Tensorflow深度学习之十五:VGG16模型的简单自主实现
VGG16模型是一种十分强大的分类模型,如下是VGG模型的结构,在这里我们实现的是D列,即VGG16。
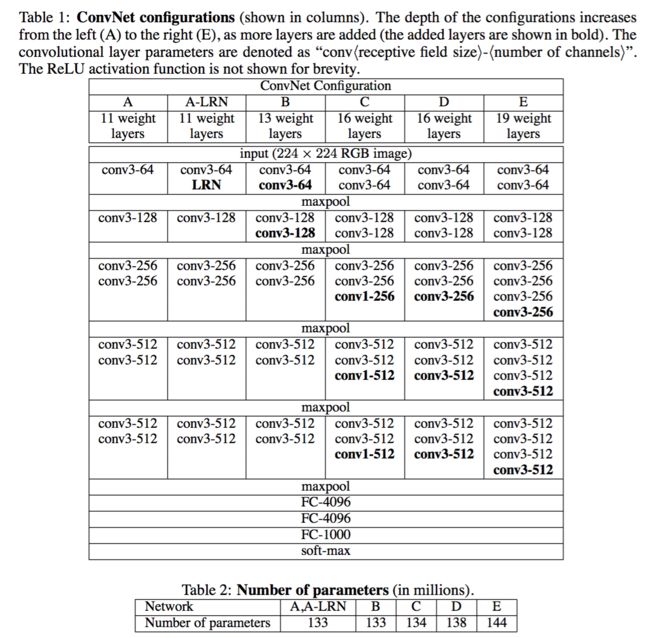
图中,conv3-64表示该层卷积核的大小为3x3,有64个卷积核,conv3-128等则以此类推。
如下是实现VGG16模型的Tensoflow代码:
(注:由于VGG16模型深度达到16层,是一种十分庞大的模型,训练十分消耗时间和计算机资源,因此,这里我们只模拟网络的构建以及随机生成一张图片进行预测。后续将会放出完整的VGG16模型进行分类的代码。)
import tensorflow as tf
# Tensorflow交互式会话
sess = tf.InteractiveSession()
with tf.device("/cpu:0"):
# 定义两个placeholder,用于输入数据
img = tf.placeholder(dtype=tf.float32,shape=[None, 224,224,3], name="input_images")
y_ = tf.placeholder(tf.float32, [2], "realLabel")
# 开始构建网络
with tf.variable_scope("conv1_1"):
kernel1_1 = tf.Variable(tf.truncated_normal([3, 3, 3, 64], mean=0.0, stddev=1.0, dtype=tf.float32))
conv1_1 = tf.nn.conv2d(img, kernel1_1, [1,1,1,1], padding="SAME", name="CONV1_1")
bias1_1 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[64], name="BIAS1_1"))
conv1_1 = tf.nn.bias_add(conv1_1, bias1_1)
conv1_1 = tf.nn.relu(conv1_1)
with tf.variable_scope("conv1_2"):
kernel1_2 = tf.Variable(tf.truncated_normal([3, 3, 64, 64], mean=0.0, stddev=1.0, dtype=tf.float32))
conv1_2 = tf.nn.conv2d(conv1_1, kernel1_2, [1,1,1,1], padding="SAME", name="CONV1_2")
bias1_2 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[64], name="BIAS1_2"))
conv1_2 = tf.nn.bias_add(conv1_2, bias1_2)
conv1_2 = tf.nn.relu(conv1_2)
maxpool1 = tf.nn.max_pool(conv1_2, [1,2,2,1],[1,2,2,1],padding="SAME",name="maxpool1")
with tf.variable_scope("conv2_1"):
kernel2_1 = tf.Variable(tf.truncated_normal([3, 3, 64, 128], mean=0.0, stddev=1.0, dtype=tf.float32))
conv2_1 = tf.nn.conv2d(maxpool1, kernel2_1, [1,1,1,1], padding="SAME", name="CONV2_1")
bias2_1 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[128], name="BIAS2_1"))
conv2_1 = tf.nn.bias_add(conv2_1, bias2_1)
conv2_1 = tf.nn.relu(conv2_1)
with tf.variable_scope("conv2_2"):
kernel2_2 = tf.Variable(tf.truncated_normal([3, 3, 128, 128], mean=0.0, stddev=1.0, dtype=tf.float32))
conv2_2 = tf.nn.conv2d(conv2_1, kernel2_2, [1,1,1,1], padding="SAME", name="CONV2_2")
bias2_2 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[128], name="BIAS2_2"))
conv2_2 = tf.nn.bias_add(conv2_2, bias2_2)
conv2_2 = tf.nn.relu(conv2_2)
maxpool2 = tf.nn.max_pool(conv2_2, [1,2,2,1],[1,2,2,1],padding="SAME",name="maxpool2")
with tf.variable_scope("conv3_1"):
kernel3_1 = tf.Variable(tf.truncated_normal([3,3,128,256], 0.0, 1.0, dtype=tf.float32))
conv3_1 = tf.nn.conv2d(maxpool2, kernel3_1, [1,1,1,1], padding="SAME", name="CONV3_1")
bias3_1 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[256], name="BIAS3_1"))
conv3_1 = tf.nn.bias_add(conv3_1, bias3_1)
conv3_1 = tf.nn.relu(conv3_1)
with tf.variable_scope("conv3_2"):
kernel3_2 = tf.Variable(tf.truncated_normal([3,3,256,256],mean=0.0, stddev=1.0,dtype=tf.float32))
conv3_2 = tf.nn.conv2d(conv3_1, kernel3_2, [1,1,1,1], padding="SAME", name="CONV3_2")
bias3_2 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[256],name="BIAS3_2"))
conv3_2 = tf.nn.bias_add(conv3_2,bias3_2)
conv3_2 = tf.nn.relu(conv3_2)
with tf.variable_scope("conv3_3"):
kernel3_3 = tf.Variable(tf.truncated_normal([3, 3, 256, 256], mean=0.0, stddev=1.0, dtype=tf.float32))
conv3_3 = tf.nn.conv2d(conv3_2, kernel3_3, [1, 1, 1, 1], padding="SAME", name="CONV3_3")
bias3_3 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[256], name="BIAS3_3"))
conv3_3 = tf.nn.bias_add(conv3_3, bias3_3)
conv3_3 = tf.nn.relu(conv3_3)
maxpool3 = tf.nn.max_pool(conv3_3, [1,2,2,1],[1,2,2,1],padding="SAME",name="maxpool3")
with tf.variable_scope("conv4_1"):
kernel4_1 = tf.Variable(tf.truncated_normal([3,3,256,512], 0.0, 1.0, dtype=tf.float32))
conv4_1 = tf.nn.conv2d(maxpool3, kernel4_1, [1,1,1,1], padding="SAME", name="CONV4_1")
bias4_1 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[512], name="BIAS4_1"))
conv4_1 = tf.nn.bias_add(conv4_1, bias4_1)
conv4_1 = tf.nn.relu(conv4_1)
with tf.variable_scope("conv4_2"):
kernel4_2 = tf.Variable(tf.truncated_normal([3,3,512,512],mean=0.0, stddev=1.0,dtype=tf.float32))
conv4_2 = tf.nn.conv2d(conv4_1, kernel4_2, [1,1,1,1], padding="SAME", name="CONV4_2")
bias4_2 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[512],name="BIAS4_2"))
conv4_2 = tf.nn.bias_add(conv4_2,bias4_2)
conv4_2 = tf.nn.relu(conv4_2)
with tf.variable_scope("conv4_3"):
kernel4_3 = tf.Variable(tf.truncated_normal([3, 3, 512, 512], mean=0.0, stddev=1.0, dtype=tf.float32))
conv4_3 = tf.nn.conv2d(conv4_2, kernel4_3, [1, 1, 1, 1], padding="SAME", name="CONV4_3")
bias4_3 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[512], name="BIAS4_3"))
conv4_3 = tf.nn.bias_add(conv4_3, bias4_3)
conv4_3 = tf.nn.relu(conv4_3)
maxpool4 = tf.nn.max_pool(conv4_3, [1,2,2,1],[1,2,2,1],padding="SAME",name="maxpool4")
with tf.variable_scope("conv5_1"):
kernel5_1 = tf.Variable(tf.truncated_normal([3,3,512,512], 0.0, 1.0, dtype=tf.float32))
conv5_1 = tf.nn.conv2d(maxpool4, kernel5_1, [1,1,1,1], padding="SAME", name="CONV5_1")
bias5_1 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[512], name="BIAS5_1"))
conv5_1 = tf.nn.bias_add(conv5_1, bias5_1)
conv5_1 = tf.nn.relu(conv5_1)
with tf.variable_scope("conv5_2"):
kernel5_2 = tf.Variable(tf.truncated_normal([3,3,512,512],mean=0.0, stddev=1.0,dtype=tf.float32))
