSS:(decision-support system)决策支持系统
ODS,Operational Data Store:操作数据源
DW:数据仓库;data warehourse
DM:数据集市(Data Market)
Dws:data warehouse service 服务数据层
Dwd:data warehouse detail 细节数据层
Dwb:data warehouse base基础数据层
OLAP:联机分析处理(On-Line Analysis Processing)
OLTP:联机事务处理(On-Line Transaction Processing)
事实表(fact)
维度表dimension
数据仓库的发展历程
数据仓库概念最早可追溯到20世纪70年代,希望提供一种架构将业务处理系统和分析处理分为不同的层次
20世纪80年代,建立TA2(Technical Architectue2)规范,该明确定义了分析系统的四个组成部分:数据获取,数据访问,目录,用户服务;
1988年,IBM第一次提出信息仓库的概念:一个结构化的环境,能支持最终用户管理其全部的业务,并支持信息技术部门保证数据质量:抽象出基本组件:数据抽取,转换,有效性验证,加载,cube开发等,基本明确了数据仓库的基本原理,框架结构,以及分析系统的主要原则
1991年,Bill Inmon出版提出了更具体的数据仓库原则:
数据仓库是面向主题的
集成的
包含历史的
不可更新的
面向决策支持的
面向全企业的
最精细的数据存储
数据快照式的数据获取
尽管有些理论目前仍有争议,但凭借此书获取”数据仓库之父”的殊荣
Bill Inmon主张自上而下的建设企业数据仓库,认为数据仓库是一个整体的商业智能系统(BI)的一部分.一家企业只有一个数据仓库,数据集市的信息来源出版数据仓库,在数据仓库中,信息存储符合三范式,大致结构: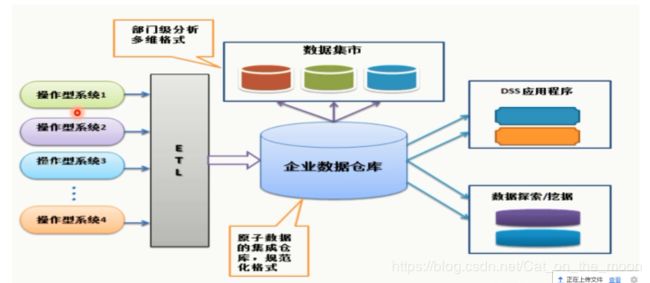
Ralph KimBall出版,主张自下而上的建议数据仓库,极力的推崇建立数据集市,认为数据仓库是企业内所有数据集市(模块)的集合,信息总是被存储在多维模型中,其思路:

两种思路和在实的操作中都很信成功的完成项目将会,直到最终Bil Inmon提出了新的BI架构
CIF(Corporation Information Factory),把数据集合包含了进来.CIF的核心是将数据框架划分为不同的层次以满足不同的场景的需求.比如常见的ODS,DW,DM等,每层根据实际场景采用的建设方案, 改思路也是目前的数据仓库建设的架构指南,但自上而下还是自下而上的进行数据仓库建设,并未统一
数据仓库建模的目标
访问性能:能够快速查询所需的数据,减少数据IO
数据成本:减少不必要的数据冗余,实现计算结果数据利用,降低大数据系统中的存储成本和计算成本
使用效率:改善用户应用体验,提高使用数据的效率
