什么?卷积层会变胖?人工智能之光---CNN卷积神经网络(原理篇)
0.学习路径示意图
Hello,各位小伙伴大家晚上好呀,你们期待已久的CNN卷积神经网络原理篇要来咯。上期我们讲到神经网络已经逐步成为人类智能生活的璀璨明珠,并介绍了BP神经网络的整个训练过程,整个流程紧凑而又科学,似乎BP神经网络已经能解决很多问题了,但细心的小伙伴会发现博主并没有提及BP神经网络的缺点,是的,博主并没有提及,其实是博主忘记了....

But,这并不影响我们CNN的教学,这期内容博主正好通过BP神经网络的缺点来开展CNN的教学,换个角度想,这还起到承上启下的作用,刺不刺激,惊不惊喜?这都能被博主圆了过来。

好了,废话不多说,这期内容主要分为以下几点:
BP神经网络的局限性
CNN卷积神经网络的原理
CNN卷积神经网络的超参数设置
总结
1.BP神经网络的局限性
相信看过上期的内容的小伙伴们应该都会比较熟悉BP神经网络了。没有看过的小伙伴也可以去看一看,BP神经网络虽然我们不常用,但是它的原理是CNN,RNN,乃至于其他网络结构都会涉及的。
阿力阿哩哩,公众号:Python机器学习体系深度学习开端---BP神经网络
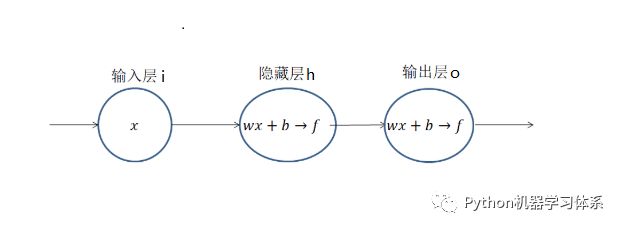
为了讲清BP网络的局限性,博主还是拿出上期画的最简单的BP网络结构图来讲解,相信小伙伴们对这个图也不陌生了把。想一下,上一期我们为了求解损失Loss 列出了关于w,b 的方程,并通过梯度下降的方法去求解最佳的(w , b),从而得到最小的损失Loss。换言之,上一期的内容我们简单来讲就是站在山上找最陡峭的地方(梯度),不断地往下走,一直走到山谷,这时候的我们所在坐标(w , b)就是Loss方程的最优解。
为此,针对上面的这个网络结构,我们要对隐藏层和输出层求4个偏导,又因为隐藏层的输出作为输出层的输入,这时我们就要用到求偏导的链式法则,公式如下:

由上面的公式,我们可以看出,两个神经元,为了求出隐藏层和输出层最佳的(w , b),我们就要求四个偏导,期间还得为链式求导付出4次连乘的代价。

现在,重点来了,如上图,倘若我们的网络层次越深,偏导连乘也就越多,付出的计算代价也就越大。
仅接着,一个网络层不单止一个神经元,它可能会有多个神经元,那么多个神经元的输出作为下一级神经元的输入时,就会形成多个复杂的嵌套关系。
我们知道BP神经网络层级之间都是全连接的,所以网络结构越复杂,那要求的(w , b)就会非常多,整个网络就会收敛得非常慢,这是我们所不希望看到的。
这就是BP网络的局限性,特别是针对图像这些冗余信息特别多的输入,如果用BP网络去训练,简直就是一场计算灾难。那么既然问题出现了,就会有人提出解决方法。这时候CNN卷积神经网络便应运而生了。
2.CNN卷积神经网络的原理
说了这么多,博主这就给小伙伴们来个CNN网络结构图,让大家都有个直观的了解。小伙伴们可以看到一个经典的CNN网络结构一般包含输入层(Input layer)、卷积层(convolutional layer)、池化层(pooling layer)和输出层(全连接层+softmax layer)。虽说目前除了输入层,咱啥也不认识,不过,不要慌,接下来就是剖析CNN的精彩时刻。

