求职知识整理二(Java基础知识)
二,Java的基础知识
1,jdk见上一篇文章path =%JAVA_HOME%\ bin java -version javac where java
2,javac.java java.class(类,主方法,运行参数,控制台输出)
3,蚀使用(工作区两种切换方式)(F3查看源代码,CTRL + Y反撤销,CTRL +移+ F格式化,CTRL + SHIFT + x / y的大小写转换,ALT + SHIFT + S快速打开资源界面r生产getter和setter方法; s生产toString方法; c无参构造器; o有参构造器)
额外:CTRL + SHIFT + C在铬浏览器中可直接打开开发者模式,并选中元素。
4,类:英雄;对象:new Hero();实例变量:Hero h = new Hero();实例化一个对象。
属性=“字段(成员变量);方法:类的动作行为;变量:用来命名一个数据的标识符。
字面值:给基本类型的变量赋值的方式
一个整数对应的二进制的方法:Integer.toBinaryString(K);
5,同名变量就近取值.public void method1(final int i){j = 7; } i = 7不可以执行,在调用方法的时候,我会赋值。
运算类型自动转换(除+ =类型的).i ++先取值,后运算; ++ i先运算,后取值。变量值在运算中值不会被初始化
6,&&与&(长路与),长路与两边都要运算。^异或,不同为真,同为假。 (运算符优先级)
7,读取字符串:new Scanner(System.in).nextLine();
需要注意的是,如果在通过nextInt()读取了整数后,再接着读取字符串,读出来的是回车换行: “\ r \ n” 个,因为nextInt仅仅读取数字信息,而不会读取回车换行 “\ r \ n”。
所以,如果在业务上需要读取了整数后,接着读取字符串,那么就应该连续执行两次nextLine(),第一次是取走回车换行,第二次才是读取真正的字符串
8,使用标签结束外部循环:outloop:for(){... break outloop; }
9、数组是一个固定长度的,包含了相同类型数据的 容器 集合可以是不同类型的数据,可变长度
1、数组与集合的区别
数组是相同类型数据的容器,固定长度
集合可以是不同类型的数据,可变长度
2、数组反转程序
int temp = 0;
for(int j=0;j temp=a[a.length-(j+1)]; a[a.length-(j+1)]= a[j]; a[j] =temp; } 3、选择法排序(把第一位和其他所有的进行比较,只要比第一位小的,就换到第一个位置来,比较完后,第一位就是最小的 //移动的位置是从0 逐渐增加的 //所以可以在外面套一层循环 for (int j = 0; j < a.length-1; j++) { for (int i = j+1; i < a.length; i++) { if(a[i] int temp = a[j]; a[j] = a[i]; a[i] = temp; } } } 4、冒泡法排序(第一步:从第一位开始,把相邻两位进行比较 ,如果发现前面的比后面的大,就把大的数据交换在后面,循环比较完毕后,最后一位就是最大的 //后边界在收缩 //所以可以在外面套一层循环 for (int j = 0; j < a.length; j++) { for (int i = 0; i < a.length-j-1; i++) { if(a[i]>a[i+1]){ int temp = a[i]; a[i] = a[i+1]; a[i+1] = temp; } } } 5、for循环???? //常规遍历 for (int i = 0; i < values.length; i++) { int each = values[i]; System.out.println(each); } 增强for循环(增强型for循环只能用来取值,却不能用来修改数组里的值) //增强型for循环遍历 for (int each : values) { System.out.println(each); } 6、一个二维数组,里面的每一个元素,都是一个一维数组 7、Arrays.copyOfRange(a,0,3);复制数组 Arrays.toString(a);转换为字符串 Arrays.sort(a);排序 Arrays.sort(a); Arrays.binarySearch(a,target); 二分搜索:查询元素出现的位置(相同元素,结果不定) 8、引用与内存***********************基本类型和包装类型的存储。????????? 数字转字符串: 9、一个引用同一时间,只能指向一个对象; 一个对象可以有多个引用 10、对封装,继承和多态的理解(面经书上有) 11、方法重载:overload,同类中,名同参不同(数量,顺序,类型) 方法重写/覆盖:override,父子类中。满足:三同一大一小(方法名、返回值类型、形参相同;访问权限>=重写前;抛出异常<=重写前) 见—接口文档 12、通过一个类创建一个对象,这个过程叫做实例化(实例化是通过调用构造方法实现的) 13、修饰符权限图 14、类属性:又叫做静态属性 对象属性: 又叫实例属性,非静态属性 访问类属性:两种方式: 对象.类属性 类名.