CUDA8.0安装配置 for VS2013
1. 下载并安装CUDA8.0:
官网下载地址:https://developer.nvidia.com/cuda-downloads
2. 配置环境变量:
在系统环境变量中添加如下项目/键值:
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\x64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64并在系统变量PATH中添加:
;%CUDA_LIB_PATH%;%CUDA_BIN_PATH%;%CUDA_SDK_LIB_PATH%;%CUDA_SDK_BIN_PATH%;重启电脑即可。
检验CUDA环境是否配置成功:
A.打开cmd窗口,输入:nvcc -V,屏幕上会显示nvcc编译器的版本信息。
B.打开cmd窗口,输入:
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\extras\demo_suite
bandwidthTest.exe
deviceQuery.exe

如果两者都是:Rsult=PASS,说明安装和配置成功啦;否则可能需要重装。
C.编译CUDA的Samples:
用VS2013打开:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\Samples_vs2013.sln

可以右键“Samples_vs2013”解决方案(共155个方案)->重新生成解决方案(编译的时间会非常漫长);
也可以右键“1_Utilities”->重新生成(只编译一部分,会比较快)。
建议用Release模式编译,速度比Debug快。
编译结束后,进入C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\bin\win64\Release会发现我们刚编译出的bandwidthTest.exe和deviceQuery.exe,在cmd窗口中运行,结果应与上面相同。
如果编译过程中,未找到CUDA 8.0.props,会出现如下提示:

将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\extras\visual_studio_integration\MSBuildExtensions\目录下的4个文件,复制到C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V120\BuildCustomizations目录下,然后重新启动VS2013即可。
3. VS2013中配置CUDA:
A. 打开VS2013,建立一个win32控制台空项目:
B. 右键工程->生成依赖项->生成自定义;并勾选“CUDA 8.0”。


C. 右键工程->属性->配置管理器->活动解决方案平台->新建->键入或选择新平台->选择“x64”。

D. 菜单->视图->其他窗口->属性管理器:
这里只配置Release的x64版本(因为下载的是x64版,Win32的配置方法类似)。

在 VC++目录->包含目录 填入:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\inc在 VC++目录->库目录 填入:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\common\lib\x64在 链接器->输入->附加依赖项 填入:
cublas.lib
cublas_device.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusparse.lib
nppc.lib
nppi.lib
nppial.lib
nppicc.lib
nppicom.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvcuvid.lib
nvgraph.lib
nvml.lib
nvrtc.lib
OpenCL.lib
cudnn.lib(选填,当安装cudnn时)PS:对于OpenCV,建议不要同时配置Release版和Debug版,可能会有冲突。
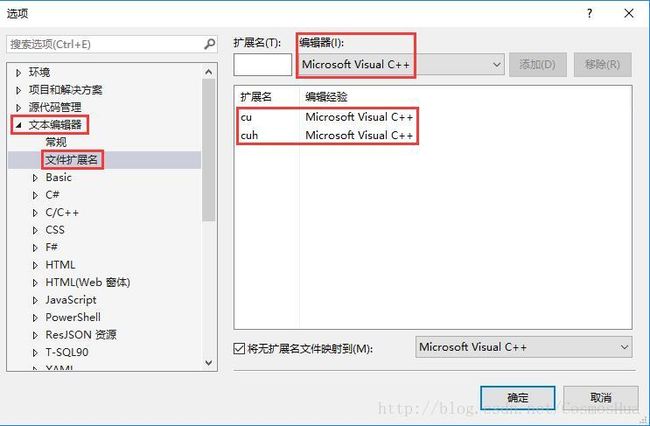
E. 菜单->工具->选项->文本编辑器->文件扩展名->添加cu和cuh两个文件扩展名,并采用C++编辑器。
这个设置是让VS2013编辑.cu文件时,把.cu文件里的C/C++语法高亮。(输入扩展名cu和cuh,点击“添加”按钮即可)
PS(显示行号):菜单->工具->选项->文本编辑器->所有语言->常规,勾选“行号”即可。
至此,CUDA的编译环境就搭建完成了。
4. 测试样例:
A. 右键源文件->添加->新建项,选择C++文件,将后缀cpp改为cu即可。