2.1卷积神经网络与BP网络的区别:
1)总有至少1个的卷积层,用以提取特征。
2)卷积层级之间的神经元是局部连接和权值共享,这样的设计大大减少了(w , b)的数量,加快了训练。
以上便是卷积神经网络的特点,为了让小伙伴们更清晰地了解这个网络结构的特点,博主接下来将分别对它的两个特性和特有的网络层次进行详细讲解。
2.2卷积层(Convolutional Layer)
前面我们提到,图像拥有很多冗余的信息,而且往往作为输入信息,它的矩阵又非常大,利用BP网络去训练的话,计算量非常大,前人为此提出了CNN,它的亮点之一就是拥有卷积层。
小伙伴们可以想象一下,如果信息过于冗余,那么我们能否去除冗余取出精华部分呢?对,卷积层就是干这个的,用人话翻译过来就是压缩提纯。
那卷积层又是如何工作的呢?小伙伴们可以看下上面的CNN网络结构图。卷积层里面是不是有个小框框,那个就是卷积核(Convolutional Feature),压缩提纯的工作主要通过它来实现。
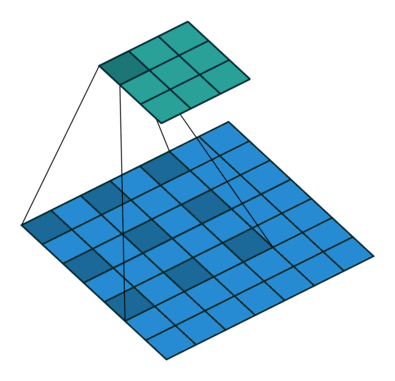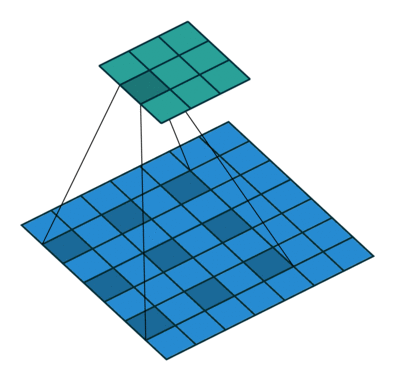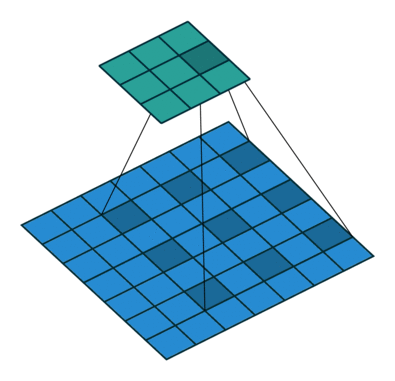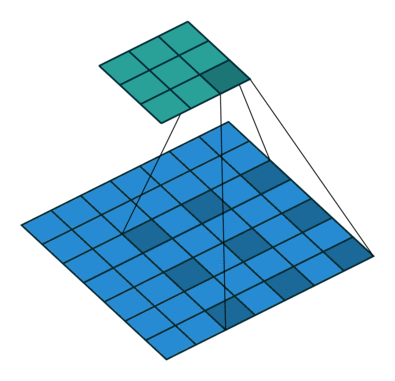
