python全栈开发基础知识学习——Django框架(五、ORM操作)
目录
- 一、数据库的配置
- 二、Django ORM语法
- 1.模型之间的三种关系:一对一,一对多,多对多。
- 2.模型常用的字段类型参数
- 3.Field重要参数
- 4.表(模型)的创建
- 5.单表操作
- 1.创建记录
- 2.修改记录
- 3.删除记录
- 4.查询记录
- 6.多表操作(多对多关系)
- 7.聚合查询和分组查询
- 8.F查询和Q查询
- 9.QuerySet的惰性机制
一、数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
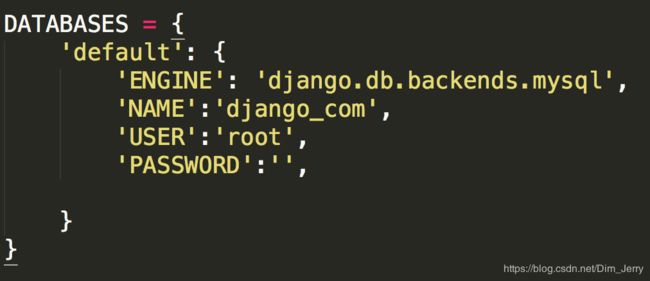
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:
二、Django ORM语法
1.模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
2.模型常用的字段类型参数
| 参数 | 描述 |
|---|---|
| CharField | 字符串字段, 用于较短的字符串.,要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. |
| IntegerField | 用于保存一个整数. |
| FloatField | 一个浮点数. 必须 提供两个参数:max_digits(总位数(不包括小数点和符号))和decimal_places(小数位数) |
| AutoField | 添加记录时它会自动增长 |
| TextField | 一个容量很大的文本字段. |
| BooleanField | 用于保存布尔值 |
| EmailField | 一个带有检查Email合法性的 CharField |
| DateField | 一个日期字段 |
| DateTimeField | 一个日期时间字段 |
| ImageField | 校验上传对象是否是一个合法图片 |
| URLField | 用于保存 URL |
具体描述:
<1> CharField
#字符串字段, 用于较短的字符串.
#CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数.
<2> IntegerField
#用于保存一个整数.
<3> FloatField
# 一个浮点数. 必须 提供两个参数:
#
# 参数 描述
# max_digits 总位数(不包括小数点和符号)
# decimal_places 小数位数
# 举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段:
#
# models.FloatField(..., max_digits=5, decimal_places=2)
# 要保存最大值一百万(小数点后保存10位)的话,你要这样定义:
#
# models.FloatField(..., max_digits=19, decimal_places=10)
# admin 用一个文本框()表示该字段保存的数据.
<4> AutoField
# 一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段;
# 自定义一个主键:my_id=models.AutoField(primary_key=True)
# 如果你不指定主键的话,系统会自动添加一个主键字段到你的 model.
<5> BooleanField
# A true/false field. admin 用 checkbox 来表示此类字段.
<6> TextField
# 一个容量很大的文本字段.
# admin 用一个