机器性能的几个维度(CPU + Memory + IO + Network)
文章目录
- 1 CPU
- 1.1 top命令
- 1.1.1 命令详解
- 1.1.2 常见使用
- 1.1.3 详细top命令文档
- 2 Memory
- 2.1 free
- 2.2 命令详解
- 2.2 vmstat
- 3 IO
- 3.1 df
- 3.2 iostat
- 4 Network
- 4.1 dstat
1 CPU
1.1 top命令
top - 10:35:46 up 63 days, 7:01, 1 user, load average: 0.07, 0.02, 0.00
Tasks: 273 total, 1 running, 272 sleeping, 0 stopped, 0 zombie
Cpu0 : 0.3%us, 0.7%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.3%si, 0.3%st
Cpu1 : 0.7%us, 0.7%sy, 0.0%ni, 98.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
Cpu2 : 0.3%us, 0.3%sy, 0.0%ni, 98.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.7%st
Cpu3 : 0.3%us, 0.7%sy, 0.0%ni, 98.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
Mem: 3922452k total, 3779492k used, 142960k free, 806428k buffers
Swap: 3145724k total, 280500k used, 2865224k free, 1511112k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18773 redis 20 0 152m 11m 1028 S 0.7 0.3 62:56.57 /opt/cachecloud/redis/src/redis-server *:6990 [cluster]
1.1.1 命令详解
第一行:
【10:35:46】:当前时间
【up 63 days, 7:01】:系统已运行时间
【1 user】:当前连接系统的终端数
【load average: 0.07, 0.02, 0.00 】:系统负载;后面的三个数分别是1分钟、5分钟、15分钟的负载情况;如果平均负载值大于0.7*CPU内核数,就需要引起关注
第二行:
【Tasks: 273 total】:总进程数
【1 running】:正在运行的进程数
【272 sleeping】:正在睡眠的进程数
【0 stopped】:停止的进程数
【0 zombie】:僵尸进程数
第三行:
表示CPU状态信息;这里显示数据是所有CPU的平均值,如果想看每一个CPU的处理情况,按1即可;折叠,再次按1;
【 0.3%us】:用户空间占用CPU百分比
【0.7%sy】:内核空间占用CPU百分比
【0.0%ni】:用户进程空间内改变过优先级的进程占用CPU百分比
【98.3%id】:CPU空闲率
【0.0%wa】:等待IO的CPU时间百分比
【0.0%hi】:硬中断(Hardware IRQ)占用CPU的百分比
【 0.3%si】:软中断(Software Interrupts)占用CPU的百分比
【0.3%st】:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的);
第四行;物理内存使用信息;
3922452k total:物理内存总量;
142960k free:使用的物理内存总量;
3779492k used:空闲内存总量;
806428k buff/cache:用作内核缓冲/缓存的内存量;
第五行;交换空间使用信息;我们要时刻监控交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了;
3145724k total:交换区总量;
2865224k free:交换区空闲量;
280500k used:交换区使用量;
1511112k avail Mem:可用于进程下一次分配的物理内存数量;
第六行;空行;
第七行;各个进程的状态信息;
PID:进程id;
USER:进程所有者;
PR:进程优先级;
NI:nice值;越小优先级越高,最小-20,最大20(用户设置最大19);
VIRT:进程使用的虚拟内存总量,单位kb;VIRT=SWAP+RES;
RES:进程使用的、未被换出的物理内存大小,单位kb;RES=CODE+DATA;
SHR:共享内存大小,单位kb;
S:进程状态;D=不可中断的睡眠状态、R=运行、S=睡眠、T=跟踪/停止、Z=僵尸进程;
%CPU:上次更新到现在的CPU时间占用百分比;
%MEM:进程使用的物理内存百分比;
TIME+:进程使用的CPU时间总计;
COMMAND命令名/命令行。
1.1.2 常见使用
-
top -c // 每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名)。也可以先输入top命令,然后输入c
-
top -p 1534 -p 21 每隔5秒显示pid是1534和21是6789的两个进程的资源占用情况
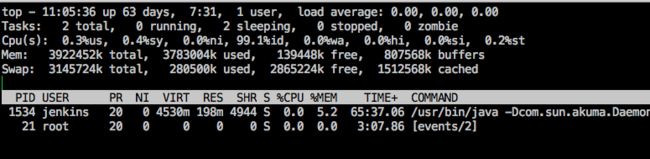
3 top -d 2 -c -p 1534 // 每隔2秒显示pid是1534的进程的资源使用情况,并显式该进程启动的命令行参数
4 进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的。但是,我们可以改变这种排序:
M:根据驻留内存大小进行排序
P:根据CPU使用百分比大小进行排序
T:根据时间/累计时间进行排序
5 切换到线程模式
H:切换到线程模式
1.1.3 详细top命令文档
http://man7.org/linux/man-pages/man1/top.1.html
2 Memory
2.1 free
free -g
total used free shared buffers cached
Mem: 3 3 0 0 0 1
-/+ buffers/cache: 1 2
Swap: 2 0 2
内存真正的剩余大小是-/+ buffers/cache这一列中的free。
2.2 命令详解
http://man7.org/linux/man-pages/man1/free.1.html
2.2 vmstat
vmstat -S M 1 以M显示,同时1s刷新一次
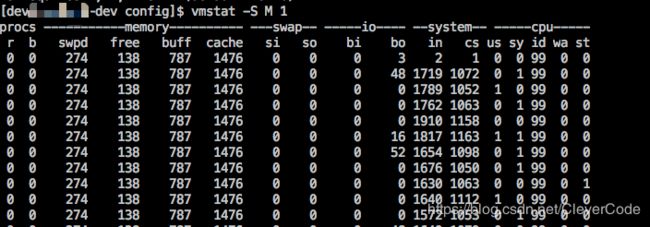
http://man7.org/linux/man-pages/man8/vmstat.8.html
3 IO
3.1 df
df -h 显示磁盘剩余容量