类属性(建议使用这个) 类方法: 又叫做静态方法 对象方法: 又叫实例方法,非静态方法 15、对象属性初始化有3种 public String name = "some hero"; //声明该属性的时候初始化 { maxHP = 200; //初始化块} public Hero(){hp = 100; //构造方法中初始化 } 16、单例模式(在一个JVM里,只有一个实例存在) 饿汉式:无论如何都会创建一个实例 private static GiaDra instance=new GD(); 懒汉式:只有在调用getInstance的时候,才会创建实例 private static GiantDragon instance = null; 1. 构造方法私有化private GiantDragon(){ //私有化构造方法使得该类无法在外部通过new 进行实例化 2. 静态属性指向实例 private static GiantDragon instance; //一个类属性,用于指向一个实例化对象,暂指向null 3. public static的 getInstance方法,返回第二步的静态属性 //私有化构造方法使得该类无法在外部通过new 进行实例化 private GiantDragon(){ } //准备一个类属性,用于指向一个实例化对象,但是暂时指向null private static GiantDragon instance; //public static 方法,返回实例对象 public static GiantDragon getInstance(){ //第一次访问的时候,发现instance没有指向任何对象,这时实例化一个对象 if(null==instance){ instance = new GiantDragon(); } //返回 instance指向的对象 return instance; } 17、内部类四种 (在匿名类中使用外部的局部变量,外部的局部变量必须修饰为final 在jdk8中,已经不需要强制修饰成final了,如果没有写final,不会报错,因为编译器偷偷的帮你加上了看不见的final) 18、格式化输出: %s 表示字符串 %d 表示数字 %n 表示换行 \n\r换行回车 19、字符串转化为字符数组 char[] cs = str.toCharArray(); charAt(i);获取指定位置的字符 截取字符串(基于0的):sentence.substring(3)截取从第三个开始 substring(3,5) String subSentences[] = sentence.split(“,”); 根据,进行分割,得到3个字符串。 for(string sub : subSentences) syso(sub); sentence.trim();去除首尾空格 20、StringBuffer:可变长度的字符串 sb.append(“”);在最后追加 sb.delete(4,10);删除4-10之间的字符 sb.insert(4,”there ”);在4这个位置,插入there sb.reverse();字符串反转 为什么StringBuffer可以变长? 和String内部是一个字符数组一样,StringBuffer也维护了一个字符数组。 但是,这个字符数组,留有冗余长度 比如说new StringBuffer("the"),其内部的字符数组的长度,是19,而不是3,这样调用插入和追加,在现成的数组的基础上就可以完成了。 如果追加的长度超过了19,就会分配一个新的数组,长度比原来多一些,把原来的数据复制到新的数组中,看上去 数组长度就变长了 21、new Date()当前时间 getTime()得到一个long型的整数。 new Date().getTime(); => System.currentTimeMillis() 获得当前日期的毫秒数 22、字符串转日期:sdf.parse(str); 翻日历(见Java六) 23、异常处理: try{}catch{} 多异常:分别catch,统一catch try{}catch{}finally{} throws throws与throw这两个关键字接近,不过意义不一样,有如下区别: 1. throws 出现在方法声明上,而throw通常都出现在方法体内。 2. throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某个异常对象。 运行时异常: 都是RuntimeException的类及其子类异常,如空指针异常(空指针异常),IndexOutOfBoundsException异常(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。 运行时异常的特点是Java的编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用的try-catch语句捕获它,也没有用抛出子句声明抛出它,也会编译通过。 除数不能为零异常:ArithmeticException 下表越界异常:ArrayIndexOutOfBoundsException 空指针异常:NullPointerException 要么try catch,要么throws跑出去。 错误Error:系统级别的异常,通常是内存用光了。OutOfMemoryError,StackOverflowError AWTError Throwable是类,Exception和Error都继承了该类. Exception里又分运行时异常和可查异常。 24、序列化和反序列化。??????? 