B. 右键.cu文件->属性->项类型,勾选“CUDA C/C++”。

C. 编辑测试用的.cu文件:
// CUDA runtime 库 + CUBLAS 库
#include "cuda_runtime.h"
#include "cublas_v2.h"
#include
#include
using namespace std;
// 定义测试矩阵的维度
const int M = 5;
const int N = 10;
int main()
{
// 定义状态变量
cublasStatus_t status;
// 在 内存 中为将要计算的矩阵开辟空间
float *h_A = (float*)malloc(N*M*sizeof(float));
float *h_B = (float*)malloc(N*M*sizeof(float));
// 在 内存 中为将要存放运算结果的矩阵开辟空间
float *h_C = (float*)malloc(M*M*sizeof(float));
// 为待运算矩阵的元素赋予 0-10 范围内的随机数
for (int i = 0; i < N*M; i++)
{
h_A[i] = (float)(rand() % 10 + 1);
h_B[i] = (float)(rand() % 10 + 1);
}
// 打印待测试的矩阵
cout << "矩阵 A :" << endl;
for (int i = 0; i < N*M; i++)
{
cout << h_A[i] << " ";
if ((i + 1) % N == 0) cout << endl;
}
cout << endl;
cout << "矩阵 B :" << endl;
for (int i = 0; i < N*M; i++)
{
cout << h_B[i] << " ";
if ((i + 1) % M == 0) cout << endl;
}
cout << endl;
//GPU 计算矩阵相乘:
// 创建并初始化 CUBLAS 库对象
cublasHandle_t handle;
status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS)
{
if (status == CUBLAS_STATUS_NOT_INITIALIZED) {
cout << "CUBLAS 对象实例化出错" << endl;
}
getchar();
return EXIT_FAILURE;
}
float *d_A, *d_B, *d_C;
// 在 显存 中为将要计算的矩阵开辟空间
cudaMalloc((void**)&d_A, //指向开辟的空间的指针
N*M*sizeof(float)); //需要开辟空间的字节数
cudaMalloc((void**)&d_B, N*M*sizeof(float));
// 在 显存 中为将要存放运算结果的矩阵开辟空间
cudaMalloc((void**)&d_C, M*M*sizeof(float));
// 将矩阵数据传递进 显存 中已经开辟好了的空间
cublasSetVector(N*M, // 要存入显存的元素个数
sizeof(float), // 每个元素大小
h_A, // 主机端起始地址
1, // 连续元素之间的存储间隔
d_A, // GPU 端起始地址
1); // 连续元素之间的存储间隔
cublasSetVector(N*M, sizeof(float), h_B, 1, d_B, 1);
// 同步函数
cudaThreadSynchronize();
// 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。
float a = 1; float b = 0;
// 矩阵相乘。该函数必然将数组解析成列优先数组
cublasSgemm(handle, // blas 库对象
CUBLAS_OP_T, // 矩阵 A 属性参数
CUBLAS_OP_T, // 矩阵 B 属性参数
M, // A, C 的行数
M, // B, C 的列数
N, // A 的列数和 B 的行数
&a, // 运算式的 α 值
d_A, // A 在显存中的地址
N, // lda
d_B, // B 在显存中的地址
M, // ldb
&b, // 运算式的 β 值
d_C, // C 在显存中的地址(结果矩阵)
M); // ldc
// 同步函数
cudaThreadSynchronize();
// 从 显存 中取出运算结果至 内存中去
cublasGetVector(M*M, // 要取出元素的个数
sizeof(float), // 每个元素大小
d_C, // GPU 端起始地址
1, // 连续元素之间的存储间隔
h_C, // 主机端起始地址
1); // 连续元素之间的存储间隔
// 打印运算结果
cout << "计算结果的转置 ( (A*B)的转置 ):" << endl;
for (int i = 0; icout << h_C[i] << " ";
if ((i + 1) % M == 0) cout << endl;
}
// 清理掉使用过的内存
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放 CUBLAS 库对象
cublasDestroy(handle);
getchar();
return 0;
} 更详细的参见:http://blog.csdn.net/lvfeiya/article/details/53325784