【Python】三、代码组织架构
0 序
我虽然没参加过比较大型的多人协作项目,但也独立开发过上万行的C++、Python项目,所以多少有些工程经验吧,在此不辞领教,分享下如何能开发一个结构清晰,代码易维护,鲁棒性强,功能扩展性强的工程。谈不上软件工程的理念,只是一些小问题上的代码开发技巧。
在第一节《Python基础》已经谈过代码风格规范、注释代码块、文档测试,都是项目开发维护很实用的技能,本篇不再重复阐述。
1 import与代码结构组织
1.1 包、模块命名
包(package)是指目录,导入包的时候实际是导入目录下的__init__.py文件。
模块(module)是指py文件,例如debuglib.py。由若干包和模块组成的特定功能或项目统称为“库”,Python自带可以直接引用的称为标准库(第一方库),其他组织发布的扩展,需要pip等额外安装后才能用的称为第三方库,公司内部开发的功能称为第二方库。
开发二方库时,包和模块命名必须遵循Python标识符规则。PEP8:
模块应该用简短全小写的名字,如果为了提升可读性,下划线也是可以用的。Python包名也应该使用简短全小写的名字,但不建议用下划线。
个人经验:为了避免模块名和函数名混淆,我一般会在模块名后面统一加上lib,例如debug.py改为debuglib.py。
1.2 import语法
关于Python包和模块的10个知识清单,常见导入语法:
import # 导入一个包
import # 导入一个模块
from import # 从一个包中导入模块/子包/对象
from import 还可以在后缀添加as ...取别名简化引用,如:import pandas as pd。
PEP8推荐以下导入顺序,并在每组之间插入一个空行:
- 标准库的导入
- 相关的第三方库导入
- 特定的本地应用/库导入
关于本地库的导入,Google开源项目风格指南推荐使用模块的全路径名来导入每个模块(使用这种全路径名做项目时,一定要注意1.5要讲到的"import时的加载顺序"问题,一般不在__init__.py写功能或者导包操作。):
# Reference in code with complete name.
import sound.effects.echo
# Reference in code with just module name (preferred).
from sound.effects import echo
为了使用完整路径,需要将库配置到site-packages目录: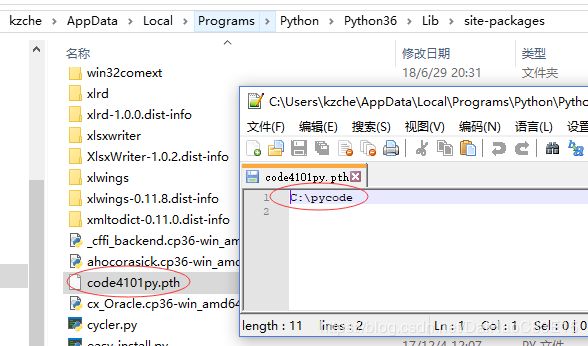
读者如果不知道要怎么写import,那么都按全路径名来写就对了,这样任何一个py文件都可以作为一个独立脚本文件来运行、测试,也不会遇到IDE的一些索引跳转到定义的功能bug。还有种比较常见的写法是在库的一些内部包里使用相对引用,这种写法就无法直接将build_main.py作为一个独立脚本来运行或测试了:
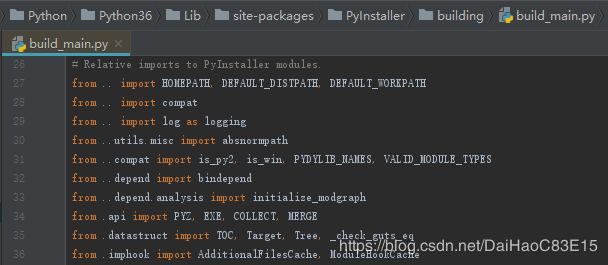
1.3 库的安装
如果希望自己的项目发送给别人时,能自动安装相关的三方库、二方库,可以参考该文:Python 打包分发工具 setuptools 简介。
还有一种比较简单粗暴的方法,是在代码中使用try语法:
import subprocess
try:
from bs4 import BeautifulSoup
except ModuleNotFoundError:
subprocess.run('pip install BeautifulSoup')
from bs4 import BeautifulSoup
1.4 if __name__ == '__main__'
__name__是当前模块名,当模块被直接运行时模块名为"__main__"。
if __name__ == 'main'的作用是让文件本身作为脚本执行的时候,能运行某些测试功能,但是作为工具模块被其他模块引用时,又不会运行多余的测试代码。
像__name__这样模块内置的变量还有__file__可以获得模块所在路径。
1.5 import时的加载顺序
做个小实验大家就明白import的时候包的加载过程了,如下pkg1、pkg2是两个目录:
pkg1
a.py
pkg2
__init__.py
b.py
main.py
四个py文件代码分别为
a.py:
print('加载 a.py')
def funca():
print('执行 funca')
