[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
论文题目:Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
作者信息:Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel, Linxi Fan, Christopher Fougner, Tony Han, Awni Hannun, Billy Jun, Patrick LeGresley, Libby Lin, Sharan Narang, Andrew Ng, Sherjil Ozair, Ryan Prenger, Jonathan Raiman, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Yi Wang, Zhiqian Wang, Chong Wang, Bo Xiao, Dani Yogatama, Jun Zhan, Zhenyao Zhu
所属机构:Baidu Research – Silicon Valley AI Lab
论文链接:https://arxiv.org/pdf/1512.02595.pdf
目录
1. 摘要
2. 模型结构
3. 优化工作
4. 实验结果
1. 摘要
这篇论文是在2015年由Baidu AI Lab所发布的,依旧延续了上一篇论文的路线:抛弃复杂的传统框架,拥抱基于神经网络的端到端模型。这篇论文有三个亮点:1. 作者这次所训练的模型既识别英文语音,也识别中文(普通话)语音。 2. 作者利用 HPC 技术(High-performance Computing,即高性能计算),使得整个系统性能有了大幅的提高(得利于此,模型训练速度大幅提升,也引出了第三点)。3. 作者在 Deep Speech 的基础上做了大量修改与尝试:加深了网络深度,尝试了 (Bi-directional) Vanilla RNN 和 GRU,引进了1D/2D invariant convolution,引入 Batch Nomalization。
2. 模型结构
照例我们来看看声学模型部分:
model input : spectrogram of power normalized audio clips as the features ,功率归一化音频剪辑的频谱图
model output : 1. English: English character or blank symbol 2.Mandarin: simplified Chinese characters
loss function : CTC loss,
Author: 'We report Word Error Rate (WER) for the English system and Character Error Rate (CER) for the Mandarin system’
这个模型由三部分组成:Conv layer, Recurrent layer and FC layer。
首先是 Conv layer:
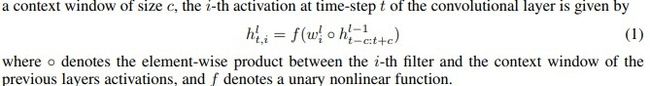
其次是 Recurrent layer:
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第1张图片](http://img.e-com-net.com/image/info8/6da981ce98e04dde8ec23d0391ac5d99.jpg)
最后是 FC layer:
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第2张图片](http://img.e-com-net.com/image/info8/39fc31beb78845719a7d0e94e8bce016.jpg)
此外,作者还在模型中引入了 Batch Normalization,使得模型训练更快,且训练得更好。
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第3张图片](http://img.e-com-net.com/image/info8/091011982e864ec486b24b50841f22ca.jpg)
3. 优化工作
1. 数据并行化
作者提到论文中使用标准的数据并行性的算法,使得模型得以在多个GPU上同步训练(使用了 synchronous SGD)。
2. CTC loss function的GPU实现
由于计算CTC loss function 比前后向传播更为复杂,作者实现了一个GPU版本的CTC loss function,而这一实现,减少了10%~20%的训练时间。
3. 内存分配优化
作者在论文中提到:'Our system makes frequent use of dynamic memory allocations to GPU and CPU memory, mainly to store activation data for variable length utterances, and for intermediate results. '。
4. 实验结果
English:
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第4张图片](http://img.e-com-net.com/image/info8/2630b83dab5742ce9da9983029f40563.jpg)
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第5张图片](http://img.e-com-net.com/image/info8/b1ef94efec0b4a098cdcfbc249e57c67.jpg)
Mandarin:
![[论文笔记] Deep Speech 2: End-to-End Speech Recognition in English and Mandarin_第6张图片](http://img.e-com-net.com/image/info8/676634c7cc654660ab762005877d9cd7.jpg)
参考资料:
- Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin论文笔记
如果你看到了这篇文章的最后,并且觉得有帮助的话,麻烦你花几秒钟时间点个赞,或者受累在评论中指出我的错误。谢谢!
作者信息:
LeetCode:Tao Pu
CSDN:Code_Mart
Github:Bojack-want-drink