现在,博主上一个动图,让大家明白,这个卷积核小伙伴是怎么工作的,我们可以把蓝色矩阵看做卷积层的上一层,绿色矩阵看做卷积层,在蓝色矩阵上蠕动的便是卷积核,卷积核通过与他所覆盖蓝色矩阵的一部分进行卷积运算,然后把结果映射到绿色矩阵中。
那么接下来我们要了解的,卷积核是如何通过将结果映射到卷积层的。废话不多说,上图。
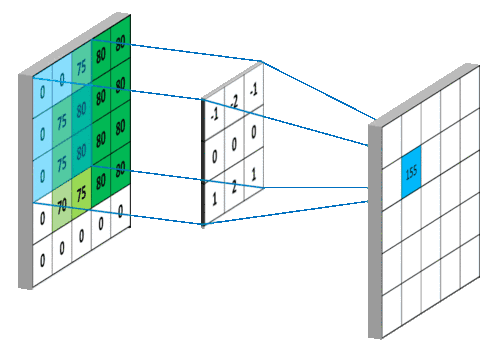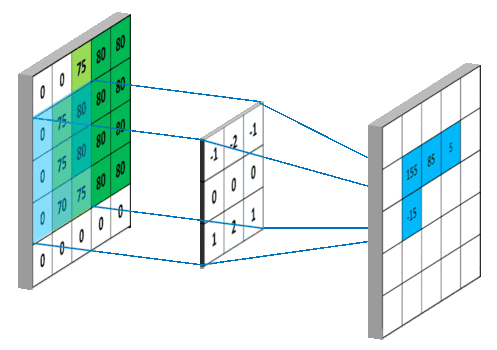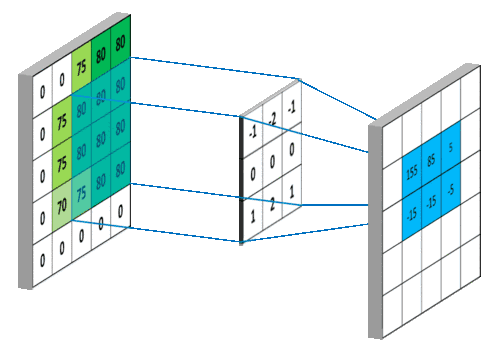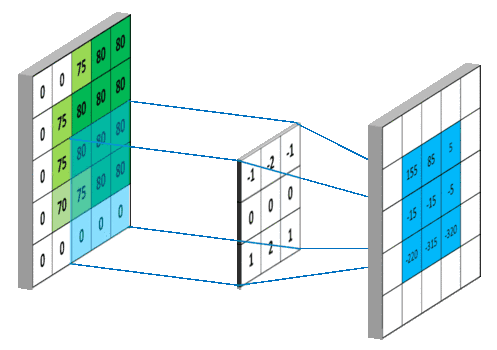
现在小伙伴们也看到了,卷积核在滑动过程中做的卷积运算就是卷积核w 与其所覆盖的区域的数进行点积,最后将结果映射到卷积层。
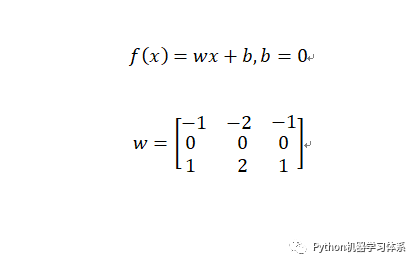
这样看来,我们将9个点的信息量,压缩成了1个点,也就是有损压缩,这个过程我们也可以认为是特征提取。
公式中(w , b)和之前BP神经网络并没有区别,就是权值w 和偏置b ,它们在初始化之后,随着整个训练过程一轮又一轮的迭代逐渐趋向于最优。
在卷积核f(x) = wx + b之后一般会加一个Relu的激励函数,就跟前文BP网络神经元的计算组合一样,只不过这里换成了Relu激励函数,而BP网络用的是sigmod激励函数,BP网络神经元运算公式如下图。这么做的目的都是让训练结果更优。