df -i 显示磁盘的inode情况

3.2 iostat
1、iostat,结果为从系统开机到当前执行时刻的统计信息

输出含义:
avg-cpu: 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值。重点关注iowait值,表示CPU用于等待io请求的完成时间。
Device: 各磁盘设备的IO统计信息。各列含义如下:
Device: 以sdX形式显示的设备名称
tps: 每秒进程下发的IO读、写请求数量
KB_read/s: 每秒从驱动器读入的数据量,单位为K。
KB_wrtn/s: 每秒从驱动器写入的数据量,单位为K。
KB_read: 读入数据总量,单位为K。
KB_wrtn: 写入数据总量,单位为K。
2、iostat -x -k -d 1 2。每隔1S输出磁盘IO的详细详细,总共采样2次。

以上各列的含义如下:
rrqm/s: 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并
wrqm/s: 每秒对该设备的写请求被合并次数
r/s: 每秒完成的读次数
w/s: 每秒完成的写次数
rkB/s: 每秒读数据量(kB为单位)
wkB/s: 每秒写数据量(kB为单位)
avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
avgqu-sz: 平均等待处理的IO请求队列长度
await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
svctm: 平均每次IO请求的处理时间(毫秒为单位)
%util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率
3 重点关注指标
1、iowait% 表示CPU等待IO时间占整个CPU周期的百分比,如果iowait值超过50%,或者明显大于%system、%user以及%idle,表示IO可能存在问题。
2、avgqu-sz 表示磁盘IO队列长度,即IO等待个数。
3、await 表示每次IO请求等待时间,包括等待时间和处理时间
4、svctm 表示每次IO请求处理的时间
5、%util 表示磁盘忙碌情况,一般该值超过80%表示该磁盘可能处于繁忙状态。
4 Network
4.1 dstat
dstat 是一个可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些另外的功能,增加了监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。
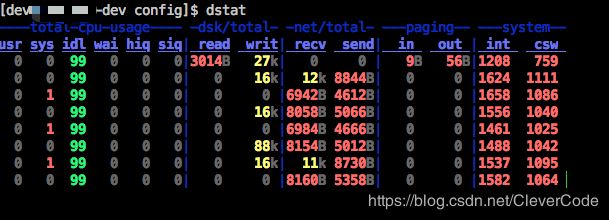
CPU状态:CPU的使用率。这项报告更有趣的部分是显示了用户,系统和空闲部分,这更好地分析了CPU当前的使用状况。如果你看到"wait"一栏中,CPU的状态是一个高使用率值,那说明系统存在一些其它问题。当CPU的状态处在"waits"时,那是因为它正在等待I/O设备(例如内存,磁盘或者网络)的响应而且还没有收到。
磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,或者说内存非常分散,大多数情况下你都希望看到page in(换入)和page out(换出)的值是0 0。
系统统计:这一项显示的是中断(int)和上下文切换(csw)。这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。你的服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。