FeUdal Networks for Hierarchical Reinforcement Learning 阅读笔记
FeUdal Networks for Hierarchical Reinforcement Learning
标签(空格分隔): 论文笔记 增强学习算法
- FeUdal Networks for Hierarchical Reinforcement Learning
- Abstract
- Introduction
- model
- Learning
- Transition Policy Gradients
- Architecture details
- Dilated LSTM没看
Abstract
这篇论文主要是在 fedual reinforcenment learning 上面的改进和应用,
首先说说fedual reinforcement learning的形式:
1. 主要分成两个部分 Manger model和Worker model;
2. 其中Manger model的作用就是控制系统完成哪个任务,在文中,作者把每个任务编码成一个embedding(类似与自然语言的词向量的意思);
3. Worker model指的是针对与某个特定的任务,对环境进行交互(action);
4. 所以,在文章提到Manger model 的时间分辨率很低,而Worker model的时间分辨率很高
5. 作者提到一个sub-policies的概念,我的理解是每一个任务都会有一个不同的策略;
6. 把任务变成embedding,可以快速接受一个任务。
We introduce FeUdal Networks (FuNs): a novel architecture for hierarchical reinforcement learning. Our approach is inspired by the feudal reinforcement learning proposal of Dayan and Hinton, and gains power and efficacy by decoupling end-to-end learning across multiple levels allowing it to utilise different resolutions of time. Our framework employs a Manager module and a Worker module. The Manager operates at a lower temporal resolution and sets abstract goals which are conveyed to and enacted by the Worker. The Worker generates primitive actions at every tick of the environment. The decoupled structure of FuN conveys several benefits in addition to facilitating very long timescale credit assignment it also encourages the emergence of sub-policies associated with different goals set by the Manager. These properties allow FuN to dramatically outperform a strong baseline agent on tasks that involve longterm credit assignment or memorisation. We demonstrate the performance of our proposed system on a range of tasks from the ATARI suite and also from a 3D Deep-Mind Lab environment.
Introduction
作者在提到了几个目前增强学习应用的几个难点:
1. 增强学习一直存在着长时间的信誉分配问题(long-term credit assignment),目前这个问题一直都是用Bellman公式解决的,然后最近有人将每一次选择的action分解成四个连续的action;
2. 第二个难点在于reward的回馈是稀疏的;
针对以上两个问题作者在基于前人工作的基础上,提出了自己的网络结构以及训练策略:
1. the top-level, low temproal resolution Manger model和 the low-level ,high temporal resolution Worker model
2. Manger model 学习潜在的状态(个人理解:暗示着该状态想要往哪个目标发展),然后 Worker model接收Manger model的信号选择动作
3. Manger model 学习信号并不是由Worker model 提供的,而是只是外界环境提供的,换句话说,外界环境的reward提供给Manger model;
4. Worker model的学习信号是有系统内部的状态(intrinsic reward)提供的
5. 在Manger model和Worker model之间并没有梯度传播
The architecture explored in this work is a fully- differentiable neural network with two levels of hierarchy (though there are obvious generalisations to deeper hierar- chies). The top level, the Manager, sets goals at a lower temporal resolution in a latent state-space that is itself learnt by the Manager. The lower level, the Worker, oper- ates at a higher temporal resolution and produces primitive actions, conditioned on the goals it receives from the Man- ager. The Worker is motivated to follow the goals by an intrinsic reward. However, significantly, no gradients are propagated between Worker and Manager; the Manager re- ceives its learning signal from the environment alone. In other words, the Manager learns to select latent goals that maximise extrinsic reward.
作者最后终结了这篇论文的贡献:
1. 应该是将fedual reinforcenment learning泛化了,可以用在很多系统下;
2. 作者提出了以训练Manager model的新方法(transition policy gradient),它能够产生目标语义上的一些信息(我感觉就是将目标进了embedding);
3. 传统的学习信号完全依赖于外界的环境,但是在该文章中,外界的学习信号(reward)是用来训练Manger Model,然后训练Worker Model是内部产生的信号;
4. 作者也使用了新型的LSTM网络dilated LSTM,因为在Manger Model中,需要长时间的记忆状态,因为LSTM的时间分辨率比较低
作者将自己的方法和2017年有人人提出的policy-over-option 进行了对比
A key difference between our approach and the options framework is that in our proposal the top level produces a meaningful and explicit goal for the bottom level to achieve. Sub-goals emerge as directions in the latent state-space and are naturally diverse.
