晨瞎BB —— 论文之我见 —— Learning to see in the dark-CVPR 2018
1. 摘要
目前的话,低光条件下面的摄影的话,主要的图片的质量效果都不是很好的,一般的话我们使用的解决方法有两种:一种方法是使用长时间曝光,通过延长曝光时间从而使得系统能够吸收到更多的光线,从而拍摄到清晰的照片;另外的一种方法是使用提高拍摄时候的系统的感光度(ISO)数值从而实现获得更加清晰的图像的功能。其实还有第三种方法,不过只是在摄影过程中,是使用更大光圈值的光学镜头来进行拍摄。总的来说的话,基本的方法是使得整个系统接收到的光线更多,从而实现弱光环境下获得较好的图像效果。
这里面的话,各种解决方法都有各自的局限性:
使用长时间曝光的问题在于,我们没有办法对于动态的物体进行捕捉,会导致画面的模糊。
使用提高系统感光度的方法:这一种方法对于感光的元器件的要求非常的高。一般来说,能够支持很高iso的设备价格非常昂贵,而且体积都不小,仅仅是特定摄影器材。而且在非常高的iso的情况下,再好的感光元件的图像都是含有非常多不规则的热噪声。
使用更大光圈的光学镜头进行拍摄的话,同样存在着价格昂贵,不具有普适性的问题。
这篇论文采用的方法是另外一种方法,其实有一些想法和陈老师目前的实现方法有一些类似。这里面的话是设计了一组相互对应的短曝光时长的低光照图片集和长曝光时长的图片。
这个里面的话,通过构建一个端到端的全卷积网络来进行直接对于从传感器读取出来的RAW数据直接进行处理,从而替代了之前的传统图像处理流水线的相关工作。在这个数据集的帮助下,实现了比较好的效果。
2. 介绍
在低光照的情况下,图像系统的噪声的影响对于整个图像系统的成像效果影响非常大。一般的话,我们如果使用高的ISO感光度进行成像的话,的确可以提高整体的亮度水平,但是同时也会引入大量的噪声。虽然可以通过很多预处理操作来进行预先处理尝试改善图像的质量,但是因为其中的光线实在是太少了,这个的话没有办法解决图像的信噪比低的现实。
也有很多的方法可以提高低光线情况下整体画面的信噪比,这里面的话是可以用使用更大的光圈,延长曝光时间或者是使用闪光灯。但是这些方法的话各自都有对应的局限性。
这里有一个快速成像(fast imaging)的概念,这里的话我的理解就是对于一些实时性要求高的成像环节,比如说对于视频的捕获的话就是需要有一个比较快速的成像环节。
快速成像(fast imaging)这里的话,在计算摄影社区中具有比较多的讨论,这里面的话主要有采用去噪、去模糊和低光线图像的相关增强方法。这些方法可能实现也是不错的,但是在实现的过程中,对于本身捕获的图像是有一定要求的,这里面的话需要捕获的图像在暗光条件下是具有一定特定级别的噪声(噪声不能过大)。
这里的话,这篇论文主要需要实现一种比这些传统方法适用范围更广的场景,这里的话希望实现在极端低照明度环境下,同时曝光时间也很短的情况下实现较好的成像效果。为了达到这种效果,传统的相机处理方法就失效了,需要我们通过对于原始图像输出RAW数据进行重建实现。
这里的话,对于低照度图像的处理过程中,行业内对于几个小的方面已经做了一些研究:
1、首先的一个部分就是对于图像降噪进行了研究。对于经典方法(非数据驱动型深度学习方法)来说,有一个深度网络去噪方法比如系数降燥自动编码器、TNRD方法和卷积神经网络,在特定噪声级别的图像上有比较好的处理效果。但是的话,目前现有的方法是在类似ground-truth图像人工加入高斯或者椒盐噪声后实现的。
最近有一个评价体系中,BM3D这种非数据驱动型的传统方法反而做到了很好的效果,甚至是比数据驱动型方法做得更好。
2、低光照图像增强:这里面的话对于低光照图像的话,传统方法是直方图均衡化的方法,这种方法通过平衡了整个直方图的分布来提高了整体的画面质量;还有一种方法是伽马修正。这个方法是通过提升画面中的暗部区域的亮度,同时压缩了亮的像素;目前来看最先进的方法还有使用更多的全局分析方法进行处理。比如:反向黑通道优先法,小波变化法,Retinex模型和明亮度映射估计法。
3、噪声图像数据集:绝大多数的现有的方法是使用人工合成的数据进行测试评价的,比如说在干净的图片之上人工添加高斯噪声或者是椒盐噪声。
除了这些绝大多数的数据集以外,还有很多想要尝试构建成良好的数据集的,但是没有达成比较好的效果。
RENOIR数据集原先的话是希望变成一个基于实际噪声图像的评价数据集,但是的话,RENOIR数据集中间的数据不够可靠,也存在数据标注错误的问题。
谷歌HDR+数据集的话,并没有针对于极端的低光照情况,大多数的数据集之中的图像主要是在白天拍摄的。
还有一个DND数据集的话,本身是为了解决去噪社区对于真实噪声图片的需求,但是很多的图片也是在白天拍摄的,不适合对于低光照情况下进行参考。
3. 相关工作
这篇论文的话,我觉得可能能够入选CVPR的主要因为做出了两个贡献:1、这篇文章的作者自己构建了两组低光照条件下的数据集,这个之前的话都没有人去做,算是一个比较大的成果;2、这个里面直接绕过了传统相机对于感光原始数据的处理流水线,而是使用了自己的方法进行处理。
4. 特殊贡献SID数据集
这个数据集是我阅读了这篇文章以后觉得作者做的可能是最大的一个贡献了。传统的方法处理低光照图像效果没有想象中好的很多的一个原因是,使用的ground truth的图像是人工制作出来的,而不是真实现状的低光照片的。这里的话作者自己收集了一整套新的原始图像数据集RAW data,这里面的每一个低光照图片都有一个对应的长曝光高质量的参考图片与之一一对应。
这里面的话整个数据集的采集都是相对来说采用最为规范的方式进行采集的,这个工作的工作量是非常大的。但是对于最后的实现效果来说,还是值得的。
这里的话高质量的图片主要采用的是延长曝光时间的方法,这里的话就需要要求保证环境的足够稳定。文章中采用了各种措施保证了拍摄时候的稳定性。对应的低质量图片采用的是长曝光时间的1/100-1/300进行拍摄的。
这里的话他们还为了适用性更强,采用了两种不同的cmos传感器结构形式进行采集了两种数据集,从而增强了整个系统的普适性。
这里面的话是高清晰度的图像也不是完美的,这里面的高清晰度图像仍然存在着噪声。文章中写的是为了还原,个人觉得只是留了一些提升空间。
5. 实现方法
5.1 图像处理的流水线

这里的话,如果要做图像处理的话我们需要用图像传感器直接获取到原始的RAW数据。这里的话传统的详细处理过程是先要进行白平衡等操作,其中的话做了这些操作后效果并不一定好,而且这种图像处理流水线的方法主要只是适合于特定一种相机进行调校的,没有普适性。
除此以外,还有一种方法:L3方法,通过使用复杂的非线性滤波器对于得到的原始数据进行处理,从而估计实际的图像应该是什么样子。(这个方法时间不够,后面如果需要可以找一下对应的论文研究一下)。
这两种方法的局限性在于无法做到满足快速成像fast-imaging的要求,同时对于低信噪比图像也不能进行处理。
还有一种Hasinoff方法是使用智能手机相机瞬间拍摄对张照片,然后通过把图像进行对其融合后,得到一张效果比较好的照片(比较像iPhone的成像过程)。这个方法可能目前做的的确不错,但是因为要对于一大批的图片进行处理,这里面的话就不是很容易去做密集的图片处理评估过程,也不适合拓展到视频拍摄的处理中。
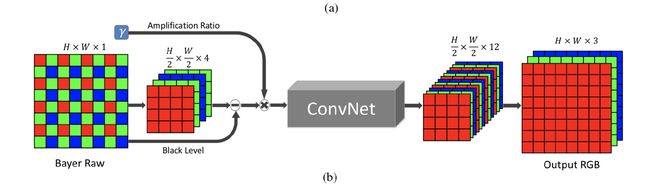
由于这篇文章对于实时性的要求比较高,所以最好能够使得整个系统的结构越简单越好。这里面的话直接采用端到端的学习方式直接对于图像进行处理。这里面的话我们主要是通过训练一个全卷积网络FCN。这里FCN不对于SRGB图像进行处理,反而是直接对于从相机传感器传送来的原始数据进行处理。
这里面的话由于相机的传感器阵列排列的方式不同,对于不同的传感器采用了不同的方法把获取的各个通道的数据分别提取出来,然后对于空间分辨率都进行了压缩,长和宽都变成了原来的一半,这样子的话可以减轻处理的压力。
这里的话,我们把图像的黑色登记同时把数据衡量成了特定的放大倍数,这些包装好的数据和放大了的数据被输入进入了一个全卷积网络,这个网络的输出是一个12通道的半分辨率的数据,这个长、宽各一半分辨率的输出通过一个亚像素层之后可以恢复出来一个原始的分辨率。
这里面的话主要使用的一种全卷积网络的结构是U-net结构。这个任务中原来备选的还有一个CAN(多尺度上下文聚类网络),后来因为在区分了各个色彩通道之后,整个CAN网络失去了之前的优势。同时由于性能的限制,CAN网络需要使用的资源过多,从而转向了使用U-net网络。
这篇文章篇幅没有怎么介绍如何设计的U-net网络,可能也算是一个论文的写作技巧吧。主要的创新点其实在于之前对于这一领域的话没有过这样子的想法。(这样看看的话CVPR好像的确也是稍微有一点点水TAT)
5.2 如何训练
这里的话,训练的时候也使用了一些技巧。主要训练时候才用了 L 1 L_1 L1的损失函数,同时还使用了Adam优化器。在训练的过程之中,网络的输入是短曝光时间的差质量照片,而对应的ground-truth是SRGB色彩空间的长曝光图像(这里的话采用libraw进行处理)。这里面的话,为了减少训练时间,随机选取 512 ∗ 512 512*512 512∗512的小块进行训练,同时通过应用了随机翻转和旋转进行了数据增广操作。这里的话,学习率learning rate首先设置 1 0 − 4 10^{-4} 10−4,其次变成了 1 0 − 5 10^{-5} 10−5。
6. 实验
6.1 与传统方法比较:


通过图像直接人眼进行对比的话,在整体看上去完全就是像两种光照条件下拍摄出来的图。人眼可见差别。
6.2 与优秀的去噪算法和Burst Processing方法比较
这里的话,和去噪算法比较,采用的是传统方法中甚至有的时候可以超过深度学习方法的BM3D方法进行对比。

对于BM3D算法来说,在小的噪声级别的情况下,可能会在画面中留下可见的典型噪声。或者是有区域过度光滑。而在文章中的方法里面我们看不到这些很严重的问题。
这里的话如果和Burst Processing方法进行比较的话,这里的话,因为整个数据集的数据是经过了对齐的,BM3D的效果还是不错的。这篇文章采用了盲选众包的方法进行了对比,
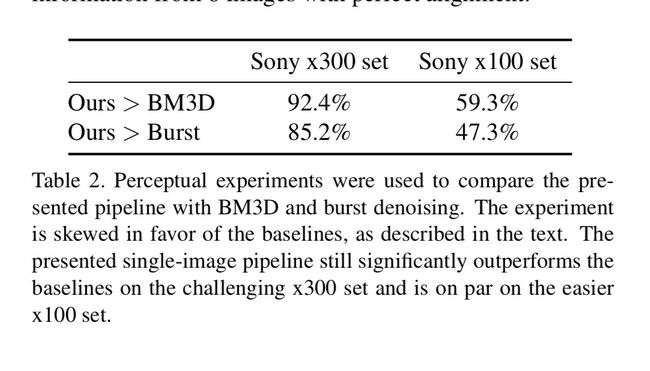
这基本上是唯一几个没有明显超越的方法了。但是对于整个系统的普适性来说,那肯定还是文章的算法更好一些。(强行胜利hhh)
6.3 文章算法的普适性
这里的话,我们使用iPhone 6S进行测试。这里的话因为采用原来的网络并且仅仅使用相同结构的传感器进行训练。这里的话我们采用索尼相机训练得到的网络应用在iPhone的RAW数据上面,同时也得到了非常大的优势。证明整个系统可以使用的范围非常的广泛,这个算法还是挺厉害的。