好了,讲到这,卷积层的工作方式,小伙伴们应该大致明白了,就是个压缩提纯的过程,而且每个卷积层不单止一个卷积核,它是可以多个的,小伙伴们又可以看一下上图的CNN网络的卷积层,小伙伴们会看到卷积层在变胖,因为这个卷积层的上一级经过多个卷积核压缩提纯,每个卷积核对应一层,多层叠加当然会变胖啦~
2.3局部连接和权值共享
博主在BP网络的局限性中提及BP网络层与层之间是全连接的,这就导致了整个训练过程要更新多对(w , b),为此CNN特定引入了局部连接和权值共享的两个特性,来减少训练的计算量。
博主先给小伙伴们讲下这么做的科学性在哪?图像或者语言亦或者文本都是冗余信息特别多的东西,倘若我们依照BP网络那般全连接,也就是将所有信息的权值都考虑进训练过程.....讲到这,小伙伴们应该明白了这么设计的用途了吧,没错,适当得放弃一些连接(局部连接),不仅可以避免网络将冗余信息都学习进来,同时也和权值共享特性一样减少训练的参数,加快整个网络的收敛。
下面给小伙伴们上他们的示意图,让大家有个更清晰的了解。

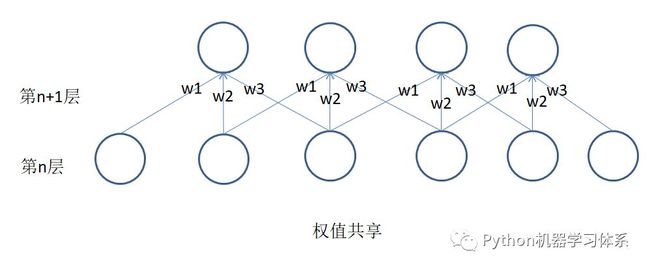
小伙伴们可以重点看权值共享这张图,它同时也采用了局部连接,总共就有3*4=12个权值,再加上权值共享,我们就只用求3个权值了,大大减少了我们的计算量。
2.4池化层(Pooling Layer)
一般来说,卷积层后面都会加一个池化层,这时候小伙伴们又可以往上看看CNN网络结构了,并且可以将它理解为对卷积层进一步特征抽样,池化层主要分为两种,这时候博主认为前面bb这么久,现在给大家上一张图,小伙伴们应该就明白池化层是干嘛用的了。

是的,max就是将对应方块中最大值一一映射到最大池化层(max pooling layer),mean就是讲对应方块的平均值一一映射到平均池化层(mean pooling layer),现在博主再给小伙伴们一个MaxPooling的动图观赏(✪ω✪)

2.5训练
好了,讲到这,我们终于把整个CNN架构特有的层次结构和属性都过了一遍,这时候小伙伴应该大致明白了,整个CNN架构就是一个不断压缩提纯的过程,目的不单止是为了加快训练速度,同时也是为了放弃冗余信息,避免将没必要的特征都学习进来,保证训练模型的泛化性。
CNN整个训练过程和BP网络差不多,甚至是博主之后更新的RNN、LSTM模型,他们的训练过程也和BP网络差不多,唯一不同的就是损失Loss 函数的定义,之后就是不断训练,找出最优的(w , b),完成建模,所以小伙伴们搞懂了BP网络的训练过程,就基本吃遍了整个深度学习最重要的数学核心知识了,还不了解 BP神经网络训练过程的小伙伴可以翻一下前文的链接,不会花太多时间,看完你会满心欢心得回来本文继续阅读的。
阿力阿哩哩,公众号:Python机器学习体系深度学习开端---BP神经网络
这时候,细心的小伙伴们会提出CNN网络结构输出层也就是softmax层没讲,是的,博主现在就开始讲。CNN损失函数之所以不同也是因为它,这层是CNN的分类层,先上图。
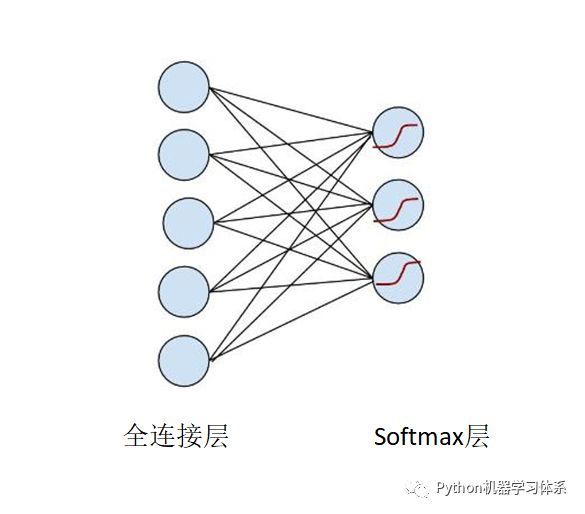
softmax层的每一个节点的激励函数
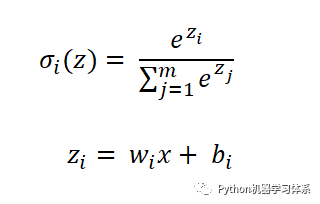
并且

上面的公式,我们可以理解为每个节点输出一个概率,所有节点的概率加和等于1,这也是CNN选择softmax层进行分类的原因所在,可以将一张待分类的图片放进模型,softmax输出的概率中,最大概率所对应的标签便是这张待分类图的标签。
这时候,博主给小伙伴们举个例子就明白啦。现在我们的softmax层有3个神经元,也就是说我们可以训练一个分三类的分类器,现在假设我们有一组带标签的训练样本,他们的标签可以如此标记,对应节点标记1,其他标记0。(其实就是onehot编码)
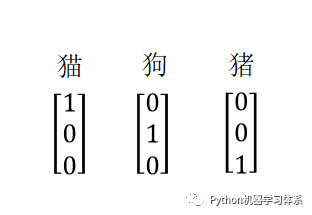
训练的时候将训练样本图片放入输入层,标签向量放入输出层,最终训练出一个模型。
此时,博主将一张待分类的图片放入我们的模型中,最后softmax层输出的结果是这样的。