print('退出 a.py')
__init__.py:
print('加载 pkg2/__init__.py')
from . import b
print('退出 pkg2/__init__.py')
b.py:
print('加载 b.py')
def funcb():
print('执行 funcb')
print('退出 b.py')
main.py:
import pkg1
try:
pkg1.a.funcb()
except AttributeError:
print('import pkg1 不能通过pkg1.a获取模块a')
print('- '*20)
import pkg1.a
# import pkg1.a ==调用时写==> pkg1.a
# from pkg1 import a ==调用时写==> a
pkg1.a.funca()
print('- '*20)
import pkg2
pkg2.b.funcb()
运行main.py得到的输出:
import pkg1 不能通过pkg1.a获取模块a
- - - - - - - - - - - - - - - - - - - -
加载 a.py
退出 a.py
执行 funca
- - - - - - - - - - - - - - - - - - - -
加载 pkg2/__init__.py
加载 b.py
退出 b.py
退出 pkg2/__init__.py
执行 funcb
简单的说,当我们使用import A.B.C.x或者from A.B.C import x等语句时,加载过程是这样的:
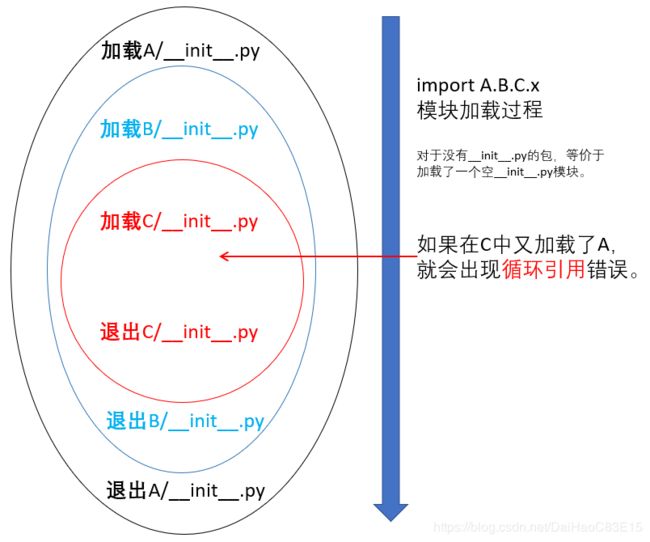
对采用"全路径名"方式进行项目模块管理的,一定要注意这个加载过程造成的影响,或者记住:一般不在__init__.py写功能或者导包操作。
在项目模块出现循环引用错误时,按照上述原理梳理一下架构,用print测一下是否加载到各个位置和顺序,一般就能解决问题了。当然最好是一开始就按照python的import规律,组织清楚代码文件依赖关系,下面就分享下我是如何架构编校组的 LaTeX \LaTeX LATEX自动化项目的。
1.6 我的代码组织形式
有些初学者喜欢开发一个"万能"文件,所有项目内部功能开发都引用它,从而配置好各种常用功能,而它也是其他项目调用这个项目的统一接口。这种设计其实是不合理的,没有区分开底层功能文件和项目对外接口文件。我的项目架构如下:
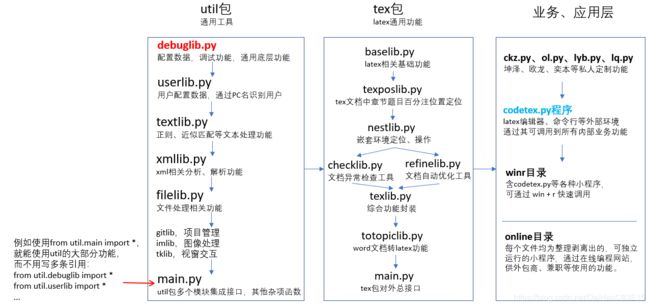
debuglib放置的是最常用到的底层功能,这些往往都是一些调试相关功能,所以称为debug模块,但并不是"纯调试功能",可能会有一些杂项功能,例如chrome()函数用浏览器来查阅表格等数据类型,所以有一个文件写入函数writefile,为了util包里各模块前后开发顺序清晰,可以适当牺牲函数在各模块的分类精确度。
但debuglib对业务层开发者是"不可见的",对业务层开发者而言,又有一个tex/main.py的统一接口,里面涵盖了util包的通用功能和tex包的latex功能。
而对于应用层,他们接触到的接口只有codetex.py程序、一些winr小程序、一些在线小工具。
总结来说,我的项目具有非常严格的文件依赖关系,开发逻辑,所以从架构上就完全避免了出现循环引用的可能,遇到各种问题也知道要归属于哪个模块文件的开发。每个项目负责人在创建项目的时候,都应该要思考清楚模块的组织分类、依赖关系。
util包不局限于编校组latex工作的功能,所以是严格遵守PEP8规范开发的,确保了以后如果需要跨工作组交流时有共同格式规范。而业务层上的代码,考虑到使用便捷性易理解,主要是编校组内部使用,大量使用中文来命名函数、变量。
附:我的项目结构图是故意设的尽可能线性比较简单。实际项目会复杂点,一般是一个AOV网。
2 函数设计经验分享
- 稍微复杂点的函数一定要写文档字符串,解释清楚每个输入参数、函数返回值的含义,。
- 可以利用动态语言特性,配合isinstance检查输入参数类型,对多种输入都能处理,参考正则库re.sub功能的第2个参数(下节会专门介绍)。
- 了解函数的参数,可变参数,关键字参数等多种形式的定义和使用。这里又涉及解包压包的语法,可以巧妙配合简化参数定义和传递:
# 例如有这么一个函数:
def func(a, arg1=None, arg2=None, arg3=None):
...
