编译原理实验一:为PL/0语言编写一个词法分析程序
思路:利用词法分析一章所讲的状态转化图方法,输入源程序,输出单词符号(token)串
1.单词符号类
package lexical_analyzer;
public class Token {
private String SYM;// 单词类别
private String ID;// 标识符的名字
private String NUM;// 用户定义的数
public Token(String sym, String id, String num) {
this.SYM = sym;
this.ID = id;
this.NUM = num;
}
public String getSYM() {
return SYM;
}
public String getID() {
return ID;
}
public String getNUM() {
return NUM;
}
@Override
public String toString() {
return "<" + this.SYM + "," + this.ID + "," + this.NUM + ">";
}
}
2.词法分析类LexicalAnalyzer
package lexical_analyzer;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
public class LexicalAnalyzer {
private StringBuffer sourceCode;// 源代码
private int pos;// 字符位置
public static ArrayList
private ArrayList
static { //所有关键字
remain.add("const");
remain.add("CONST");
remain.add("var");
remain.add("VAR");
remain.add("procedure");
remain.add("begin");
remain.add("end");
remain.add("if");
remain.add("then");
remain.add("call");
remain.add("while");
remain.add("do");
remain.add("read");
remain.add("write");
remain.add("ood");
}
public LexicalAnalyzer(StringBuffer buffer) {
this.sourceCode = buffer;
this.pos = 0;
filterBlank();
System.out.println("源代码:\n"+this.sourceCode);
}
// 滤掉单词间的空格
private void filterBlank() {
for (int i = 0; i < this.sourceCode.length(); i++) {
if (this.sourceCode.charAt(i) == ' ') {
this.sourceCode.deleteCharAt(i);
i--;
}
}
}
// 从处理过的输入源代码中获取一个字符
private char GetChar() {
if (this.sourceCode != null && pos < this.sourceCode.length()) {
return this.sourceCode.charAt(pos++);
}
return ' ';
}
// 当超前分析读出的不是所需的字符时回退一个pos
private void backPos() {
pos--;
}
// 判断一个字符是否是数字
private boolean IsDigit(char ch) {
if (ch == '0' || ch == '1' || ch == '2' || ch == '3' || ch == '4'
|| ch == '5' || ch == '6' || ch == '7' || ch == '8'
|| ch == '9')
return true;
return false;
}
// 判断一个字符是否是字母
private boolean IsLetter(char ch) {
// if(ch=='a'||ch=='b'||ch=='c'||ch=='d'||ch='e'||ch=='f'||ch=='g'||ch=='h'||ch=='i'||ch=='j'||ch=='k'||ch=='l'||ch=='m'||ch=='n'||ch=='o'||ch=='p'||)
if (ch >= 97 && ch <= 122)
return true;
return false;
}
// 词法分析主程序
// public void GetSYM() {
public ArrayList
char ch;// 当前获取的字符
boolean finded;// 是否已匹配成功界符或运算符
// ch = this.GetChar();
System.out.println("***************************************************************");
System.out.println("词法分析");
System.out.println("***************************************************************");
System.out.println("SYM\t\tID\t\tNUM");// 输出格式
while ((ch = this.GetChar()) != ' ') {
System.out.println("----------------------------------");
finded = false;
switch (ch) {
// 判断是不是界符
case ';':
finded = true;
System.out.println("SYM_;\t\t \t\t ");
wordToken.add(new Token(";", null, null));
break;
case ',':
finded = true;
System.out.println("SYM_,\t\t \t\t ");
wordToken.add(new Token(",", null, null));
break;
case '(':
finded = true;
System.out.println("SYM_(\t\t \t\t ");
wordToken.add(new Token("(", null, null));
break;
case ')':
finded = true;
System.out.println("SYM_)\t\t \t\t ");
wordToken.add(new Token(")", null, null));
break;
// 判断是不是运算符
case '+':
finded = true;
System.out.println("SYM_+\t\t \t\t ");
wordToken.add(new Token("+", null, null));
break;
case '-':
finded = true;
System.out.println("SYM_-\t\t \t\t ");
wordToken.add(new Token("-", null, null));
break;
case '*':
finded = true;
System.out.println("SYM_*\t\t \t\t ");
wordToken.add(new Token("*", null, null));