6.4 受控实验
这里的话主要就是在之前的选择算法和对应神经网络参数,相关损失函数的时候做的几个定量PSNR和SSIM测试。
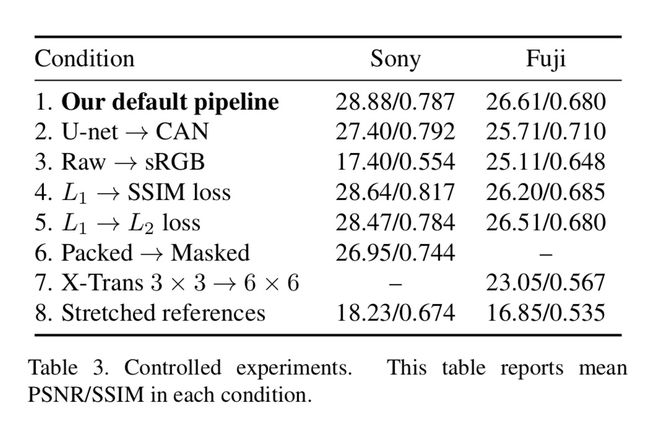
通过了这些的测试之后,我们可以看到最后是通过了实验以后确定了最终的方案。
6.4.1 网络结构对比实验
这个时候我们保持其他变量不变,仅仅是比较CAN网络结构和U-net网络结构的成像效果哪一个更好。从对比的图片中可以看到U-net的肉眼效果明显要更好。

6.4.2 输入色彩空间对比实验
大多数现存的去噪声算法采用的是对于SRGB色彩空间的图像进行处理,但是这个文章中直接采用相机传感器原始数据,在低光照度的情况下,可以明显的达到更好的效果。
在上面的Table3里面有比较,从之前的29.99下降到了17.40,还是非常的明显的。
6.4.3 损失函数对比实验
这里面的话损失函数的话,通过使用了不同的损失函数 L 1 L_1 L1和 L 2 L_2 L2,SSIM之后,发现 L 1 L_1 L1损失函数还是要比其他损失函数好不少。
6.4.4 数据组织方式
根据表格3可以看出,明显还是X-Trans采用3*3,索尼采用Packed方式能够获得更好的结果。
6.5 总体评估

全面的对比之后可以看出来,我们的方法全面超越了其他方法的效果
7. 讨论
这篇文章算是在低光照的领域开辟了一种新的思维。快速低光照成像本身因为有很少的光线可以进入,图像的信噪比也不高,之前的方法总或多或少存在着问题。
这里的话,作者通过发布过See-in-the-Dark数据集,这个建立了一种可以尝试使用数据驱动型方法解决极端情况下图像处理方法。因为有了主要基于真实情况的SID数据集,从而使得数据驱动型(机器学习)方法可以适用于这种极端情况下的图像处理。
课题组的话认为这个项目目前还没有处理HDR(高动态范围High Dymanic Range)色彩映射;SID数据库还不涉及人类和会移动物体;同时,后面的流水线过程中还有很多可以进行优化的空间。
目前的话,还有一个世纪的问题上,在当前的流水线工作的时候,有一个参数Amplification这个是内部设定的。最好未来可以从输入中引入一个恰当的放大倍数,以便应对图片是自动ISO情况(ISO不固定)。
我个人的观点和课题组的部分是类似的。我去找了一下Github上面的代码,整个代码跑下来的话对于硬件配置的要求还是非常大的。这个性能上还是有非常大的改进空间的。
但是这个的话,我个人的想法是:这个整个的思路是值得考虑的。如果要开始做深度学习加入应用的话,我们一定要去构建一个合适的,符合真实情况的数据集,单纯的好像使用图像增广的方法是具有局限性的,反而有可能做下来的效果没有以前的好。
还有一点是这篇论文的局限的地方:整篇论文的输入输出都必须要是RAW格式直接从传感器上读取出来的图像,但是对于我们的商用的摄像头来说,你往往是不会给你RAW的读取权限的,这个时候就非常的麻烦。目前看来这个RAW格式还绕不太开。
但是的话,这篇文章中使用到的BM3D算法,深度网络的U-Net结构目前看起来在知识部分我还有不少的欠缺,但是目前的话背景知识会缺少一些,这种时候我们就需要慢慢来补充一些基础知识。
这里的话,收获了一些论文人家常常使用的技巧。其实CVPR论文也不是可能大段的都是公式什么的,有的时候就是类似于一个好的idea,然后能够做出来好的效果就可以了。这个文章可能对于我个人的选择的话,参考意义不是特别的大,但是我觉得就当长一个见识吧。