# 如果要进行封装,没必要这样写:
def func1(a, arg1=None, arg2=None, arg3=None):
...
func(a, arg1=arg1, arg2=arg2, arg3=arg3)
...
# 可以这样简化:
def func2(a, **kwargs):
...
func(a, **kwargs)
...
- 函数返回值要保留原始数据格式,能保留list等原始类型的尽量保留,有生成字符串格式的尽量返回字符串格式而不是在函数里直接print。格式越原始,以后能进行的扩展性越强,至于因此带来的使用繁琐问题,可以通过装饰器等函数优化。
上节讲到debuglib.py模块,
这里继续扩展一些debuglib.py中的相关函数功能,并结合这些实例解释上述经验。
对任意返回值类型的函数,添加装饰器StrDecorator,就能将返回值统一为字符串了。
不过普通的str()转换函数格式比较单调,我们可以开发一个prettifystr函数:
def prettifystr(s):
"""对一个对象用更友好的方式字符串化
:param s: 输入类型不做限制,会将其以友好的形式格式化
:return: 格式化后的字符串
"""
title = ''
if isinstance(s, str):
pass
elif isinstance(s, collections.Counter): # Counter要按照出现频率显示
s = s.most_common()
title = f'collections.Counter长度:{len(s)}\n'
df = pd.DataFrame.from_records(s, columns=['value', 'count'])
s = dataframe_str(df)
elif isinstance(s, (list, tuple)):
title = f'{brieftype(s)}长度:{len(s)}\n'
s = pprint.pformat(s)
elif isinstance(s, (dict, set)):
title = f'{brieftype(s)}长度:{len(s)}\n'
s = pprint.pformat(s)
else: # 其他的采用默认的pformat
s = pprint.pformat(s)
return title + s
这里对输入参数s的类型没有限制,都能字符串化。并通过isinstance函数识别s的类型后,会有针对性地美化处理细节。对于list、dict等都是可以转为pandas的DataFrame二维表格数据形式输出,其他大部分可以用标准库pprint的pprint、pformat函数处理。
然后将实现好的prettifystr封装成装饰器PrettifyStrDecorator。
同时再加一个PrintDecorator装饰器,会直接print函数的返回值。
这样以后开发函数统一返回原始格式的变量数据,当需要美化格式输出的时候,加上两个装饰器就能修改函数功能了:
@PrintDecorator
@PrettifyStrDecorator
def func():
return Counter(['a', 'c', 'a', 'b', 'c', 'b', 'c'])
>>> s = func() # 在交互环境进行赋值后本来是不会输出的,但是PrintDecorator装饰器的原因,所以会有一个输出结果
collections.Counter长度:3
value count
0 c 3
1 a 2
2 b 2
这就是“面向切面编程”的理念。
3 类基础
Python所有的类至少都会从object继承,定义类的时候可以写class A(object):或class A:,推荐统一用后者,因为更简洁。
注意Python是支持多重继承的class Dog(Mammal, Runnable),这是Java等一些语言不具有的功能。
还有一些关键点,读者可以顺着下述关键词找相关资料学习:
(对象构造时执行)构造函数__init__、(对象被销毁时自动执行)析构函数__del__,__slots__限制实例属性可以大大提高性能,与具体对象数据无关的类方法要用装饰器@staticmethod设置为静态方法(Python有很多强大的类成员函数装饰器扩展功能)。
Python还提供了很多类内置方法,通过这些内置方法,我们可以模拟出一个list、dict、上下文等各种类功能。
关于类的设计,后几节内容中有些具体的类功能,待遇到了再展开进一步介绍。
4 设计模式
设计模式其实我也不是很懂,我就懂单例类(确保整个程序中该类只有一个实例)和略了解工厂模式。不过非常推荐做项目工程的同学一起学习:
设计模式(Design pattern)代表了最佳的实践,通常被有经验的面向对象的软件开发人员所采用。设计模式是软件开发人员在软件开发过程中面临的一般问题的解决方案。这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。
如果说我这篇文章分享的无外乎是一些小聪明,甚至有些还存在争议,那么「设计模式」就是众多软件开发人员总结出来的真正专业、系统化的技术。