数据质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量,一致的数据访问平台
So:大数据的数据仓库建模需要通过建模的方法更好的组织,存储数据,以便在性能,成本,效率和数据质量之间找到最佳的平衡点
四种模型
er实体模型–关系模式范式
关系数据库设计时,遵照一定的规范要求,目的在于降低数据的冗余性和数据的一致性,目前业界范式有:第一范式:(1NF),第二范式:(2NF),第三范式:(3NF),巴斯-科德范式(BCNF),第四范式(4NF),第五范式(5NF)
第一范式:列都应该是原子性的,即数据表的每一列都是不可侵害(不可拆分)的原子数据项
第二范式在1NF的基础上,实体的属性完全依赖于主键,不能存在仅依赖主键字一部分的属性(复合主键)
第三范式(3NF)在2NF的基础上,任何非主属性不依赖于其它非主属性(除了主键以外,列与列之间不能有依赖关系)
在信息系统中,将事务(事件,现象)抽象为”实体”,”属性”,”关系”来表示数据关联和事物描述;实体:entity,关系,relationship,这种对数据的抽象建模通常被称为ER实体关系模型;
实体:通常为参与到过程中的主体,客观存在的,比如:商品,仓库,货拉,汽车(此实体非数据库的实体表)
属性:对主体的描述,修改即为属性,比如商品的属性有商品名称,颜色,尺寸,重量,产地等;
关系:ER图,(实体用矩形表示,关系用菱形表示,属性使用椭圆表示)
应用场景
1.ER模型是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建模的方式
2.Bill Inom提出的数据仓库理论,推荐采用ER关系模型进行建模
3.BI架构提出分层架构,数据仓库底层的ods,dwd多采用ER关系建模就行设计
4.ER模型建模标准:尽量的避免数据冗余
维度模型
Ralph Kimball推崇数据集市的集合为数据仓库,同时也提出了对数据集市的维度建模,将数据仓库中的表分为事实表和维度表两种类型
1.事实表
在ER模型中抽象出了有实体,关系,属性三种类别,在现实世界中,每一个操作型事件,基本都是发生在实体之间,伴随着这种操作事件的发生,会产生可度量的值,而这个过程就产生了一个事实表,存储了每一个可度量的事件
2.维度表
维度:顾名思义,看待事物的角度.比如从颜色,尺寸的角度来比较手机的外观,从cpu,内存等较比较手机的性能
维度表一般为单一主键,在ER模型中,实体为客观存在的事物,会带有自己的描述性属性,属性一般为文本性,描述性这些描述被称为维度表;
比如商品,单一主键;商品id,属性包括产地,颜色,材质,尺寸,单价等会,但并非属性一定是文本,比如单价,尺寸,均为数值型描述性的,日常主要的维度抽象包括:时间维度表,地理区域维度表等.
星型: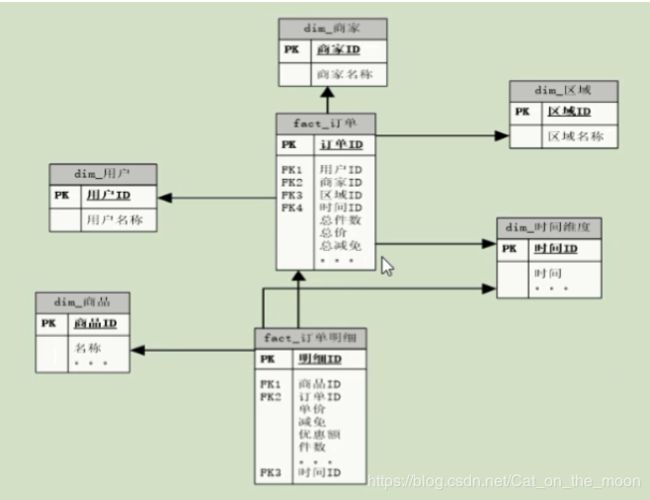