25、equals() == === hashCode()?????? 26、集合:add(),remove(),set()替换指定位置的元素, size()集合大小 排列无序,不可重复 排列有序,可重复 如何选择? 1、容器类和Array的区别、择取 * 容器类仅能持有对象引用(指向对象的指针),而不是将对象信息copy一份至数列某位置。 * 一旦将对象置入容器内,便损失了该对象的型别信息。 2、 * 在各种Lists中,最好的做法是以ArrayList作为缺省选择。当插入、删除频繁时,使用LinkedList(); Vector总是比ArrayList慢,所以要尽量避免使用。 * 在各种Sets中,HashSet通常优于TreeSet(插入、查找)。只有当需要产生一个经过排序的序列,才用TreeSet。 TreeSet存在的唯一理由:能够维护其内元素的排序状态。 * 在各种Maps中 HashMap用于快速查找。 * 当元素个数固定,用Array,因为Array效率是最高的。 结论:最常用的是ArrayList,HashSet,HashMap,Array。而且,我们也会发现一个规律,用TreeXXX都是排序的。 注意: 1、Collection没有get()方法来取得某个元素。只能通过iterator()遍历元素。 2、Set和Collection拥有一模一样的接口。 3、List,可以通过get()方法来一次取出一个元素。使用数字来选择一堆对象中的一个,get(0)...。(add/get) 4、一般使用ArrayList。用LinkedList构造堆栈stack、队列queue。 5、Map用 put(k,v) / get(k),还可以使用containsKey()/containsValue()来检查其中是否含有某个key/value。 HashMap会利用对象的hashCode来快速找到key。 * hashing 哈希码就是将对象的信息经过一些转变形成一个独一无二的int值,这个值存储在一个array中。 我们都知道所有存储结构中,array查找速度是最快的。所以,可以加速查找。 发生碰撞时,让array指向多个values。即,数组每个位置上又生成一个梿表。 6、Map中元素,可以将key序列、value序列单独抽取出来。 使用keySet()抽取key序列,将map中的所有keys生成一个Set。 使用values()抽取value序列,将map中的所有values生成一个Collection。 为什么一个生成Set,一个生成Collection?那是因为,key总是独一无二的,value允许重复。 List,Set,Map将持有对象一律视为Object型别。 Collection、List、Set、Map都是接口,不能实例化。 继承自它们的 ArrayList, Vector, HashTable, HashMap是具象class,这些才可被实例化。vector容器确切知道它所持有的对象隶属什么型别。vector不进行边界检查。 27、集合遍历: ArrayList: // 第一种遍历 for循环 System.out.println("--------for 循环-------"); for (int i = 0; i < heros.size(); i++) { Hero h = heros.get(i); System.out.println(h); } //第二种遍历,使用迭代器 System.out.println("--------使用while的iterator-------"); Iterator //从最开始的位置判断"下一个"位置是否有数据 //如果有就通过next取出来,并且把指针向下移动 //直到"下一个"位置没有数据 while(it.hasNext()){ Hero h = it.next(); System.out.println(h); } //迭代器的for写法 System.out.println("--------使用for的iterator-------"); for (Iterator Hero hero = (Hero) iterator.next(); System.out.println(hero); } // 第三种,增强型for循环 System.out.println("--------增强型for循环-------"); for (Hero h : heros) { System.out.println(h); } LinkedList:实现了双向链表结构deque,方便在头尾插、删数据。还实现了queue队列接口(FIFO先进先出) FILO(先进后出)在java中又叫stack栈 .offer()在最后添加元素,.poll取出第一个元素,.peek()查看第一个元素。 链表结构与数组结构类似(只连接前一个和后一个) HashMap:键值对,key唯一,不可重复, .put() .get() HashSet:set中的元素,不可重复 Collection和Map之间没有关系,Collection是放一个一个对象的,Map 是放键值对的 28、二叉树的三种访问形式:先序,中序,后序。 先序遍历:根节点-左子树-右子树 先序遍历:(1)访问根节点;(2)采用先序递归遍历左子树;(3)采用先序递归遍历右子树; 中序遍历:左子树-根节点-右子树 中序遍历:(1)采用中序遍历左子树;(2)访问根节点;(3)采用中序遍历右子树 后序遍历:左子树-右子树-根节点 后序遍历:(1)采用后序递归遍历左子树;(2)采用后序递归遍历右子树;(3)访问根节点; 29、反射: Class.forName;new Hero().getClass();Hero.class 通过反射机制创建对象:与传统的通过new类获取对象的方式不同。