这时,小伙伴就明白了上诉公式的含义了吧,0.85对应着最大概率,说明这张图片是猫,所有概率加起来等于1,这样是不是好理解很多啦。
好了,讲了这么久,我们还是没有把softmax的损失函数给写出来,它有点特殊,叫交叉熵,先上公式
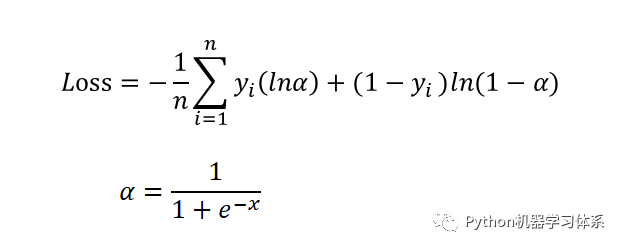
虽说长得奇奇怪怪的,但是整体的训练过程和BP网络的思路是一样,都是通过梯度下降法找出最优的(w , b),使Loss 最小,最终完成建模,因为过程和BP网络差不多,又限于篇幅,博主在此就不做更多的公式推导了,对交叉熵感兴趣的小伙伴可以点击下面的链接去了解一波。
图示Softmax及交叉熵损失函数
https://blog.csdn.net/hearthougan/article/details/82706834
3.CNN卷积神经网络的超参数设置
接下来介绍的内容就比较愉快了,主要介绍的是训练之前有些参数需要小伙伴们手动去设置,行话称之为超参数(hyperparameters)。
3.1卷积核初始化
卷积核的权值w和偏置b一开始是需要我们人工去初始化的,这里初始化的方法有很多,Tensorflow也在我们构建卷积层的时候自行给我们初始化了,但是哪天小伙伴心血来潮想自己初始化也是可以的,理论上世间万物都是遵循高斯(正太)分布规律的,我们的权值初始化可以根据高斯分布N(0,1)去设置,这样得到的初始化权值更加符合自然规律,毕竟咱们的计算机也是自然界的一部分。
3.2Padding
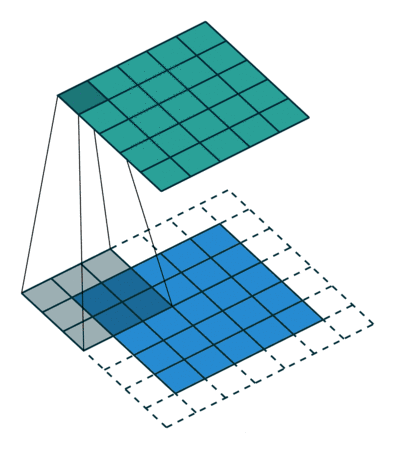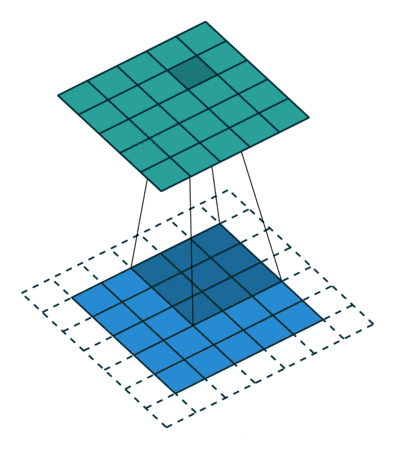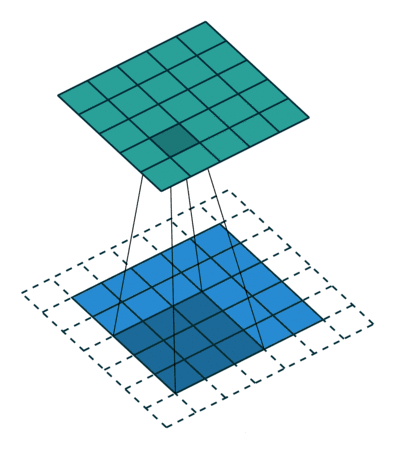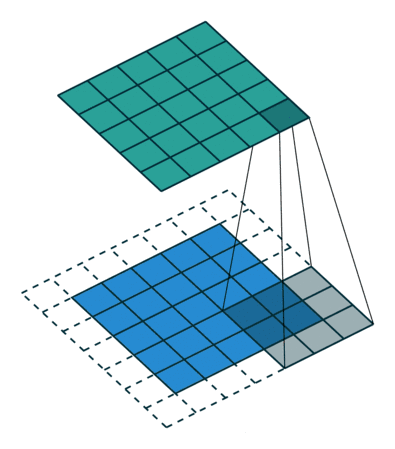
Padding是指对输入图像用多少个像素去填充,如下图。
这么做的目的也非常的简单,就是为了保持边界信息,倘若不填充,边界信息被卷积核扫描的次数远比不是中间信息的扫描次数,这样就降低了边界信息的参考价值了。
其次还有另外一个目的是,有可能输入图片的尺寸参差不齐,通过Padding来使所有的输入图像尺寸一致,避免训练过程中没必要的错误。