雪花型: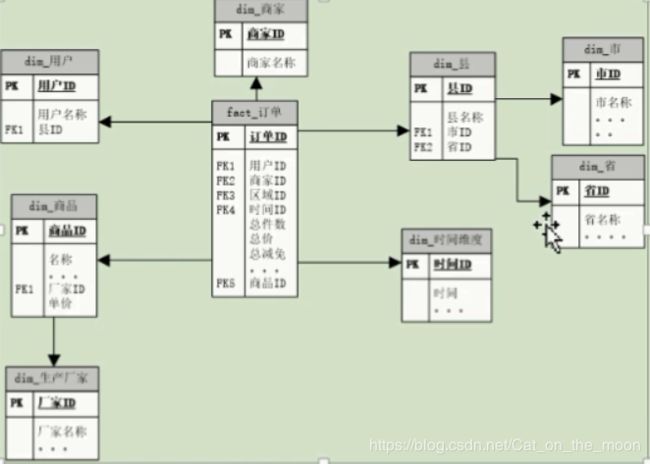
雪花模型和星型模型对比:
1.冗余:雪花模型符合业务逻辑设计,采用3NF设计,有效降低数据冗余;星形模型的维度表设计不符合3NF,反规范化,维度表之间不会直接相关,特殊部分存储空间
2.性能:雪花模型由于存在维度间的关系,采用3NF降低冗余,通常在使用过程中,需要连接更多的维度表,导致性能偏低;星形模型反三范式,采用降维的操作将维度整合,以存储空间为代价有效降低维度表连接数,性能较雪花模型高;
3.ETL(数据清洗):雪花模型符合业务ER模型设计原则,在ETL过程相对简单,但是由于阶段性模型的限制,ETL任务并行化较低;星形模型在设计维度表时反范式设计,所以在ETL过程中整合业务数据到维度表有一定难度,但是由于避免阶段性维度,可并行化处理
维度建模源自数据集市,主要面向分析场景
数据仓库建模
主流的OLAP引擎底层数据模型
如何决择:
牺牲时间换取空间;采用雪花模型
牺牲空间换取时间:采用星形模型(尽可能把所有的关联关系都放到一张表中)
dataVault模型
Data Vault是在ER模型的基础上衍生而来,模型设计的初识是有效的组织基础数据,使之易扩展,灵活的应对业务的变化,同时强调历史性,可追溯性和原子性,不要求对数据进行过度的一致性处理,并非针对分析场景设计
Data Vault模型是一种中心辐射式模型,其设计的重点围绕着业务键的集成模式,这些业务键是存储在多个系统中的,针对各种信息的键,用于定位和唯一标识记录或数据线
包含三种结构:
1.中心表-hub;唯一业务键的列表,唯一标识企业实际业务,企业的业务主体集合
2.链接表-link:表示中心表之间的关系,通过链接表串联整个企业的业务关联关系
3.卫星表–satallite:历史的描述性数据,数据仓库中数据的真正载体
Data vault模型更容易设计,ETL过程中更易配置化实现,hub想像成人体的骨架,link就是连接骨架的韧带组织,satalite就是骨架上的血肉
dataVult是对ER模型更近一步的规范化,由于对数据的拆解和更偏向于基础数据组织,在处理分析类场景时相对复杂,适合数据仓库的低层构建,目前实际应用场景较少
anchor模型
anchor是对dataVault模型做了更近一步的规范处理,初识是为了设计高度可扩展的模型,核心思想就是所有的扩展只添加不修改,于是设计出模型基本变成了k-v结构的模型,模型范式达到了6NF
Map模型
由于过度规范化,使用中牵涉到太多的join操作,目前木有实际案例,仅作了解
建模总结
以上为四种基本的建模方法:当前主流的建模方法为:ER模型(主要应用于数据库),维度模型(主要应用于数据仓库)
ER模型常用于OLTP数据库建模,应用到构建数据仓库时更偏重数据整合,站在企业整体考虑,将各个系统的数据按相似性一致性,合并处理,为数据分析,决策服务,但并不便于直接用来支持分析.