理解:
1. Manger Model 在整个模型中处于一个上层地位,能够产生一个指导性的信号给下层网络(Worker Model);
2. 第二层含义就可能是每个大任务有很多的小任务,任务的不同阶段的reward值可能不一样,所以作者认为大任务下面有很多小任务从而导致embedding的多样性,有点类似与[1]这篇论文的思想
model
如下为模型示意图以及具体的计算公式:
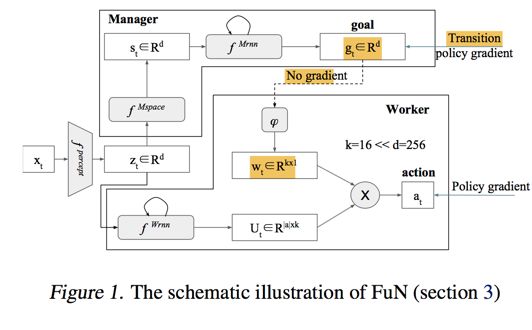
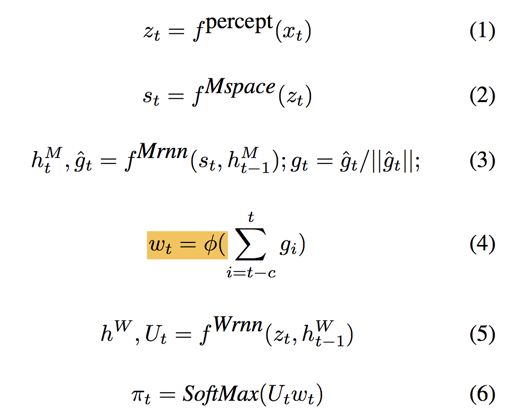
Here hM and hW correspond to the internal states of the Manager and the Worker respectively. A linear transform ϕ maps a goal gt into an embedding vector wt∈Rk , which is then combined via product with matrix Ut (Workers output) to produce policy π – vector of probabilities over primitive actions.
说明:
1. fpercept 是一个特征提取层
2. fMspace 没有改变维度,有两种可能L2_norm以及全连接层
3. ϕ 是一个没有偏置值的全联接层
4. 图中 wt 就是所谓的Goal embedding
5. 根据公式6可以知道,最后Worker Model输出的是每一个action的可能性
Learning
作者在这一段讲述了如何更新系统的权重的。
1. 网络部分的卷积层(特征提取层)有两个更新途径,第一个是Policy Gradient;第二个是TD-learning, 分别对应于Worker Model和 Manger Model;
2. 在这一部分,作者简单的说明了一下,如果在训练的时候,Worker Model 和Manger Model之间由梯度传播的话,可能导致Manger Model内部一些语义的信息丢失,所以把 gt 当作系统内部的隐藏信息;
3. Manger Model是基于value-base gradient,而 Worker Model 是基于Policy-based gradient
4. 学习信号(reward),Manger Model 的学习信号是环境的稀疏信号,而Worker Model的学习信号则是由Manger Model产生的
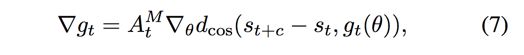
![]()
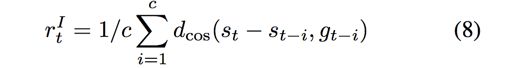
![]()
![]()
- 公式7,Manger Model的梯度(损失函数);
- AMt Manger Model TD-error
- 公式8,Worker Model的reward值,内部计算求得的
- 公式9,Worker Model的损失函数
- ADt Worker Model TD-error
论文对应句子:
- The conventional wisdom would be to train the whole architecture monolithically through gradient descent on either the policy directly or via TD-learning
- The outputs g of the Manager would be trained by gradients coming from the Worker. This, however would deprive Manager’s goals g of any semantic meaning, making them just internal latent variables of the model
- Manager to predict advantageous directions (transitions) in state space and to intrinsically reward the Worker to follow these directions.
- The intrinsic reward that encourages the Worker to follow the goals
论文也给出了作者这么做的一些道理:
1. intrinsic reward给了Worker Model一个训练的目标,和状态改变的一个方向
2. 之前也说过,一个大任务可以分成几个小任务,每个任务都会对应着不同的sub-policy,这样就可做到 sub-goal 对应sub-policy;
3. intrinsic reward是作者的一个创新点;
Transition Policy Gradients
作者在之前的基础上,提出了一个更新Manger Model的方式
在这之前作者先做了一些铺垫:
- 定义了一个函数 ot=μ(st,θ) ,来表示一个high level一个函数来选取子策略(sub-policy)
- 作者做了一个假定选取的策略在该段子任务是固定的
- 所以,对应的就是转移函数分布(transition distribution)( p(st+c|st,ot) ),而2选择的策略被称为 transition distribution,对应的函数表示为
πTP(st+c|st,μ(st,θ))(transition policy),该公式描述的是给定初始状态 st 和选择子策略(sub-policy) μ(st,θ) ,求最终子任务结束时,状态的分布 st+c
然后,作者给出了梯度的计算方法
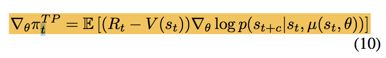
▽θlogp(st+c|st,μ(st,θ)) 就是transition policy gradient
然后 作者又给了 p(st+c|st,μ(st,θ)) 的计算方法:
![]() (没看懂作者怎么得来的)
(没看懂作者怎么得来的)
然后用公式(10)的梯度替代公式(7)的梯度 更新Manger
Architecture details
fpercept 是一个特征提取网络,网络结构和DQN的卷积层结构一样
fMspace 是一个全联接层,将特征层投影成一个16维embedding
fWrnn 是一个标准的LSTM结构
fMrnn 作者提出的dilated LSTM 结构
原因在于Manger的时间分辨率非常低,而 Worker的时间分辨率较高
Dilated LSTM(没看)
1: Unsupervised Perceptual Rewards for Imitation Learnining