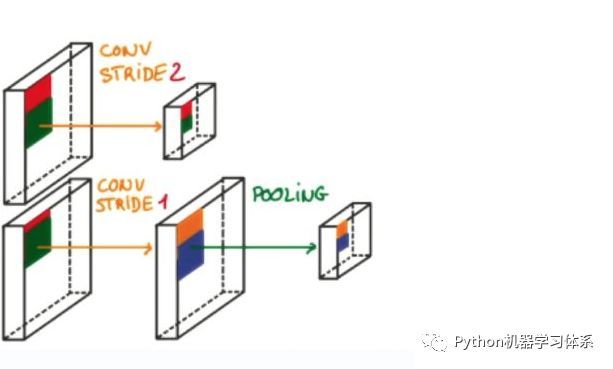
3.3Stride步幅
就是卷积核工作的时候,每次滑动的格子数,默认是1,但是也可以自行设置,步幅越大,扫描次数越少,得到的特征也就越“粗糙”,至于如何设置,业界并没有很好的判断方法,也就是说,一切全靠小伙伴们自己去试,怎么优秀怎么来。同样的,博主照例给大家上个示意图,让大家有个更加直观的了解。
4.总结
上面讲了这么多,其实放在TensorFlow里面就是几行代码的事,但是博主还是倾向于让小伙伴们理解整个CNN到底是怎么训练的,它的优点又在哪,这样小伙伴们也不至于只知道CNN能用来干嘛,也知道了CNN为什么能这么做,这样对各位小伙伴以后自己组建一个牛逼的网络是很有指导意义的。
呼应下主题,为什么说CNN是人工智能之光,可能小伙伴们会发现博主讲了这么多,CNN也就在图像领域呼风唤雨,并没啥了不起的,但是这个世界上奇思异想的人太多了,他们脑子里蹦出了一个又一个点子,让CNN在自然语言处理领域和语音处理领域也能大放异彩,尤其是最近博主在看某些脑洞大开的小伙伴已经将遗传算法和进化策略(博主也会在后续的文章中更新)融进了CNN,这些点子解决了人类智能生活中碰到的一个又一个难题。
所以,CNN就像光,逐渐照亮了人类整个智能生活的发展轨迹,但最值得我们尊敬的仍然是绽放这束光的科研工作者们,他们的认真努力让人类的现代社会变得更加便利与智能。小伙伴们身处这个伟大的时代,又从事或者学习这么利于人类发展的专业,是不是自豪感油然而生呢?
希望各位小伙伴都能把这一期的知识点吃透,而不是单单把博主的表情包收藏了,嘿嘿。
还有B站的小伙伴们注意啦!希望大家能给UP主来个推荐三连
(~(っ•̀ω•́)っ✎⁾⁾点赞->投币->收藏),你们的认可是博主持续更新的动力噢~
想听博主原声讲解?bilibili值得拥有~(っ•̀ω•́)っ✎⁾⁾ 我爱学习
https://www.bilibili.com/video/av51974694/
最后,博主最近寻思着怎么更了这么久,都没有人给博主评论留言,特地用舍友的微信看了下自己的公众号,原来是博主的公众号点赞还不够,没有权限开通评论功能,所以,各位爸爸们!༼༎ຶᴗ༎ຶ༽