反射机制(先拿到类的类对象,通过类对象获取构造器对象,再通过构造器对象创建一个对象) String className = “character.hero”; Class cs = Class.forName(className); Constructor c = cs.getConstructor(); //通过构造器实例化 Hero h = (Hero)c.newInstance(); 通过反射机制修改对象的属性: Hero h = new Hero(); Field f1 = h.getClass().getDeclaredField(“name”); f1.set(h,”teemo”); 通过反射机制调用对象方法: Hero h = new Hero(); Method m = h.getClass().getMethod(“setName”,String.class); m.invoke(h,”gaaln“); //对h这个对象,调用这个方法。 Java反射机制的作用与优点:增加程序的灵活性,避免将程序写死在代码里。 如:struts中。请求的派发控制(当请求来到时,struts通过查询配置文件,找到该请求对应的action,并调用相应method。 30、注解: 注解中的信息通过反射来解析。 @Override方法重写 @Deprecated表示这个方法已过期 @SuppressWarnings(抑制)忽略警告信息 @SafeVarargs去除警告(当参数是可变数量的,且参数的类型是泛型) 方法必须声明为final或static,前提是开发人员确保此方法的实现中对泛型类型的参数处理不会引发类型安全问题。 @FunctionalInterface用于约定函数式接口 函数式接口:接口中只有一个抽象方法(可以包含多个默认方法或多个static方法),主要是配合Lambda表达式使用。 自定义注解使用@interface: 元注解: @Target({METHOD,TYPE}) 表示这个注解可以用用在类/接口上,还可以用在方法上 注解元素,这些注解元素就用于存放注解信息,在解析的时候获取出来 String ip(); int port() default 3306; String database(); String encoding(); String loginName(); String password(); 将数据库的相关信息由属性方式存放,改为由注解方式存放 @JDBCConfig(ip = "127.0.0.1", database = "test", encoding = "UTF-8", loginName = "root", password = "admin") public class DBUtil { static { try { Class.forName("com.mysql.jdbc.Driver"); 通过反射解析注解: 获取类的注解对象 JDBCConfig config = DBUtil.class.getAnnotation(JDBCConfig.class); 拿到注解对象,通过其方法获取各个注解元素的值 String ip = config.ip(); 拼接url String url = String.format(“jdbc:mysql://%s:%d/%s?characterEncoding=%s”,ip,port,database,encodeing) return DriverManager.getConnection(url,loginName,password); main(){Connection c = getConnection();} 注解不过是一种特殊的注释。需要解析 注解的本质:就是一个继承了Annotation接口的接口。 public @interface Override{} => public interface Override extends Annotation{} 解析一个类或方法的注解有两种形式: 注解的作用:减少xml配置工作,利用反射机制获取类结构信息;有助于增强程序的内举性
然后再从第二位和剩余的其他所有进行比较,只要比第二位小,就换到第二个位置来
比较完后,第二位就是第二小的
以此类推)
第二步: 再来一次,只不过不用比较最后一位
以此类推)
所以二维数组又叫数组的数组
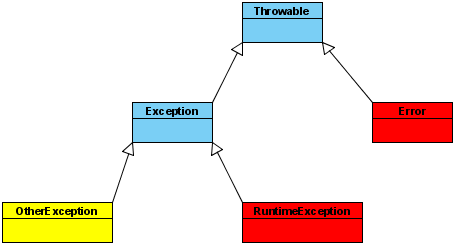
非运行时异常(编译异常): 是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException(EOFException,FileNotFoundException)异常,的SQLException等以及用户自定义的异常异常,一般情况下不自定义检查异常。
所以遍历需要用到迭代器,或者增强型for循环
HashSet是作为Map的key而存在的
@Retention(RetentionPolicy.RUNTIME) 表示这是一个运行时注解,即运行起来之后,才获取注解中的相关信息,而不像基本注解如@Override 那种不用运行,在编译时eclipse就可以进行相关工作的编译时注解。
@Inherited 表示这个注解可以被子类继承
@Documented 表示当执行javadoc的时候,本注解会生成相关文档