conv5_2 = tf.nn.conv2d(conv5_1, kernel5_2, [1,1,1,1], padding="SAME", name="CONV5_2")
bias5_2 = tf.Variable(tf.constant(0.0, dtype=tf.float32,shape=[512],name="BIAS5_2"))
conv5_2 = tf.nn.bias_add(conv5_2,bias5_2)
conv5_2 = tf.nn.relu(conv5_2)
with tf.variable_scope("conv5_3"):
kernel5_3 = tf.Variable(tf.truncated_normal([3, 3, 512, 512], mean=0.0, stddev=1.0, dtype=tf.float32))
conv5_3 = tf.nn.conv2d(conv5_2, kernel5_3, [1, 1, 1, 1], padding="SAME", name="CONV5_3")
bias5_3 = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[512], name="BIAS5_3"))
conv5_3 = tf.nn.bias_add(conv5_3, bias5_3)
conv5_3 = tf.nn.relu(conv5_3)
maxpool5 = tf.nn.max_pool(conv5_3, [1,2,2,1],[1,2,2,1],padding="SAME",name="maxpool5")
shape = maxpool5.get_shape()
length = shape[1].value * shape[2].value * shape[3].value
reshape = tf.reshape(maxpool5, [-1, length], name="reshape")
with tf.variable_scope("fc6"):
fc6_weight = tf.Variable(tf.truncated_normal([25088,4096],mean=0.0, stddev=1.0, dtype=tf.float32, name="fc6_Weight"))
fc6_bias = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[4096],name="fc6_bias"))
fc6 = tf.matmul(reshape, fc6_weight)
fc6 = tf.nn.bias_add(fc6, fc6_bias)
fc6 = tf.nn.relu(fc6)
fc6_drop = tf.nn.dropout(fc6, 0.5, name="fc6_drop")
with tf.variable_scope("fc7"):
fc7_weight = tf.Variable(tf.truncated_normal([4096,4096],mean=0.0, stddev=1.0, dtype=tf.float32, name="fc7_Weight"))
fc7_bias = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[4096],name="fc7_bias"))
fc7 = tf.matmul(fc6_drop, fc7_weight)
fc7 = tf.nn.bias_add(fc7, fc7_bias)
fc7 = tf.nn.relu(fc7)
fc7_drop = tf.nn.dropout(fc7, 0.5, name="fc7_drop")
with tf.variable_scope("fc8"):
fc8_weight = tf.Variable(tf.truncated_normal([4096,1000],mean=0.0, stddev=1.0, dtype=tf.float32, name="fc8_Weight"))
fc8_bias = tf.Variable(tf.constant(0.0, dtype=tf.float32, shape=[1000],name="fc8_bias"))
fc8 = tf.matmul(fc7_drop, fc8_weight)
fc8 = tf.nn.bias_add(fc8, fc8_bias)
fc8 = tf.nn.relu(fc8)
softmax = tf.nn.softmax(fc8)
predictions = tf.argmax(softmax, 1)
# 随机生成一个数据
pic = tf.Variable(tf.truncated_normal([1, 224, 224, 3],dtype=tf.float32))
# 初始化
tf.global_variables_initializer().run()
# feed数据,运行网络
print(sess.run(softmax, feed_dict={img: pic.eval()}))运行结果如下(结果可能会有不同):
[[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]在这里,我们使用了CPU运行程序,由于本人电脑的显存有限,无法完整地在GPU运行模型。会报出如下的错误:
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[4096,4096]
[[Node: fc7/fc7_Weight/TruncatedNormal = TruncatedNormal[T=DT_INT32, dtype=DT_FLOAT, seed=0, seed2=0, _device="/job:localhost/replica:0/task:0/gpu:0"](fc7/fc7_Weight/shape)]]因此,我在这里将模型在CPU上。如果显卡较好,可以自己尝试将cpu改为gpu。