问题:
1.需要全面梳理企业所有的业务和数据流
2.实施周期长
3.对建模人员要求高
4.尽量避免数据冗余(不要吝惜表的数量);联合查询;(记录少)
维度模型
维度建模是面向分析场景而生,针对分析场景构建数据仓库模型;重点关注快速,灵活的解决分析需求,同时能够提供大规模数据的快速响应性能.针对性强,主要应用于数据仓库构建和OLAP引擎低层数据模型
不需要完整的梳理企业业务流程和数据
实施周期根据主题边界而定,容易快速实现demo
尽量要冗余,因为数据仓库(hive)后面是hdfs,硬盘空间无上限;推荐使用星形模型,可以使用雪花模型,但是层级不要太多;
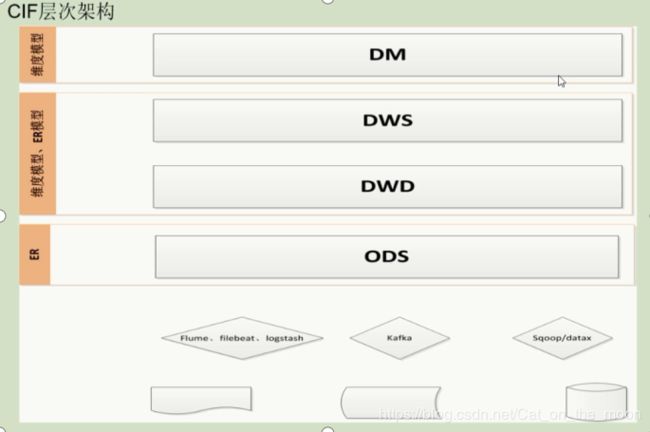
数据仓库模型的选择是灵活的,不局限于某一种模型方法
数据仓库的设计也是灵活的,以实际需求场景为导向
模型设计兼顾灵活性,可扩展,面对终端用户透明性
模型设计要考虑技术可靠性和实现成本
按照实效性,数据划分为:
①离线:数据延迟时间天级别,一般今天处理t-n天的数据,所以日常所说的数据仓库按照时间分;延迟1天,也称作t+1天
②准实时:数据延迟时间小时级别,一般今天处理h-n小时的数据,通常准实时
③实时:数据延迟级别为毫秒,秒级别,可以理解为当前处理当前时间时刻的数据.
实时场景:
1.个性化推荐
1.1实时:用户实时信息,比如位置,设备,当前会话浏览情况,最近的浏览
1.2离线:商品关联关系,用户相似性特征,位置偏好,设备偏好,关联偏好
2.用户画像
2.1实时:实时位置标注,当前偏好标注,当前设备标注
2.2离线:常驻位置,稳定偏好,常用设备,消费水平等标签
3.风控
3.1反欺诈,防刷单,薅羊毛等
3.2实时:用户位置,ip,设备,通讯录等
3.3离线:风险区域,风险用户,风险设备,多头等

大数据领域内,数据仓库的建设解决根本的应用问题
- 实效性高 业务灵活,多变 数据源多样性 数据质量参差不齐 应用场景复杂
针对各种问题和场景,在做技术造型和低层技术架构的时候需要考虑
- 梳理业务和响应的应用场景 需要处理的数据源的种类,类型,数据量 对实效性要求 对灵活性要求 对性能要求 对成本要求
误区
- 技术万能论 盲目崇拜新技术 脱离业务 一劳永逸 脱离业务场景的架构就是耍流氓
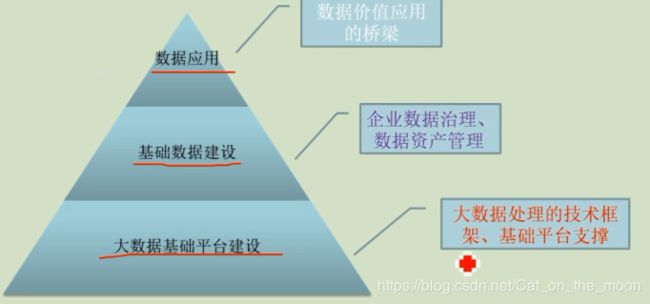
对大数据体系下基础建设的工作,主要有:
1.大数据基础平台维护,基础运维,优化;不过渡关注业务,数据内容本身,重点是集群的稳定性,性能,易用性,技术上会涉及底层源码,比如:hadoop,spark,hbase等,大数据底层框架的维护用户,–神秘但重要的底层建设者
2.大数据生态开发,工程性开发,应用相关开发:关注业务逻辑或者特定应用场景,不关注或仅关注特定的数据内容,大数据部分特定场景的应用开发,不会涉及过多的低层技术,多为大数据基本框架的使用者,用各种技术服务于业务场景,比如推荐系统开发,olap引擎,反作弊等业务应用场景----无所不能的大数据开发者
3.数据仓库,数据内容建设,开发:”大数据”真正的建设者,负责企业整体的数据资产建设和管理,负责数据治理体系,构建高质量,一致性,规范化的数据平台,关注企业整体业务情况和数据内容本身,对数据,业务有较高的敏感性,是所谓人工智能,自动驾驶等一切数据应用的底层基础数据建设者
注:总结简单望包涵,如有问题,可以一起讨论,谢谢