break;
case '/':
finded = true;
System.out.println("SYM_/\t\t \t\t ");
wordToken.add(new Token("/", null, null));
break;
case '=':
finded = true;
System.out.println("SYM_=\t\t \t\t ");
wordToken.add(new Token("=", null, null));
break;
case '#':
finded = true;
System.out.println("SYM_#\t\t \t\t ");
wordToken.add(new Token("#", null, null));
break;
case '<': {
finded = true;
ch = this.GetChar();
if (ch == '=') {
System.out.println("SYM_<=\t\t \t\t ");
wordToken.add(new Token("<=", null, null));
} else {
this.backPos();
System.out.println("SYM_<\t\t \t\t ");
wordToken.add(new Token("<", null, null));
}
}
break;
case '>': {
finded = true;
ch = this.GetChar();
if (ch == '=') {
System.out.println("SYM_>=\t\t \t\t ");
wordToken.add(new Token(">=", null, null));
} else {
this.backPos();
System.out.println("SYM_>\t\t \t\t ");
wordToken.add(new Token(">", null, null));
}
}
break;
}
// 如果上面已匹配成功
if (finded == true) {
continue;
}
// 判断是否是常量
if (IsDigit(ch)) {
// 获取整个常量
StringBuffer number = new StringBuffer();
number.append(ch);
while (IsDigit(ch = this.GetChar())) {
number.append(ch);
}
this.backPos();
System.out.println("NUMBER\t\t \t\t" + number);
wordToken.add(new Token("NUMBER", null, number.toString()));
}
// 判断是否是标识符或保留字
else if (IsLetter(ch)) {
// 标记是否是保留字
boolean isRemain = false;
// 标记一个字符后是否是end
boolean is_End = false;
// 获取整个
StringBuffer str = new StringBuffer();
str.append(ch);
while (IsLetter(ch = this.GetChar()) || IsDigit(ch)) {
// 判断当前字符后面是否是end
if (ch == 'e') {
String isEnd = "e";
char isN = this.GetChar();
char isD = this.GetChar();
isEnd = isEnd + isN + isD;
if (isEnd.equals("end")) {
// 输出end前面的内容
if (remain.contains(str.toString())) {
// 是保留字
// isRemain = true;
System.out.println(str.toString().toUpperCase()
+ "SYM" + "\t\t \t\t ");
wordToken.add(new Token(str.toString()
.toUpperCase() + "SYM", null, null));
} else {
System.out.println("IDENT\t\t" + str.toString()
+ "\t\t ");
wordToken.add(new Token("IDENT",
str.toString(), null));
}
this.backPos();
this.backPos();
this.backPos();
is_End = true;
break;
} else {
this.backPos();
this.backPos();
}
}
str.append(ch);
if (remain.contains(str.toString())) {
// 是保留字
isRemain = true;
System.out.println(str.toString().toUpperCase() + "SYM"
+ "\t\t \t\t ");
wordToken.add(new Token(str.toString().toUpperCase()
+ "SYM", null, null));
break;
}
}
if (is_End == true) {
continue;
}
if (isRemain == false&&this.pos<=this.sourceCode.length()) {
// 不是保留字是标识符,多读了一个字符,归还
this.backPos();
System.out.println("IDENT\t\t" + str.toString() + "\t\t ");
wordToken.add(new Token("IDENT", str.toString(), null));
}
} else {
// 错误处理
}
}
return wordToken;
}
// 主程序
/*public static void main(String[] args) {
String path = "/home/1.txt";
StringBuffer source = readFile(path);
LexicalAnalyzer analyer = new LexicalAnalyzer(source);
ArrayList
System.err.println("list length="+list.size());
System.out.println(list.get(20));
}
*/
// 从源码文件读入源代码
public static StringBuffer readFile(String path) {
File sfile = new File(path);
if (sfile.exists()) {
StringBuffer buffer = new StringBuffer();
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(sfile));
String temp = null;
while ((temp = reader.readLine()) != null) {
buffer.append(temp);
}
reader.close();
return buffer;
// System.out.println("file:\n"+buffer);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
return null;
}
}
3.运行示例:
源码:
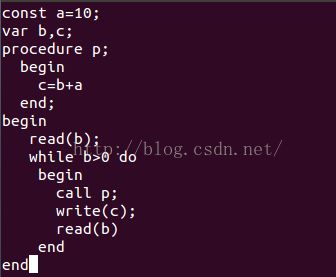
输出:

